校园网多数据源信息检索系统的设计与实现
2011-10-20聂琰
聂 琰
(宁波大学 科学技术学院,浙江 宁波 315212)
校园网多数据源信息检索系统的设计与实现
聂 琰
(宁波大学 科学技术学院,浙江 宁波 315212)
高校校园网信息资源数量巨大,各信息发布系统的相互独立及多种异构数据源的使用对在校园网范围内进行统一的信息检索设置了障碍。系统着重解决由非结构化文本数据和结构化数据库数据形成的多数据源的集成与整合问题,在Nutch搜索引擎基础上利用Lucene接口对多种源数据建立索引,构建多数据源全文信息检索平台,从而有效地实现全网信息检索并提高检索速度和精度。
信息集成;异构数据;ODI;Nutch;Lucene
一、引言
随着校园信息化进程的不断深入,校园网上信息资源的数量迅速膨胀,各种相互独立的信息发布系统在提高效率的同时,也为校园网范围内统一的信息检索设置了障碍。校园网信息资源主要包括两类数据:一类是非结构化文本数据,以网页文件、文本文件、电子邮件等形式存储在多个信息系统当中;另一类是结构化数据,以数据记录的形式存储在不同的异构数据库之中。由于各独立信息系统间没有相互连接的渠道,快速检索校园网内部信息存在着较大困难。如何设计一个稳定而高效的架构,能够对多种信息数据源进行集成与整合,实现全网范围内全文信息检索成为校园信息化过程中一个重要研究课题。
校园网信息检索技术大体可分为三个发展阶段:第一阶段是基于数据库查询方式的结构化数据检索,应用于信息发布系统内部的检索功能,通常是通过匹配标题、作者和摘要等字段来实现信息检索。由于受到数据库性能、检索效率等因素影响,不能实现基于匹配正文内容的全文检索,因此该阶段检索方式从检索范围到检索性能及效果都并不能完全满足现阶段用户的需要;第二阶段是将基于互联网的搜索引擎技术应用于校园网,构建校园网信息检索平台。主要采用开源Lucene提供的全文检索功能和基于Lucene索引管理、存储和检索技术之上的Nutch搜索引擎技术。这两种方式能够实现对非结构化文本数据和结构化数据库数据的检索,应用在网站站内索引、企业内部文档管理及知识管理系统等多方面,对应用系统内部全文信息检索取得了较好的效果,但要实现校园网全网范围内多系统综合信息检索还有待进一步完善与改进;当前校园网信息检索技术已经发展到多系统多数据源信息检索阶段,通过多种方式将各种数据源统一建立索引进行检索,对于非结构化文本的Web页面信息采用网络爬虫方式获取数据,对于结构化文档数据源可通过Lucene接口和Nutch插件机制与第三方类库相结合来进行文档分析处理,对于数据库资源通过Lucene数据库访问接口来获取数据记录并建立索引。目前校园网信息检索平台大多是以检索功能为核心通过上述方式与多数据源集成的辐射状架构,该种架构虽可实现全网多数据源检索,但检索平台与各应用系统耦合度高,系统整体稳定性和可扩展性较差,数据安全和数据质量较低。
针对上述问题,本系统将数据采集和数据集成作为平台整体架构的基础,将Oracle数据集成工具ODI用于对多数据源结构化数据的抽取、转换和处理,从而提供一个统一的全局共享数据源,对非结构化文本数据提供对Word、PDF、PPT及XML等多种格式化文档解析的支持。以上述工作为基础,系统将分散分布、非结构化、异构的信息资源统一整合,提供给校园网用户统一的全文信息检索平台。
二、系统体系结构
多数据源校园网信息检索系统分为数据采集层和信息检索层两层体系架构,数据采集层以Oracle全局数据库为核心向下通过ODI集成各异构数据库数据,并通过网络爬虫和非结构化文本数据解析来实现多数据源数据采集,向上通过数据库接口为上层应用提供数据;信息检
索层采用以Lucene为基础的Nutch搜索引擎实现信息索引和检索。系统共包括异构数据库集成、异构文档解析、信息分类模块、信息索引模块、信息检索模块和系统管理模块六部分,系统体系结构如图1所示。

