面向俄文NLP的形态自动分析研究与实现
2011-10-15李峰易绵竹
李峰,易绵竹
(中国人民解放军外国语学院,河南洛阳471003)
1 引言
在许多自然语言处理(обработкаестественногоязыка)应用研究中 ,屈折语形态分析往往是必不可少的一个模块[1],俄文也不例外。俄语是斯拉夫语系的分支 ,属典型的屈折语(флективныйязык),其特点是语法结构严谨、语序排列随意性强,词的形态变化十分丰富。其中,俄语名词通常约有12个体现性、数、格语法意义的形式;形容词最多约有28个词形变化形式;俄语动词则更为复杂,不但有体、态、式、时、人称、数、性等语法范畴,在另一维度上还分完成体与未完成体形式。俄文形态自动分析在我国虽有个别研究,然而终因其复杂性,至今还没有一个较为成熟的应用模块。在此背景下,本文系统归纳了国内外 常见 的俄文 形态 分 析(морфологическийанализ)方法 ,深入剖析了几个具有代表意义的俄文形态自动分析器,同时在此基础上提出并运用多策略融合的方法构建了一个较为高效的俄文形态自动分析系统,以期为我国俄文自然语言处理应用研究尽绵薄之力。
2 俄文形态自动分析常见方法
近三十年来,国外许多学者在俄文形态自动分析方面做了大量的研究工作[2-10],尝试了许多不同的方法,我国傅兴尚[11]、范永明[12]等学者也曾撰文对此进行深入阐述。综合前人研究结果,可以把常见的俄文形态自动分析方法归纳为以下几种:1)基于词典的方法(декларативныйподход);2)基 于规则的方法(процедурныйподход);3)基于无词典的方法;4)多策略融合的方法。
基于词典的分析方法是较早的一种分析方法,它通过人工或半人工的方式穷举俄文单词每个可能的变化形式,并将这些可能的变化形式组成词典来进行形态自动分析。该方法的优点是形式简单技术门槛较低,且还原率高,运算速度快;不足的是俄语总共积累了大约20万词左右[13],随着社会的发展,俄语通过构词或引进外来词等方式还在不断扩大着词汇总量,即使通过许多人多年的努力能够为已有俄文词毫无差错地穷举出所有可能的变化形式,对未登录词或新词也将无能为力。
基于规则的方法主要是通过构建词干与词缀词典,通过一系列辅助的变化规则表来实现俄文词的形态自动分析[14-15]。这种方法的优点是能够一定程度上缩小词典规模,运用语言学规则进行词的形态分析;然而俄语有1000多种构词法,特殊变化词比例较高[16],因而编写这个规则库将非常耗时费力,规则库本身也将十分庞大,同时也很难避免规则间的重叠交织。在实际应用中,这种方法一方面会大大加重算法负担,另一方面当规则编写略有不周时,形态分析正确率就会迅速下降,即便对于规则变化的词,也可能会出现分析错误。例如:“-ат ь”一般会 作 为 动 词 的 词 尾 (с к а з ат ь, б е ж а т ь...), 但“к р о в а т ь”却是 名词 ,也就是 说如 果不考 虑这种 例外,将会导致分析错误。近年来在面向应用的系统研发中,这种方法多与其他方法结合使用[17-20]。
基于无词典的方法是指在形态分析中没有词形或词干等词典信息的参与,而是利用少量的语言学信息,通过一系列的统计与学习的方法进行形态自动分析。基于无词典的方法又细分为多种方法,如利用俄文词规则变化表列举一系列规则进行形态分析后去文本中验证;利用大规模的语料库进行反向统计分析后缀构成,得到词的可能形态,再用概率的方法选择最可能的分析结果等。这些无词典的分析方法在使用过程中还可能会使用词性或者上下文相关词等多种信息进行辅助判断,因方法众多,这里不再详细举例。其优势主要是不像前两种方法需要人工构建大规模的预备知识库(词形库、词干库、词缀库等),缺点是需要大规模的语料以及统计计算,又因俄语构词规则繁多,不规则变化词数目众多,在完全无词典的条件下,这种方法在速度与准确率方面很难平衡,因而较少采用,目前这种算法仅见于个别的自然语言处理系统中[11]。
