逐类组合支持向量机在致密储层判识和产能预测中的应用
2011-11-12庞河清匡建超蔡左花黄耀综
庞河清, 匡建超,2, 蔡左花, 王 众, 黄耀综
( 1. 成都理工大学 能源学院,四川 成都 610059; 2. 成都理工大学 管理科学学院,四川 成都 610059; 3. 西南油气分公司 勘探开发研究院贵阳所,贵州 贵阳 550004; 4. 胜利油田分公司 孤东采油4厂,山东 东营 257237 )
0 引言
油气井产能预测是油气经济评价的重要环节,其预测准确性对后续井网布置、合理高效开发,乃至整个油气工业投资与决策都会产生深远影响[1].然而受地下复杂地质情况的限制,即使同一油气藏相邻两井产能也不一样,加上钻井取心的困难和岩心归位的不正确,使得储层产能预测成为油气勘探开发的难点.随着油气勘探难度的增加,传统经验预测方法已难以满足实际生产需要.为了利用常规测井方法表征地下复杂的地质条件,从而与储层产能建立联系,一些学者陆续提出逐步回归[2]、模糊模式识别[3]、灰色关联[4]、动态聚类[4]等储层产能预测方法,并取得一定成效.这些方法大多基于均质地层和线性映射的假设,没有充分考虑地质条件的复杂性,难以大范围推广利用[5].近年来,随着神经网络和支持向量机等智能机器学习方法发展,使得储层产能预测由线性领域推广到非线性领域,预测精度得到提高.此外,基于算法改进及输入变量优化的复合模型的大量应用,较好地解决神经网络、支持向量机的收敛速度慢、降噪效果差等问题.
支持向量机包括支持向量分类机(SVC)和支持向量回归机(SVR)功能,目前在油气储层分类和产能预测中都有应用[5-6],但鲜见把2种功能组合起来进行储层识别及产能预测.严衍禄和安欣在光谱分析实验中发现,模型分析准确度和训练集样本的组分浓度范围有关,即样本数据的组分浓度范围越大,分类越多,模型分析准确度越低;反之,分析准确度越高[7-8].储层产能预测亦具有相同原理,模型预测效果很大程度取决于训练样本的分类级别,即分类范围越大,模型的分析准确度越低;反之,准确度越高.在支持向量分类机和支持向量回归机特点的基础上,笔者提出一种新的建模方法——逐类组合支持向量机方法(Termwise-combination Support Vector Machine,TCSVM).该建模思路是首先用支持向量分类机对样本数据进行归类,实现储层类别判识;然后根据判识结果,用支持向量回归机(SVR)按类别分别建立产能预测模型;最后对相应类别的储层进行逐类产能预测.该建模方法不仅充分考虑各数据类别范围对储层判识的干扰,改善传统支持向量回归机的预测性能,而且还与主成分分析等方法结合起来,建立主成分分析逐类组合支持向量机等复合模型,通过前期降噪、降维的属性优化作用后,提高储层判识和产能预测的准确率.
1 数学模型
1.1 基本原理
支持向量机(Support Vector Machine,SVM)是Vapink等基于统计理论和结构风险最小化原则提出来的一种新型学习机器[9-11],具有分类和回归功能.支持向量机优点:(1)用全局寻优取代局部寻优,避免神经网络的局部极值问题,从而获得最优解;(2)引入结构风险函数提高机器学习的泛化能力;(3)通过核函数取代内积运算,使得运算量大大减少,因此避免神经网络固有的“维数灾难”问题.在支持向量机的实际应用中,无论从事分类还是回归,其基本原理相同,都是应用非线性映射函数将映射到高维特征空间中;然后在高维特征空间中巧妙利用核函数取代内积运算,求解最优近似值超平面或最优拟合值超平面,实现结构风险最小化;通过构建决策函数,最终实现线性分类和线性回归.分类机的原理参考文献[11-14].
