基于语音的图书资料查询接口研究
2011-11-30朱素英
朱素英
(湖南人文科技学院计算机科学技术系,湖南 娄底 417000)
基于语音的图书资料查询接口研究
朱素英
(湖南人文科技学院计算机科学技术系,湖南 娄底 417000)
使用自然语言对数据库进行操作, 有利于数据库技术的进一步推广应用。借助图书资料查询系统,我们通过对基于语音的图书资料查询汉语接口实现的关键技术研究,主要包括语音识别技术、查询分析技术、答句生成技术以及语音合成技术,介绍了图书资料查询系统中语音识别的基本框架。
查询接口;词法分析;语义分析
随着人工智能的发展和数据库技术的广泛应用,人们非常希望以一种更方便的方法去查询数据库。使用自然语言进行查询无疑是解决这一问题的有效方法。自然语言查询[1,2]是指用户只需用母语来表达查询意图,系统能自动理解用户的意图并执行相应的查询,最后用母语给出查询答案。本文主要针对图书资料查询研究了基于语音的图书资料查询自然语言接口的关键技术,包括:语音识别技术、词法分析、语义分析与答句生成技术以及语音合成技术。
语音查询是指计算机通过识别与理解语音信号,将语音信号转变为相应的文本或命令,并生成相应的查询语句,然后将查询结果用语音信号反馈给用户的过程。微软的Speech SDK为语音查询技术提供了强有力的保证。
本文基于湖南人文科技学院图书资料库的查询[3]要求,详细描述了采用微软SPEECH SDK来进行语音识别的系统框架,给出了语音查询的基本过程、基于DFA的词法分析方法和语法分析方法、查询问句到SQL查询框架的映谢,及SQL查询结果到语音回答的转换过程。本文所研究的图书资料数据库主要涉及以下几个数据表:图书信息表:描述图书的基本信息,如图书编号、书名、作者等,其中图书编号为主码;读者信息表:主要描述读者的基本信息,如读者的编号、姓名、类别等,其中读者编号为主码;操作员表:主要描述进行图书借阅的操作人员的基本信息,如操作员编号、姓名、职称等,其中编号为主码;借阅信息表:主要描述图书借出的一些基本情况,如:图书编号、读者姓名、借出日期等。
1 语音识别技术
基于语音的图书资料查询接口系统是在VC++6.0环境下开发的,操作系统是win2003,开发工具是微软公司的Mierosotf speeeh SDK[1]。MicrosotfPSeehcSDK是微软公司免费提供的语音应用开发工具包,这个SDK中包含了微软32位兼容语音应用设计接口(SAPI)、微软的连续语音识别引擎(MCSR)以及微软的语音合成(TTS)引擎等等。5.1版本一共可以支持3种语言的识别 (英语,汉语和日语)以及2种语言的合成(英语和汉语)。SAPI中还包括对于低层控制和高度适应性的直接语音管理、训练向导、事件、语法编译、资源、语音识别(SR)管理以及TTS管理等强大的设计接口。