多策略融合的方法,顾名思义就是使用多种策略与方法进行俄文词的形态自动分析。这种方法在争取处理速度的基础上整合多种方法的优势,力求达到一个较高的准确率。本文最终实现的俄文形态分析系统也使用了这一方法,并取得了令人满意的效果。它的优势是吸收多种方法的长处,形成一种方法上的整合优势,缺点是需要较好的算法设计以保证速度,并能够在各种优势之间取一个平衡点,以达到形态分析系统的最优性能与最高准确率。
3 知名的俄文形态分析器
俄文语言的特点决定了无论使用哪种方法进行俄文形态自动分析都需要付出艰辛的努力,尽管如此,依然有许多学者在此方面做了大量而细致的工作,取得了较高的准确率,并有一部分研究机构与个人将他们努力的成果开源共享,为俄文自然语言处理应用研究贡献了自己的力量。限于篇幅,本文主要结合俄罗斯 2010年《“文本自动分析方法评测——俄文形态自动分析”论坛》[21]参与方提供的俄文形态分析器以及其他比较知名的俄文形态分析器进行探讨,其中重点放在开源软件上。
1)AOT
俄罗斯文本自动处理(АвтоматическаяОбработкаТекста)研究组开发的 AOT 软件包主要用于俄、英、德三种语言文本的自动形态分析与处理[22]。从2002年开始该研究组开放了该软件包的源代码,任何商业组织或个人都可以在遵循LGPL协议[23]的条件下免费使用,该软件包可以在Windows等多种平台下运行,因其跨平台性及较高的准确率而具有十分广泛的知名度。
AOT主要使用基于词典与规则的方法进行形态自动分析,在俄文形态自动分析模块中其使用Злизняк词典[24]为分析依据 。 Зализняк词典包含词干、前缀、后缀以及重音等信息,其中,词干约10万条,规则集约12万条。由于本文构建的俄文形态自动分析系统将使用该词典,故此处不作过多介绍。
2)Стемка(Stemka)
Стемка[25]是由俄罗斯学者安德烈 ◦ 科瓦连科开发的一个开源的俄文形态自动分析库,2002年后加入了对乌克兰文的支持[26],该库在保留作者版权的条件下可以免费自由使用。
Стемка系统把屈折语形态分析看作是一 个机器学习的过程,该分析器使用一个经过形态分析预处理的文本语料库作为训练集(该语料集使用Ispell[27]进行预处理),在训练的过程中针对每一个词进行剖析 ,获取其不变部分 stem(Стемка系统规定stem中必须包含一个元音字母)及变化部分suffix(语料库中没有经过形态分析的词将直接被忽略),进而得到一条规则rule,该规则可表示如下:
Rule(W)→rule(stem.subString(stem.length-2,2),suffix)
例如 ,对于морями这个单词将产生规则 :
Rule(морями)→rule(-ор-,-ями)
其中ями是变化部分,op是 stem的后两个字母 。Стемка利用这种方式为每一个词产 生 一 条rule,并统计这些 rule的频率,统计结束后,低频rule将被移出,未移出的rule生成一个包含概率信息的 规则集 ,Стемка将依据 这些规则 集进行形 态分析。
值得一提的是 ,Стемка系统没有考虑俄语中许多特定的词在进行形态自动分析时可能需要多条规则的情况 ,如针对 “начинающийся”进行分析时 ,因其可发生变化的部分有 ий和ся两处 ,因而Стемка系统将无法决定在单词的何处开始自动分析。
3)其他的俄文形态分析器