校园网信息检索技术并不是简单地将开源搜索引擎技术应用于校园网,而是针对校园网内部数据特点设计相应的解决方案。异构数据库集成模块从系统底层做好结构化数据库数据的高效获取和有效组织。校园网内信息发布以Web网站为主要方式,对其进行信息检索一是采用网络爬虫方式进行数据采集;二是通过Lucene数据库接口与各异构数据库相连采集数据,第一种方式虽然操作简单,但在数据采集质量和深度上都有所不足,并没有充分利用校园网信息数据存储的特点;第二种方式虽然在数据来源上有所改进,但在系统的稳定性、耦合程度和可扩展性上都存在不足,从各异构数据库中获取的数据无法进一步加工处理,从而导致对上层应用的支持有限。校园网内数据虽然表现为Web网页等非结构化文本形式,但其数据来源大都存储在结构化数据库中,通过获取对各业务异构数据库的查询管理权限,系统将Oracle数据集成工具ODI代替网络爬虫和数据库访问接口,从底层实现对多个异构数据库的统一管理,使系统具有更加稳定和高效的数据来源。异构文档解析模块实现对PDF、Office等文档的解析功能,通过插件机制提取各种格式化文档的文本信息进行处理。信息分类模块按照信息来源的部门、发布时间等提供分类信息检索,实现信息的高级检索功能。信息索引模块对多种数据源数据建立索引,并进行索引优化以减少索引文件的数量,并且能在搜索时减少读取索引文件的时间。信息检索模块为校园网用户提供统一的信息检索的平台,可以快速定位用户所需资源,及时有效地获取信息。系统管理模块针对不同资源,设置不同的访问权限,按照用户权限决定可以访问的资源。
三、系统主要功能模块
1.O racle 数据集成工具(ODI)
ODI(Oracle Data Integrator)是 Oracle 公司采用 ELT理念进行数据抽取、加载、转换的数据集成中间件工具,其最大特点是提出了知识模块的概念。ODI将一些场景(如文件加载到数据库,从MySQL数据库抓取数据到Oracle数据库等)的详细实现步骤使用Jython脚本语言结合数据库SQL语句录制成详细的步骤记录下来,形成知识模块,ODI中共有超过100种主流数据库引擎和应用系统的知识模块,基本上包含了普通应用所涉及的所有场景,因此ODI可以实现对校园网内多种异构数据库的支持。在一个数据集成任务中,ODI通过声明设计运用接口和关系图等概念声明数据集成规则,使集成的逻辑和技术层面分离,底层的技术方面由知识模块描述和定义,系统只需要把重点放在集成任务规则的制定上面,再将制定好的集成规则封装为一个服务模型,发布和订阅该模型便可实现类似于数据增量定时更新的功能。异构数据库集成模块示意如图2所示。
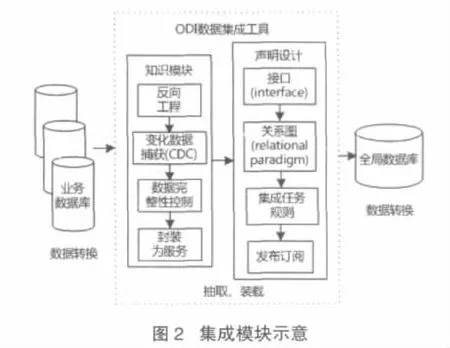
系统以全局数据库为核心通过ODI工具对校园网内异构数据库数据进行抽取、转换、清洗和加载,集成后的数据质量得到了提高,对异构数据源的处理也得到了加强。在对数据处理的过程中提取了信息的标题、作者、正文、发布时间、URL地址等字段,可定时对各异构数据库数据进行增量更新操作,从而替代利用网络爬虫获取信息数据。Oracle全局数据库可以集成校园网内大部分信息发布系统的数据并提供给信息索引和检索模块。
2.Lucene 与 Nutch
Lucene不是一个完整的搜索引擎,而是一个用于实现全文检索的软件库,采用Java语言开发,提供了检索内核,其设计原理是索引检索,任何信息资源只要被转换成文本格式都可以被检索。Nutch是Lucene得到广泛应用和认可后出现的搜索引擎系统,内部使用了Lucene的索引检索技术,并进一步封装了网络爬虫和分布式处理等模块从而成为一个完整的应用系统。本系统以Nutch为基础,既应用了Nutch系统的完整性,减少了不必要的开发,又可灵活使用Lucene接口,丰富系统功能。
对于非结构化文本信息,系统对Office文档采用了POI插件方式,用PDFBox插件来实现对PDF文档的读取,并将上述插件集成到Nutch当中。信息检索的基础是文本分析,而文本分析在很大程度上依赖于分词模块对语言的处理。Nutch自带的CJK分词模块对中文分词的效率和准确度上不能满足实际需要。为此,在对比了JE分词、Paoding分词和ICTCLAS分词等多款中文分词模块后,Paoding分词由于其开源性和良好的分词效果被本系统采用,并通过Nutch的插件机制集成到系统当中。