利用微软Speech SDK 5.1在MFC中进行语音识别开发时的主要步骤(以Speech API 5.1+VC6为例):初始化COM端口 ;创建识别引擎;创建识别上下文接口;设置识别消息;设置我们感兴趣的事件;创建语法规则;在开始识别时,激活语法进行识别;获取识别消息,进行处理;释放创建的引擎、识别上下文对象、语法等。
2 查询系统设计
2.1系统查询流程
本文设计并实现了基于语音的图书资料查询汉语接口系统。该系统包括语音识别器、查询分析器(包括词法分析器、语法分析器、语义分析器)、查询执行器、答句生成器和语音合成器。其中,语音识别与合成使用微软的Mircrosft speeehSDK来实现。语音识别首先通过调用接口ISpRrcoContext,将输入的语音信号转换为汉字序列,然后基于一个从汉字到拼音的映射数据库,将汉字序列再转换为由声母、韵母和音调组成的汉语拼音序列。同音字的区分依靠后面的词法分析与语法分析技术。语音合成通过调用接口ISpvoice来实现,对形成的汉语回答“汉字串”全部采用文本语音(Text-to-Speech简称TTs)。,具体的查询流程如图1所示。

图1 语音查询系统流程图
2.2词法分析与语法分析技术
词法分析主要采用自动机DFA[4]来实现。用于分析lt;出版社名gt;的DFA片段如图2所示;用于分析各种句型的DFA片段如图3所示。其中0为开始状态。若终止状态为I,则表示成功地分析了相应词类中的第I个词汇或第I个句型。在一个DFA中,有向边上标有的汉字组成的串表示:如果碰到的是与这个汉字串对应的拼音序列,表示在DFA中实现了前后状态的转换,即成功的分析了一个词汇或一个句子。如果不能碰到与之对应的汉语拼音序列,则前后状态不能转换,或者此词汇或句型不能识别,即无解。如果在DFA中的一个非终态到达一个终态后还能到达新的终态,则后者才算真的终态,否则前者是真的终态。如果同一个拼音序列对应的汉字序列有二个或二个以上,则系统无法区分,此时查询结果就有多个,即多解的情况。

图 2 分析lt;出版社名gt;的DFA(片段)
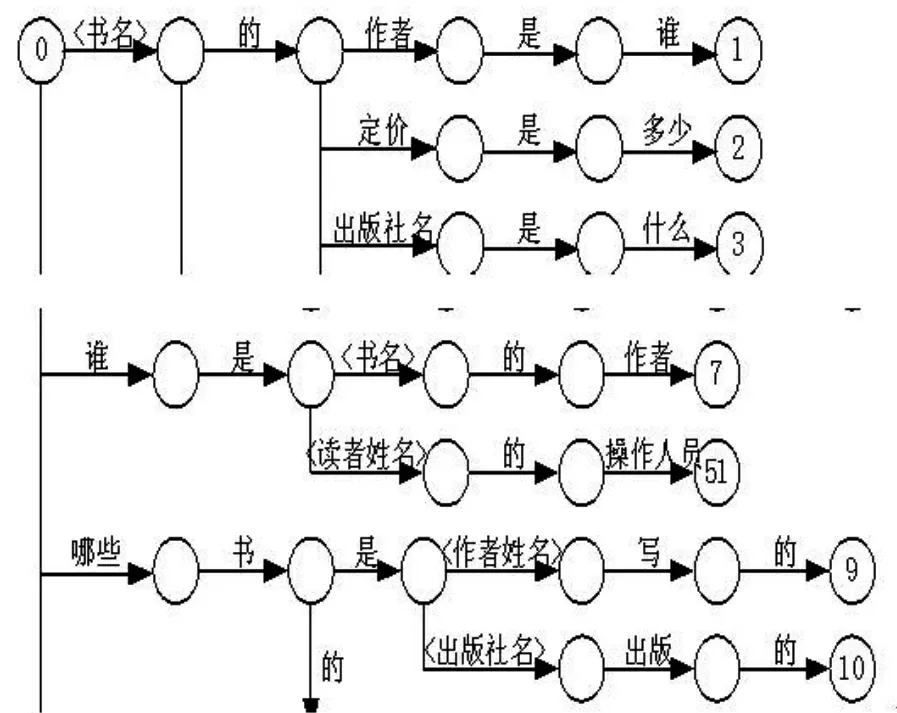
图3 分析各种句型的DFA(片段)
2.3语义分析与答句生成技术
对每个提问句型建立了一个SQL查询语句框架,如图4。在语法分析转换到终止状态I时,取出SQL查询语句框架I并将语法分析过程中对提问句型I中出现的词类名进行词法分析的结果填入该框架中,便得到可执行的SQL查询语句。执行该语句便可获得查询结果。

图4 提问句型1、9对应的SQL查询语句框架
同时,对每个提问句建立了一个基本的回答句型,如图5。为了形成语音回答,只需将查询结果回填到相应的回答句型中对应问句的疑问词“谁”或“多少”的位置。若没有查询结果返回,即无解时,则回答“未查到”。对提问句1,如果存在二本或二本以上的书名与查找书名同音时,即多解时,就会得到多个返回结果,这些书分别为不同的作者所著,则需得到多个语音的答句,一个作者对应一个语音答句,每个答句句只需将书名与对应的作者姓名填到多解时回答句型1的相应“书名”和“作者姓名”的位置。