除了 AOT 与Стемка外 ,其他的俄文形态分析器还有许多,如俄罗斯非商业性自组织信息研究中心(АвтономнаянекоммерческаяорганизацияЦентинформационныхисследований, АНО ЦИИ)研发的Cir_morph[28]能够对俄、英文进行自动形态分析 ,其俄文模块以 З ал и з н я к词典为基础 ,目前已经扩充到约13万词库;俄罗斯科学院信息传输问题研究所计算语言学实验室(лабораториякомпьютернойлингвистики, ИППИ РАН)研 发的 FSTMorph/Ф С ТМо р ф Ф[29],目前其形态词典规模约为 12 万条 ,并能够顺利处理数字、大小写、人名及地名等问题;著名俄文搜索引擎 Я н д е к с开发的 mystem[30]仅用于俄文形态的自动分析,对于无法使用形态词典进行分析的单词,系统会自动运用相应的算法给出可能的形态分析结果[18];其他的一些俄文形态分析器 ,如 Кросслятор[31],Libmorphrus[32],RCO Morphology[33],Ispell等,限于这些分析器主要功能并不是用于俄文形态自动分析或者属于商业系统,本文不再作详细讨论,有兴趣的读者可以查阅俄罗斯2010年《“文本自动分析方法评测——俄文形态自动分析”论坛》[21]主页了解更多信息。
4 多策略融合的俄文形态自动分析系统
4.1 系统结构与算法描述
从上文俄文形态自动分析常见方法可以看出,如果使用单一的方法构建俄文形态自动分析系统,将不可避免地存在这样或那样的不足,而使用多策略融合的方法不但能够一定程度上避免单一方法的不足,而且能够发挥多方法的整合优势。当前多数俄文形态自动分析系统都采用了融合的方法,例如:AOT 使用了基于词典与规则两种方法 ;С т е м к а使用了Ispell处理过的文本语料库生成一个规则集,然后使用这些生成的规则来进行词的形态分析;其他较为实用的俄文形态自动分析系统也很少采用单一的方法。
本文构建的俄文形态自动分析系统也不例外,采用了多策略融合的方法,其主要由词预处理层、词形词典层、规则分析层以及统计学习层四层构成,每一层都是一个独立的模块,同时这四层之间又相互影响。其中,词预处理层是各层处理的基础,词形词典层是统计学习层的训练语料,规则分析层是词形词典层的补充,统计学习层又作为词形词典层不断扩容的主要来源。
词预处理层主要由俄文常用停用词列表、常用缩略语列表以及一些浅层规则集构成。当该层接收到一个单词时,首先判断其是不是俄文单词,是不是存在于停用词列表或缩略语列表中,并运用一些规则进行词的规范化处理。鉴于停用词在俄文自然语言处理中经常被抛弃,缩略语变化形式不确定等因素,本层将直接过滤停用词与缩略语,同时对俄文单词书写进行了规范化处理,其中以处理“ё”与“е”不分现象为主。在预处理完毕后,将结果传递给下一层。
词形词典层使用一部词形词典[34]作为分析基础 ,该词典由 Зализняк词典转换而来 ,穷举了 近 9万词的所有可能变化形式,并修正了原词典中的不少错误,累计共约260余万词形。为提高处理速度,本层使用MSSQL2008企业版数据库[35]存储词典,并为相关字段建立索引,在检索过程中采用存储过程对数据库进行只读操作。当词形词典层接收到来自词预处理层传递的单词后,即进入数据库检索:查到相应的记录后,首先指向词的原形,若是形态还原则直接返回,若是形态生成,则返回整个数据行;如果没有查询到相关记录,则将词传递给规则分析层。引入本层的主要目的在于利用空间换取时间,经测试在260余万数据量时,单个词的检索时间保持在1毫秒以下。
规则分析层采用了类似 AOT 的算法 ,以 Зализняк原词典作为分析基础。本文为了获取较高的运行速度,把该词典加工为数据库存储形式,并为相关列建立索引。其算法流程为:当本层接收到传入的单词后,首先使用相似检索查询所有可能的词干,形成一个列表,其次用迭代的方法为该列表中的每个词干生成所有的词形,即若干个对应的子列表,最后再次使用一次迭代对比查找传入的单词属于哪个子列表,若查找到 ,则返回该子列表(Зализняк词典在编写过程中,保证了每一个词干生成的词形列表中第一个元素为原形,其他元素是该词的相应变化形式),若查找结果为空则将词继续传递给下一层。