假设存在样本集S={(x1,y1),…,(xl,yl)}⊂Rn×R,要实现回归功能,首先寻找最优近似超平面,即达到‖w‖2最小化,那么满足表达式[11]
(1)
引入拉格朗日函数,求解优化问题的对偶式[12],即
(2)
对于非线性问题,应用映射函数映射到高维特征空间中,然后在高维空间中利用核函数求解最优超平面,所构建决策函数[13-14]为
(3)
式中:K(xi,xj)为核函数.目前满足mercer条件的核函数主要有:(1)线性核函数,K(x,y)=xTy;(2)多项式核函数,K(x,y)=(s(x·y)+c)d;(3)高斯径向基核函数,K(x,y)=exp(-‖x-y‖2/2σ2);(4)指数径向基核函数,K(x,y)=exp(-‖x-y‖/2σ);(5)神经网络核函数,K(x,y)=tanh[s(x·y)+c][14].
考虑高斯核函数的抗噪能力较其他核函数强及其对参数的不敏感性[15],在储层判识和产能预测时选用高斯核函数.
1.2 支持向量机模型
由于模式识别等智能机器学习与训练样本的组分浓度、类别范围有关[7-8],即样本数据的分类范围影响模型的预测效果,分类越多,模型的分析准确度越低;反之,准确度越高.所以模型TCSVM是先将检验样本SVC分类,然后分别按类别建立训练模型,最后对相应类别的检验样本进行SVR逐类预测,其实现步骤见图1.模型的回归分析准确率与前置分类正确率密切相关,因此,为了提高模型分类正确率,还需对样本数据进行降噪处理,消除数据之间的冗余信息.分别采用主成分分析、核主成分分析和粗糙集方法作为模型前置功能,实现输入变量的预处理、删除冗余信息、降低噪音等目标.
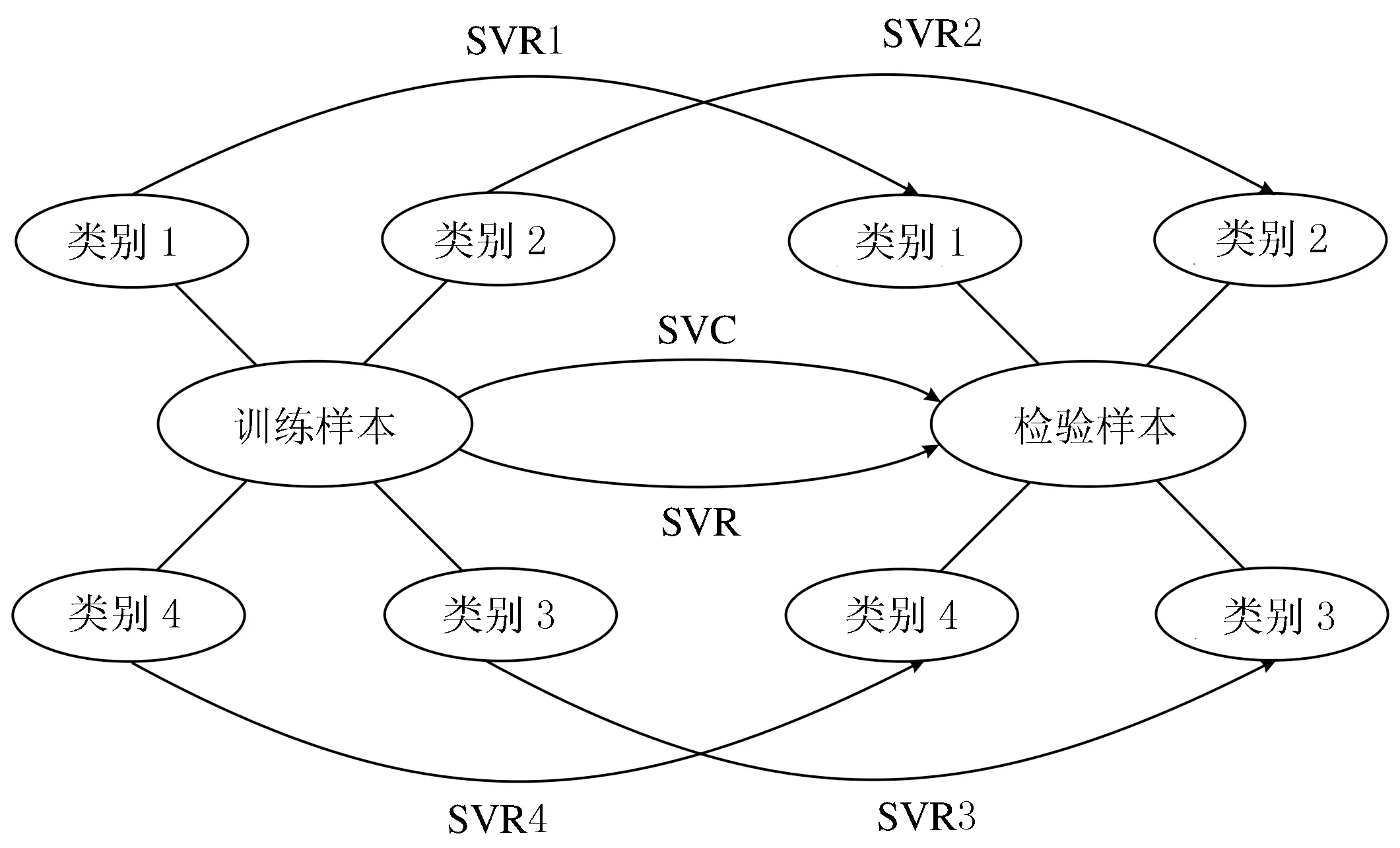
图1 逐类组合支持向量机建模思路
2 应用实例
陕甘宁中部气田位于鄂尔多斯盆地中部,在榆林、乌审旗、定边和延安之间,面积超过1×104km2[9].该气田的主力气藏马五1气藏的岩性主要有泥-细晶白云岩、细粉晶白云岩、中粗粉晶白云岩、角粒状粉晶白云岩、粉晶砂屑白云岩等.储集空间及孔隙类型有溶孔(洞)、晶间孔、粒内孔、铸模孔等.储层孔隙度岩心分析值最高为16.6%,最低的为0.14%;渗透率最高为61.955×10-3μm2,最低的为0.020 3×10-3μm2,平均为5.63×10-3μm2.受多因素影响,孔洞发育具有较强的非均质性,纵向上总体表现为由上到下储层孔洞密度升高、孔径变大、充填程度变低、充填物中黏土量减少等[16].