网络数据流分析方法*
2011-11-23王培源郭唐永
罗 莎 朱 威 王培源 邹 彤 郭唐永
(中国地震局地震研究所,武汉 430071)
网络数据流分析方法*
罗 莎 朱 威 王培源 邹 彤 郭唐永
(中国地震局地震研究所,武汉 430071)
介绍网络数据流中最主要的数据流挖掘技术。
数据流;网络数据;分析;数据流挖掘;技术
1 引言
在网络安全越来越受到重视的今天,如何对网络数据进行分析,从中得到有用的信息或找到攻击线索,已成为计算机网络领域的一个新兴课题。
由于网络数据日益丰富多样,并大量地、源源不断地产生,并以数据流的形式存在,使得网络数据流(Data Stream)的处理逐渐成为当前网络与数据库领域新的研究热点。本文将详细介绍网络数据流的分析方法。
2 基于数据流的网络流量分析
在网络数据包高速到达的情况下实时地对网络数据流进行监测是极具挑战性的工作,同时对网络流量统计、监控,查询管理及异常和入侵检测等方面都具有重大的意义。当今影响网络性能的事件多具有突发性,在突发点,网络业务流量突然出现不正常的重大变化,流量值的变化范围超过了上千倍,并且增长迅速,没有任何加速过程。这种变化对网络服务和网络性能的影响势必是灾难性的。因此如何在尽可能短的时间内尽可能地准确发现这些异常并快速定位异常,采取相应措施具有非常重要的意义。而数据流分析则提供了一种行之有效的方法。
在网络流量突发异常检测中,采用数据流的方法,可以在数据高速海量特点的前提下,从网络流量中提取出有效的摘要结构,执行单遍扫描算法实时检测异常。数据流中的关键技术(数据流的管理技术和对数据流挖掘技术)和数据流相关算法(作为管理及挖掘的基础的数据摘要生成算法;主要面向管理的数据流统计查询算法;以及数据流分类、高频项挖掘、聚类、变化及异常发现等挖掘算法)可以作为网络流量突发异常检测中的研究手段,以解决实时性检测的问题[1]。
3 数据流的定性分析和多维分析
内容分析法、相关分析法、对比分析法、归纳分析法和推理分析法是网络数据分析最常用的和最基本的方法,同样可以应用于数据流的分析。
多维联机分析处理(OLAP)具有强大的分析功能,OLAP系统可以提供给用户强大的统计、分析(包括时间序列分析、非过程化建模、多维结构的随机变化等)、报表处理功能。多维分析的主要特点有:快速性、可分析性、多维性、交互性、信息性和共享性。这些特点使得OLAP系统适用于数据流这种无限量、频繁变化并需要快速的响应的数据的分析。
另外,在一个OLAP数据模型中,信息被抽象地视为一个立方体,它包括维和度量。这个多维的数据模型使终端用户提交的复杂查询、报表数据的分类排列、概要数据向详细数据的转化和过滤、数据的切片等工作变得简单。数据流的概要技术正好可以与该多维数据模型结合使用。
OLAP的功能有:对数据的多维观察;复杂的计算能力;时间智能;管理功能。其中时间智能是指OLAP系统能够很好地理解时间的序列性。而数据流是一个按照时间递增顺序排列的无穷序列,可以利用OLAP对时间的智能管理功能进行分析[2]。
4 网络数据流挖掘
挖掘技术是数据分析的关键技术,目前比较成熟并且应用较广泛的有数据挖掘技术,还有适应网络发展需要而产生的网络数据挖掘。网络数据流的分析就可以利用数据流挖掘技术。
4.1 数据流挖掘
数据流(Data Stream)是实时的、连续的、有序的项的序列,由到达时间隐含表示或显示地由时间戳制定。按照固定的次序,这些数据项只能被读取一次。因此,按照数据项到达的顺序,将数据流完整地存储到本地是不可能的[3]。
数据流的特点是:有序性、连续性、实时性;无限性;单遍性;概要性;低层次性和多维性;近似性;即时性。
数据挖掘是指从海量数据中发现一些有趣的趋势或模式,以便指导有关未来的活动的决策。数据挖掘与传统的数据分析的本质区别是数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。数据挖掘所得到的信息应具有先前未知、有效和可实用3个特征。数据流挖掘就是在数据流上发现提取隐含在其中的、人们事先不知道的、但又潜在有用的信息的过程。
4.2 数据流挖掘技术
哈尔滨焊接研究院有限公司研发中心副主任黄瑞生先生做了题目为“厚壁铝合金窄间隙激光填丝焊接技术”的报告,报告重点介绍了针对5A06铝合金大厚板焊接需求,采用激光光束以一定轨迹运动的扫描焊接方法,研究了激光束不同运动轨迹对铝合金激光深熔焊接焊缝成形及气孔的影响,在此基础上应用扫描激光填丝焊接技术焊接了130mm厚5A06铝合金,并对焊接接头组织、性能进行分析。
传统数据挖掘需要随机访问数据,应用在数据流上需要动态挖掘,即考虑流数据的实效性和动态性,数据流内在分布变化及算法单遍的限制。目前数据流挖掘技术主要有:数据流的聚类分析、数据流的分类分析和数据流的频繁模式挖掘[4]。
1)数据流的聚类分析