统计学习层不同于 Стемка算法 ,它在接收到传入词后,首先以元音为标识进行迭代切割生成长度依次递减的子字符串,形成一个字符串列表,在切割的过程中要求列表中每个字符串元素至少包含一个元音;其次以词形词典层约260万确定的词形变化作为训练集,按顺序迭代检索与列表中字符串相似的词形,当检索返回结果不为空时停止;然后从检索结果中统计并学习形态分析规则;最后运用学习到的规则集对传入词进行形态分析。当对单个词进行分析时,如果学习到的规则条数大于1,则该层将返回各种可能的形态分析结果,并将这些结果存入本层历史数据库以待检验;当根据某条规则生成的一些词形多次作为传入词出现,并在历史数据库中命中时,即确定相应规则的有效性,此时系统根据此规则生成该词的所有变化形式,并将结果存入词形词典层,最后在移出历史数据库中对应规则及相关数据的同时更新词形词典层数据库索引。
整个形态分析处理过程如图1所示。

图1 多策略融合的俄文形态自动分析流程图
下面 本 文以 “самолеторейсов”为例 进 行 算 法描述:
首先将 “самолеторейсов”传递给词预处理层 ,经判断其属于俄文单词且不在停用词列表之中也不属于缩略语 ,接着将其标准化处理为“самолеторейсов” ,并传递给下一层。
在词形词典层,系统检索到存在词形“самолеторейсов”, 同时该词形指向其原形“самолёторейс” ,在取得“самолёторейс”对应的 ID 值后,系统再次反向顺序检索所有指向此ID值的词形,同时形成一个列表L1,在列表L1中第一个元素为原形,其他元素按相应的变化顺序排列,“самолёторейс”为名词 ,故其生成的形态列表如表1所示。在列表生成后,直接返回结果,不再进入下一层。

表1 名词“самолеторейсов”形态分析列表
为了说明算法,我们从词形词典层删除“самолёторейс”及其所有的变化形式 ,迫使程序进入规则分析层。在规则分析层,系统会首先使用字符串累加的方法生成若干个可能的词干集合P,其中P的元素个数为词长,即:

然后,使用迭代的方法对P中每一个元素执行词干与规则查找,并生成列表L2,然后再次使用迭代的方法查看 L2 中是否包含元素“самолеторейсов” ,若是则返回列表L2,停止迭代,否则立即清空L2并进入下一次迭代;如果P中所有元素迭代结束,列表L2 中依然找 不到“самолеторейсов” ,则本层形态分析失败 ,将“самолеторейсов”传递给统计学习层 。由于本层采用了类似穷举的方法,导致迭代查找次数相对较多,处理速度较词形词典层有所降低。
在统计学习层接收到“самолеторейсов”后 ,首先查阅该层历史数据库进行规则验证,若验证成功则直接返回形态分析建议或最终结果,并执行数据维护。若验证失败则首先以元音为切割点生成一个可能的变化部分列表Q,即:
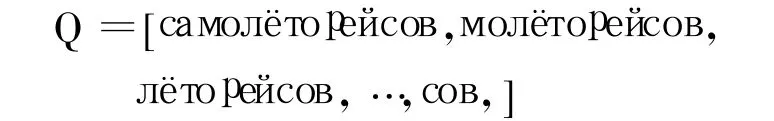
其次,使用顺序迭代的方法在词形词典层数据库里查找与Q中元素相似的词列表L3,当L3中元素个数大于0时,迭代停止。在测试过程中迭代到“р е й с о в”时 ,获取到列表L3,如表2 所示 。
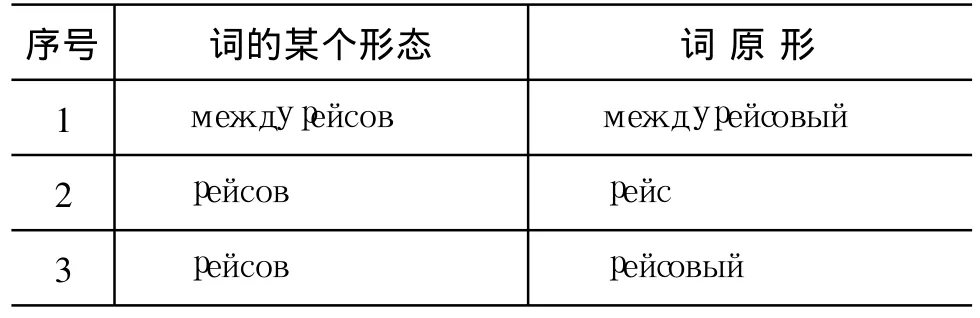
表2 以“рейсов” 结尾的词形与原形表
对表2进行统计学习,得到规则集R,即:
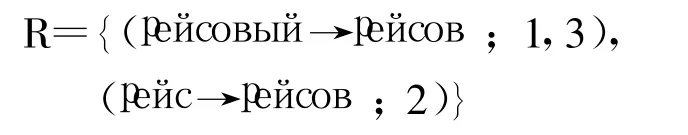
紧接着,系统会使用顺序迭代的方法使用R中的每个元素进一步生成形态规则生成规则R′,即:

其中,每条规则存在小括号之内,规则与规则之间用逗号分隔,规则内用分号分隔形态生成模式与频率。
由于本层需要进行较多的数据运算,因此单个词分析所需时长大于前三层任何一层,不过由于词形词典层及规则分析层词典词条数均在10万左右,交集在10万以上,覆盖了俄文常见词汇99.4%以上[36],故整个学习层对系统速度影响并不是很大。
4.2 实验结果统计