随着气田勘探开发的进行,储层判识和气水层识别问题日益严重,给气田勘探开发的科学管理及高效开采带来危害.因此,对气藏进行储层判识及产能预测,分析主力气藏马五1储层各小层的产能纵横分布特征及气水组合关系十分必要.以该气藏19口井已测试的92个层位作为建模样本,用78个(85%)样本进行模型训练,剩下14个(15%)样本进行模型回判检验.
2.1 建模
根据长庆中部气田储层分级标准,将储层分为气层、含气层、干层、水层共4类(其中在92个已测试层位中气层35个、含气层17个、干层25个、水层15个)[17].根据研究区实际地质情况和测井相应特征,挑选10种与气水层密切相关的属性参数作为模型的输入变量,即深侧向电阻率(RLLD)、深浅双侧向电阻率幅度差(ΔR)、自然伽马(GR)、测井声波孔隙度(φs)、产能系数(Kh)、渗透率(K)、有效厚度(h)、储渗因子(Kφs)、可动水指数(RR)和介质类型因子(EE)(见表1和表2).

表1 长庆中部气田各产量区间的赋值原则
注:qg为产气量;qw为产水量.
首先将挑选的属性参数作为支持向量分类机的输入变量,实现样本数据的归类;然后按储层类别分别用支持向量回归机建立训练模型;最后对相应类别的检验样本进行逐类回归检验.为与传统方法进行比较,也用传统建模思路对储层产能进行回归分析.储层判识和产能预测是在libsvm-2.88工具箱中实现的,运用的核函数为高斯径向基核函数;而且在储层判识时约定训练样本回判率大于90%,对检验样本进行判识归类(见表3).
2.2 回判检验及对比
2.2.1 气层类别判识
使用逐类组合支持向量机模型进行产能预测时,前期归类正确与否直接影响回归预测的准确率.因此,为了提高储层判识的吻合度,分别尝试使用主成分分析支持向量机模型(PCA-SVM)、核主成分分析支持向量机模型(KPCA-SVM)、粗糙集支持向量机模型(RS-SVM)、支持向量机模型(SVM)进行储层判识.由表3可知,PCA-SVM模型和KPCA-SVM模型的分类吻合率最高,达到100%;RS-SVM和SVM的分类吻合度只有92.86%.由此说明在进行模式识别时,对样本数据进行适当预处理是必不可少的.以主成分分析与核主成分分析方法的降噪效果最好,不仅能较好地消除数据之间的冗余信息,提高运算速度,而且还保留原始数据的绝大部分信息,保证预测的吻合度.