聚类是一种无监督学习方法。根据内间相似度最小而内部相似度最大的原则,将数据集分为若干簇。在数据流挖掘中,聚类可以看作一种数据压缩工具,它在日志分析和点击流分析中广泛应用。数据流的聚类就是通过单遍扫描数据流,持续地将数据流数据对象分组成多个类或簇,在同一个簇中的数据对象之间具有较高的相似度,而不同簇间的数据对象的相似度很小。因为数据流可看成是随时间不断变化的无限过程,其隐含的聚类可能随时间动态地变化而导致聚类质量减低。
聚类算法可以分成划分方法、基于层次的方法和基于密度的方法等几类,算法的选择取决于数据的类型、聚类的目的和应用。数据流的聚类算法不同于传统数据的聚类算法,必须是增量式的,对聚类的表示要简洁,对新数据的处理要快速,对噪音和异常数据必须是稳健的。因此,基于数据流的聚类算法要在一个相对较小的内存空间上,对数据流进行一遍扫描后,把数据集合分为一个个簇集。
Guha等人[5,6]提出流数据聚类算法 STREAM算法是对完整数据流的聚类算法,它忽略了流数据是随时间演化的,以及在不同的时间所呈现的模式不同。Babcock等人[7]提出了在固定尺寸的时间窗内的聚类算法,算法所解决的是如何在一个有限的时间窗内对流数据进行有效聚类,由于流数据是海量的,而算法所能分析的时间窗内的数据是有限的,不能对历史的数据聚类。Aggarwal等人[8]提出一个数据流的聚类演化框架Glustream,在这个框架中,将数据流的聚类分成在线微聚类与离线宏聚类两个阶段,微聚类在线统计流数据的类信息,离线宏聚类利用存储的快照来进行聚类,该算法实现近期数据的聚类,同时实现了用户指定时间段的聚类。
2)数据流的分类分析
分类是一种有监督的学习方法。数据流上的分类就是提出一个分类模型,并通过单遍扫描数据流,持续地利用分类模型将数据对象影射到某一个给定的类别中。
针对数据流的分类,Domingos等人[9]提出了一种高效的增量决策树算法——VFDT(Very Fast Decision Tree)。VFDT能用固定的内存和固定的时间为每个样本构建一棵决策树,有效地解决了时间、内存和样本对高速数据流上的数据挖掘的限制。它利用Hoeffding边界来保证算法的输出模型与批量学习(batchlearner)的输出模型是趋向于一致的。
3)数据流的频繁模式挖掘[11]
数据流频繁模式挖掘方法是要挖掘近似的频繁模式。在数据流上挖频繁模式是具有挑战性的,因为挖掘频繁项集是必须的,但关联是一个典型的块操作,例如,任何一个项集的计算在没有过去和将来数据的集时是不完全的。既然我们只能保持一个有限窗口中的数据,在动态环境下挖掘和更新频繁模式是有难度的。Giannella等人[12]用 FP-tree(Frequent Pattern tree)为数据结构,并在此基础上提出了FP-Stream算法。该算法采用倾斜时间窗口技术来维护频繁模式以解决数据流频繁模式挖掘中的时问敏感问题。
FP-stream结构包括两部分:一个用来捕获频繁和准频繁项信息的频繁模式树(FP-tree)和为每个频繁模式提供的倾斜时间窗口(tilted-time window)表。
4.3 K-means算法原理
聚类分析是数据挖掘的一个重要分支,针对数据流的聚类分析已经成为了当今知识发现与数据挖掘领域中的一个重要的研究热点。K-means算法是典型的数据流聚类算法,其原理如下:
K-means算法是建立在欧式距离基础上的滑动窗口内样本序列x=(x0,x1,…,xw-1)与y=(y0,y1,…,yw-1)之间的欧式距离为
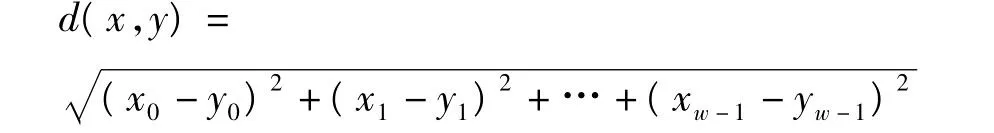
在该算法中,每个簇(类)用该簇中对象(样本)的平均值来表示,使所有对象到聚类中心的距离平方和最小。K-means的算法过程如下:
输入:聚类个数k,以及包含n个数据对象的样本集。
输出:满足方差最小标准的k个聚类。
处理流程:
1)从n个数据对象中任意选择k个对象作为初始聚类中心;
2)循环下述流程3)到4),直到每个聚类不再发生变化为止;
3)根据每个聚类中所有对象的均值(中心对象),计算样本集中每个对象与这些中心对象的距离,并根据最小距离重新对相应对象进行划分;
4)重新计算每个(有变化)聚类的均值(中心对象)。
K-means算法的特点是收敛速度较快,因此能够适应流数据在算法时间效率上的严格要求。
5 数据流挖掘研究展望
基于目前数据流挖掘的研究现状,以下方面的研究将得到更多的关注:
1)数据流连续挖掘。数据流的连续、实时、无限制的特性决定了数据流的查询是基于连续查询或长期查询。但在分析和挖掘数据流时,算法只能对数据流进行单遍扫描,仅能临时存储少量的数据,因此需要提出新的内存驻留算法来实现对数据的连续查询。支持数据流上的连续挖掘的算法通常需满足3个条件,即基于内存、快速和能够适应概念转移。当前有关算法的研究大多是在传统的增量式数据挖掘技术基础之上发展而来,因此,提出更有效的数据流连续、快速挖掘算法成为当前数据流挖掘技术的一个研究热点问题[13]。