为了保证文本书写比较规范,实验采用了俄罗斯国防部网站新闻文本语料作为测试语料[37]。我们从收集到的24000余份文本中随机抽取10000份作为测试集,以尽可能广地覆盖俄文常用词汇。在加工分析的过程中,采用如下处理方式:
1)剔除长度等于1的俄文单词;
2)由于本系统将词的形态还原与形态生成处理为生成形态列表的方式,为减少数据运算量,只做形态还原分析;
3)经过系统分析后能够正确还原的词标记为[词的 可能 形 式 →词 的 原 形],如 [→];
4)经过系统分析后没有正确还原的词标记为|单词|,如|Каурбеку|;
5)除了缩略词列表中出现的缩略词外,将除了首字母大写外单词中依然存在至少一个大写字母的单词定义为缩略词;
6)本测试过程中,对于统计学习层返回的多个可能的形态分析结果,判为分析失败。
经运行统计后总共得到1591185个词次、73837个词形,分析结果如表3所示,其中还原成功的高频前10词如表4所示,还原失败的高频前10词如表5所示。

表3 形态还原实验最终统计结果
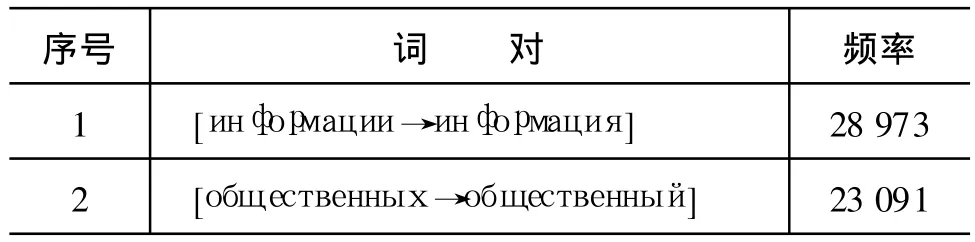
表4 还原成功的高频前10词

续表
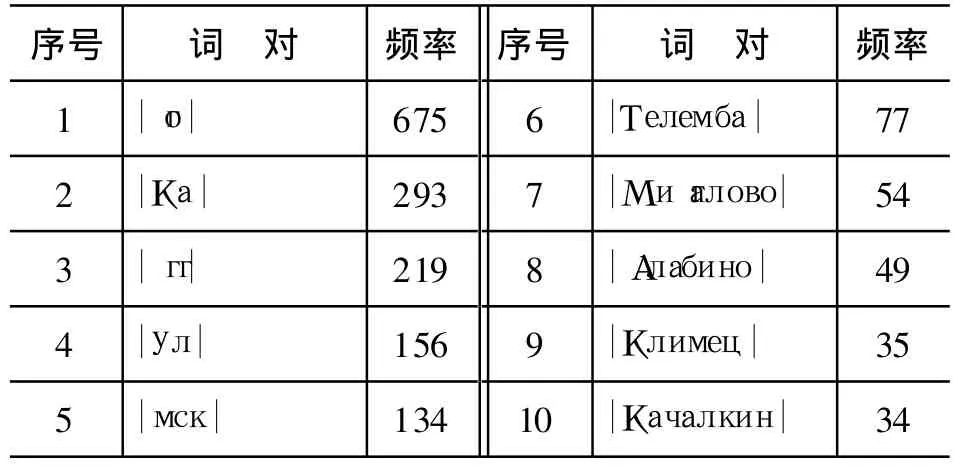
表5 还原失败的高频前10词
一般来说,在自动形态分析过程中总会伴随着两种错误的现象,即形态分析不足或过于形态分析[16]。鉴于本系统在词形词典层以及规则分析层使用了大量的确定的词典数据作为分析依据,同时由于实验涉及总词形数近8万,因而产生了众多生僻低频词,受限于作者知识水平已经无法对其做出正确与否的判定,故在统计分析中不考虑这两种现象,只是从总体上对系统所采用的算法进行评估。
4.3 实验结果分析
本系统采用的词形词典、词干与规则词典均属于常规领域,而在实验测试过程中受限于语料来源采用了俄罗斯国防部网站新闻文本作为语料,属于军事专业领域,因而形态分析正确率受到了诸如军事合成词、军事生僻词、小写缩写词、外来词、新的姓名以及错词等影响。尽管如此,本系统依然取得了形态分析97.18%的正确率,即使按词数算也达到了90.02%,比AOT算法87%的词数正确率高出约三个百分点[16]。
从处理速度方面看,系统通过引入词形词典层达到了以空间换时间的目的,即在词形词典层能够成功进行形态分析时,则立即返回结果而不需要再进入其他两层,因而速度有了大幅提升。同时,从前文算法描述中可以看出,本测试使用大型数据库存储数据,并通过其他技术手段进行调优,因而即使在大规模的数据测试中,系统依然能够保持较好的速度与性能。
最后,系统在统计学习层针对传入词进行规则学习与持续的验证,从而获取并返回词的正确分析形式,并同步更新词形词典层。这种机制的引入能够在提高准确率的同时,进一步发挥词形词典层处理速度快的优势。可以预见,随着系统的不断使用,系统的整体处理速度会越来越快,同时准确率也将不断提升。
5 结语
本文系统分析并归纳了国内外俄文形态自动分析方法,深入剖析了俄罗斯以及欧美等其他国家具有代表意义的俄文形态分析器,并在此基础上构建了一个多策略融合的俄文形态自动分析系统。系统采用分层设计的方式,在面对大规模测试集的情况下,不仅取得了较高的正确率,同时也保证了处理速度,得到了令人较为满意的效果。
受限于语料资源来源不足以及作者自身知识水平,本文没有对非专业领域文本进行大规模测试,也没有考虑俄文中合成词以及缩略语等词的形态分析。在未来作者将针对本系统做更多的测试与完善工作,同时作者也期望本文能够抛砖引玉,为面向俄文的自然语言处理应用研究尽绵薄之力。
[1]А.Ю. МУСОРИН.Основы науки о языке[ M ].Новосибирск:Новосибирское книжное издательство,2004:57-57 .