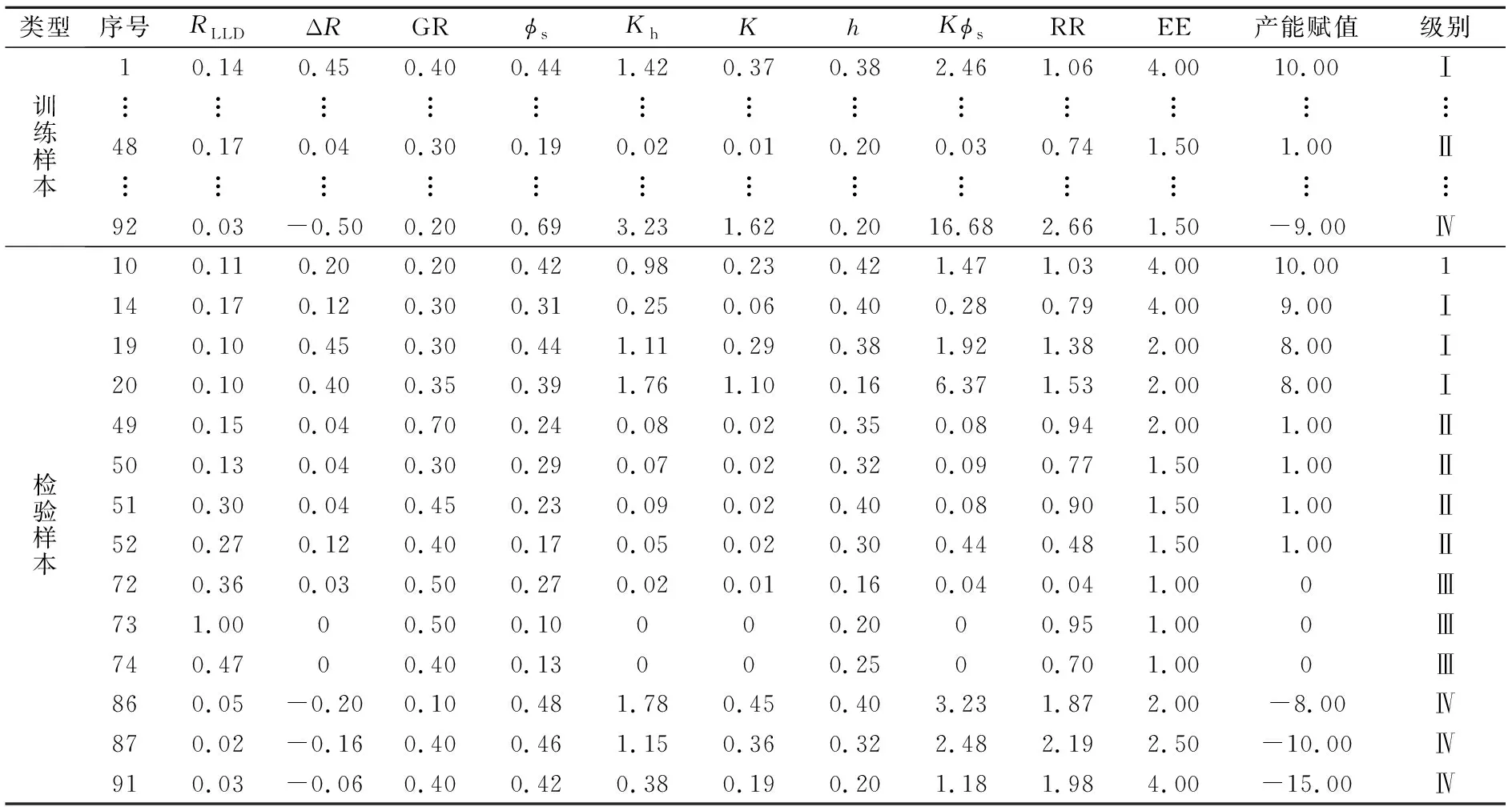
表2 样本参数输入汇总(归一化数据)

表3 回判结果
注:*表示识别有误.