图5提问句型1、9对应的回答句型
3 查询接口界面与测试
3.1查询接口
基于语音的图书资料查询汉语接口系统的界面设计如图6所示。界面有四个静态控件,用于界面上标题及三个text控件的说明;三个text控件,分别用来保存读入的问句,问句的拼音序列与问题的答案;二个button按钮,一个命名为“开始提问”,另一个命名为:“提交问题”。第一个button的功能是准备接收语音信号,并调用相应的函数存储接收到的语音信号;button2的功能是调用函数ISpRrcoContext将输入的语音信号转换为汉字序列,并在text1中显示出来;然后基于一个从汉字到拼音的映射数据库,将汉字序列再转换为由声母、韵母和音调组成的汉语拼音序列,在text2中显示出来;再调用相应的词法分析与语法分析函数及答句生成函数,生成SQL查询语句;再进行相应的查询,生成查询的结果,显示在text3中,最后调用ISpvoice进行文本到语音的转换,最后以语音的方式将查询结果返回给用户。
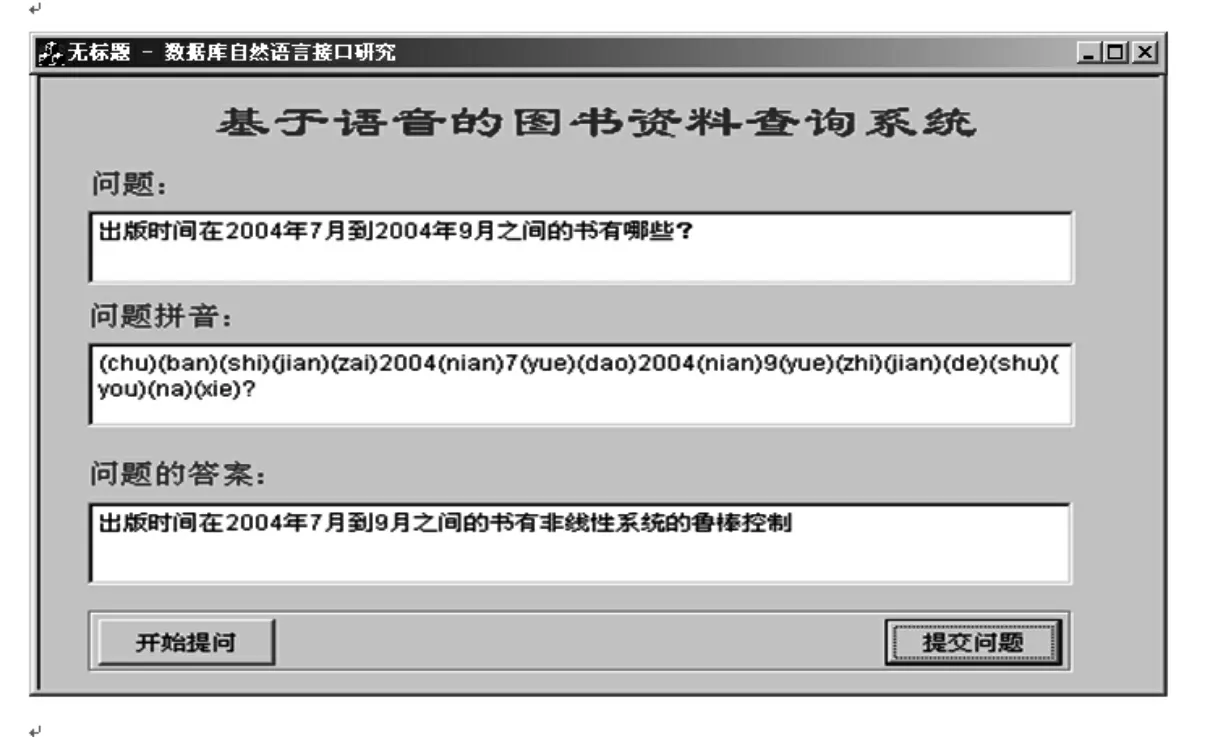
图6 查询系统界面
假设事先己安装好接口系统以及相关的文件表,并己接好麦克风,打开扬声器,启动接口系统。一旦点击系统界面上的“开始提问”按钮,后面输入的语音信号就是有效信号,同时该按钮变成“结束提问”按钮,然后系统一边输入语音信号,一边识别并将识别出来的汉字串显示在“问题”栏内,而相应的汉语拼音串显示在“问题拼音”栏内。若点击“结束提问”按钮,则系统认为当前提问输入完毕,后来输入的语音信号都是无效信号。同时“结束提问”按钮又变回“开始提问”按钮。然后,点击“提交问题”按钮,这时,系统立刻用标准音对所提问题给予回答,同时在“答案”栏内显示出回答的汉字串。
3.2系统测试
系统完成后,在一台操作系统为微软Windows2000,配置为plll500CPU、128兆内存,cyrstalcs4281PCI声卡、普通手柄式麦克风的兼容机上,对系统使用各种类型的汉语查询句进行了训练和测试,采用的数据库为湖南人文科技学院图书资料系统中数据库的部分图书信息。
图书资料查询系统是基于连续语音识别的,在投入使用前要对识别引擎进行训练。在室内环境下,以自然平和的语调逐字朗读训练文本,朗读的速度与识别引擎的速度保持一致,由于识别引擎逐渐熟悉说话人的语音模型,识别反应速度会逐渐加快,训练时间会逐渐缩短。对预先设定的3 500字左右的汉字,训练时间可由最初的每次约90分钟,经过10次左右的训练,就可以缩短为每次40分钟左右,接近人的自然朗读速度。