2)半结构化文档挖掘由于网络的大范围使用,大量的数据被转换成电子格式放在网上,但是这些数据并不是以一种同样的格式存在,有些数据是完全无结构的,如声音、图像;有些数据又有严格的结构,例如数学模型、关系数据库中的数据;而更多的数据是介于两者之间,有结构但不严格,我们称之为半结构化的数据。当前绝大多数信息是以半结构化形式存在的,目前研究主要解决的问题是在已有的半结构化状态下如何有效的利用这些信息。但是由于信息以半结构化形式存在,因此,文档中的语义信息残缺不全,如何有效的提取文档中蕴含的语义信息以及如何提取其中的数据成为当前研究的一个难点。
1 陈婷婷.基于数据流的网络流量突发异常检测[D].哈尔滨工业大学,2006.
2 王永利.数据流概要与数据流分析若干关键问题研究[D].东南大学,2006.
3 司开君,毛宇光.一种新的基于数据流的数据模型[J].计算机技术与发展,2007,17(1):1-4.
4 孙晓华.数据流挖掘技术研究[D].哈尔滨理工大学,2007.
5 Guha S,et al.Clustering data streams[A].In Proceedings of the Annual Symposium on Foundations of Computer Science[C].IEEE,2000.
6 Guha S,et al.Clustering data streams:Theory and practice[J].IEEE Transactions on Knowledge and Data Engineering,2003,15(3):515-528.
7 Babcock B,et al.Maintaining variance and K-medians over data streams windows[A].Proceedings of the 22nd Symposium on Principles of Database Systems[C].2003.
8 Aggarwal C,et al.A framework for clustering evolving data streams[A].Proceedings of the 29th VLDB Conference[C].Berlin,Germany,2003.
9 Yang Ying,Wu Xindong and Zhu Xingquan.Combining proactive and reactive predictions for data streams[A].Proc of KDD[C].Chicago,IL,USA,2005:710-715.
10 Domingos P and Hulten G.Mining high-speed data streams[A].Pro-ceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].Boston,USA:ACM Press,2000:71-80.
11 田玥,大规模网络数据流异常检测系统的研究与实现[D].东北大学,2005
12 Giannella C,et al.Mining frequent patterns in data streams at multiple time granularities[A].In:Data Mining:Next Generation Challenges and Future Directions[C].2004,191-212.
13 杨颖,韩忠明,杨磊,数据流的核心技术与应用发展研究综述[J].计算机应用研究,2005,11:4-7.
ANALYSIS METHODS FOR NETWORK DATA STREAM
Luo Sha,Zhu Wei,Wang Peiyuan,Zou Tong and Guo Tangyong
(Institute of Seismology,CEA,Wuhan 430071)
The analysis methods of network data stream are introduced,in which the most important part is the data stream mining technology.It has of extensive practical background and application value to research this technology.
data stream;network data;analysis;data stream mining;technology
1671-5942(2011)Supp.-0146-04
2011-04-15
罗莎,女,1985年生,硕士,主要研究方向为嵌入式数据库的应用和数据处理.E-mail:luoshayezi@163.com
TH76.3
A