2.2.2 气层产能预测
根据表3分类结果,用逐类组合支持向量机方法按类别分别进行逐类储层产能预测.同时,分别用传统支持向量机模型进行储层产能预测(见表4和表5).由表3-5可知,逐类组合模型的平均绝对误差和平均相对误差都比传统的建模方法小.在逐类组合模型中尤以PCA-TCSVM模型的误差最低(平均绝对误差为0.359,平均相对误差为0.036),KPCA-TCSVM模型次之(平均绝对误差为0.417,平均相对误差为0.041).这表明,逐类组合模型预测效果的优劣取决于SVC归类的正确率,即检验样本错分率越低,模型预测效果越高;反之,模型的预测效果越低.
文献[18]用多项式自组织神经网络方法(MOSN)对文中实例作过研究(平均绝对误差为1.751,平均相对误差为0.367).传统的支持向量机方法中,只有PCA-SVM模型的预测误差(平均绝对误差为1.447,平均相对误差为0.317)较MSON的低,其他模型的误差较MSON的高.文中建模方法误差比MSON的低,其中尤以KPCA-TCSVM、PCA-TCSVM模型最为显著,其误差不仅比MOSN的要低1个数量级,而且相关因数也比MOSN的高,达到0.996,可信度最高(见表4和表5).

表4 陕甘宁马五1储层检验样本预测结果误差分析
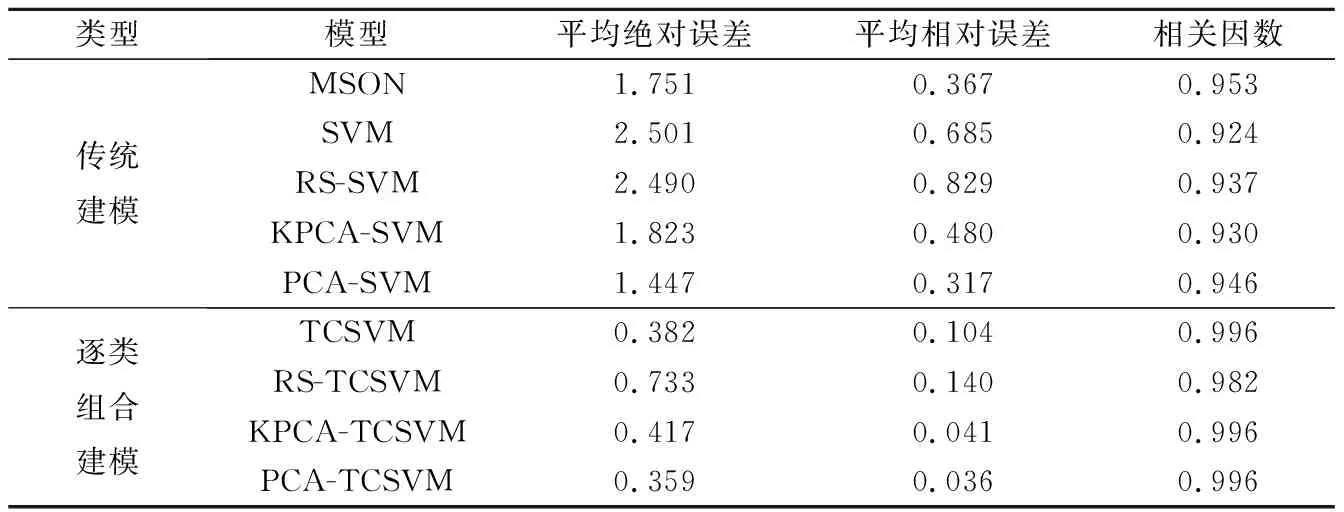
表5 不同模型预测误差
3 结论
(1)使用主成分分析、核主成分分析以及粗糙集对样本数据进行降噪,然后作为变量输入支持向量分类机,实现储层类别判识,其分类效果以PCA-SVM和KPCA-SVM模型的最好,吻合度达到100%.
(2)对储层产能预测,逐类组合支持向量机模型的预测效果较传统的支持向量机模型要好,可信度高,尤其以主成分分析支持向量机模型的应用效果最好,预测误差最低,相关因数最高.原因是先归类再预测的建模方法,指定每类模型的适用范围,从而减少其他类别样本对模型预测的干扰,提高模型预测准确率.
(3)逐类组合支持向量机模型的预测效果和前期归类的准确率息息相关,储层归类准确率越高,其相应的产能预测效果越好;反之,其产能预测效果越差.