3.信息索引与检索
为满足用户全网检索和分类分部门检索信息的需要,并提高检索效率,信息索引模块首先对每个数据源建立索引文件提供给分类检索用户,然后通过优化索引提供给全网检索用户。优化索引就是将多个索引文件合并成单个文件的过程,目的是为了减少索引文件的数量,并且能在搜索时减少读取索引文件的时间。Nutch中的IndexWrite类提供了optimize方法实现该优化操作。利用Nutch中的MultiSearcher类可实现对优化后索引的全网检索功能,检索结果会以一种指定的顺序合并起来。
针对校园网用户信息检索的特点,综合考虑信息相关度、时效性和访问量等因素后,系统采用了自定义的排序机制,文档文本相关度作为信息检索的主要排序依据,信息发布时间和访问次数作为重要的排序因子。系统通过Lucene的激励因子boost值来改变文档得分,从而调整文档的出现顺序。系统为校园网用户提供了通用检索和高级检索功能,通用检索在用户输入检索信息的关键字后可检索出所需信息;高级检索功能为用户提供了更为详细的检索条件,用户可根据需要对信息进行更加精细的检索。系统管理功能除对用户权限进行管理外还对信息检索结果进行屏蔽和进一步处理。
四、系统运行环境
考虑到开发调试和维护的方便性,系统在测试运行期间采用了Windows平台。上层在开源Nutch搜索引擎的基础上进行开发,采用MyEclipse作为开发平台,用Java语言实现,因此具有跨平台特性。但由于运行Nutch自带的脚本命令需要Linux环境,所以必须首先安装Cygwin来模拟这种环境。为了确保Nutch1.0版本能够正确运行,Java虚拟机需采用JDK 1.6以上的版本,运用WebSphere6.0作为检索平台的容器。系统底层采用Oracle 10g作为全局数据库,数据集成工具ODI版本为10.1.3,与数据库安装在同一台服务器上。
五、结束语
校园网多数据源信息检索系统将Oracle数据集成工具ODI引入到数据采集模块,实现了对校园网内各信息发布系统后台异构数据库的有效整合与集成,改变了以往主要通过网络爬虫获取数据的方式,提高了数据来源的精度与质量,又通过Nutch插件机制实现了对非结构化文本的解析,从而为信息索引与检索打下了良好的基础。信息检索模块基于Nutch搜索引擎技术并充分利用Lucene接口实现了灵活高效的全网信息检索系统。该系统为校园网用户提供了方便快捷的信息检索平台,整合了校园网信息资源,实现了信息共享,对校园信息化建设起了很好的推进作用。
经过对系统测试运行期间性能的测试,信息检索时间和精度都得到了较大的提升,信息检索的广度和深度也有了很大提高,满足了校园网用户的需要。今后的工作是在信息检索功能的基础上进一步研究校园网舆情监测技术,完善系统功能,在提高校园信息化程度的同时为建设积极向上的校园网络文化起到较好的推动作用。
[1]王雪松.Lucene+Nutch搜索引擎[M].北京:人民邮电出版社,2008.
[2]邱哲,符滔滔,王雪松.开发自己的搜索引擎 Lucene+Heritrix[M].北京:人民邮电出版社,2010.
[3]O racle.O racle Data Integrator技术白皮书[M].北京:O racle公司,2008.
[4]王洋.O racle Data Integrator使用手册[M].北京:神州数码有限公司,2008.
[5]刘期勇.基于LUCENE的多数据源全文检索系统的设计与实现[D].重庆:重庆大学,2008.
[6]黄少林,王华,张玉红,蒋一峰.基于Lucene的索引系统的设计与实现[J].现代情报,2009,29(7):169-171.
(编辑:金冉)
G203
B
1673-8454(2011)05-0050-03