连续语音识别的测试分为训练集内测试和训练集外测试。训练集内测试的内容为引擎预先提供的训练文本,训练集外的测试为未包括在集内测试中的各种字段及查询语句。当识别效果不是很满意时,打开训练向导,进行几分钟的简单训练,就可以迅速改进识别效果。由于本系统的词汇量不太大,容易获得足够多的训练语音,因此,在理想的环境下,识别效果较好。
4 结束语
数据库查询是当今社会中最普遍的、应用是广泛的信息操作之一,如果能将语音应用于查询领域,则能大大的提高查询的效率。本文针对图书资料查询系统介绍了数据库语音查询接口的模型和设计思想,以及整个系统结构的工作原理和实现方法,实践表明:在受限条件下,本系统的操作能达到实用的要求。
[1]李虎.基于ontology的数据库自然语言接口研究[J],2010(6):200-205.
[2]单翼翔,张昊天.邮包校对和语音识别系统的实时实现[J].电子学报,2002,30(4):544-547.
[3]朱素英.基于语音的图书资料查询汉语接口研究[D].国防科技大学硕士学位论文,2005.
[4]陈火旺.程序设计语言编译原理:第三版[M].北京:国防工业出版社,2006:46-51.
(责任编校:光明)
ResearchonInterfaceofBooksMaterialQuestionBasedonPronunciation
ZHUSu-ying
(Department of Computer Science and Technology, Hunan Institute of Humanities, Science and Technology, Loudi 417000, China)
Using natural languages to handle database is useful to further popularize database technology. By studying the key skill of Chinese interface implementation based on pronunciation books material question, mainly including pronunciation identification, question analysis, answer generation and speech synthesis, the fundamental frame of pronunciation identification in system is introduced.
question interface; lexical analysis; semantic analysis
2011-07-08.
湖南省娄底市科技局计划项目。
朱素英(1972— ),女,湖南双峰人,湖南人文科技学院计算机科学技术系副教授,硕士,研究方向:数据库、模式识别、网络技术。
TN912.3
A
1673-0712(2011)05-0142-03