[2]Igor A.Bolshakov.A large Russian morphological vocabulary for IBM compatibles and methods of its compression[C]//Proceedings of the 13th conference on Computational linguistics,Helsinki,Finland:August 20-25,1990:p.317-317.
[3]Anciaux,Michele.Word-form Recognition and Generation:A Computational Approach to Russian Morphology[D].PhD dissertation,University of Washington:1991.
[4]Mikheev A.Automatic rule induction for unknownword guessing[J].Computational Linguistics,1997,23:405-423.
[5]John A.Goldsmith.Unsupervised learning of the morphology of a natural language[J].Computational Linguistics,2001,27(2):153-198.
[6]ЕлкинС.В., КлышинскийЭ.С., СтеклянниковС.Е.Проблемысозданияуниверсальногоморфосемантическогословаря[ M].трудов Международных конференцийIEEE AIS' 03 иCAD-2003 , том 1 , Дивноморское.2003 .
[7]ГельбухА.Ф., Сидоров Г.О. К вопросу обавтоматическомморфологическоманализефлективныхязыков[ C]// Труды Конференции Диалог-2005 :92-96 .
[8]Сидорова Е.А. Многоцелеваясловарная подсистемаизвлечения предметной лексики[ M]. Трудымеждународногосеминара Диалог' 2008 “ Компьютернаялингвистика и интеллектуальные технологии” .Россия:Наука, 2008:475-481.
[9]Клышинский Э. С. Некоторые сложностиавтоматизированной лемматизации несловарныхсловоформ[ M]. Труды международного семинараДиалог' 2009 “ Компьютерная лингвистика иинтеллектуальныетехнологии” .Россия:Наука, 2009 :165-169.
[10]Черненьков Д.М .Автоматизированноепополнениеморфологического словаря на массиве текстовыхдокументов[ M]. Труды научно-практическогосеминара “ Новыеинформационныетехнологии-12” ,Россия:МИЭМ , 2009 :138-141.
[11]傅兴尚.俄语形态信息的自动化处理——形态自动分析及其算法[J].外语学刊,2003,(3):100-105.
[12]范永明.俄语机器辅助阅读系统的词法分析原则及其实现和难点处理[J].辽宁大学学报,1999(5):319-323.
[13]赵敏善.俄汉语的本质性差异[J].中国俄语教学,1997,(3):43-46.
[14]Аношкина Ж.Г. Морфологический процессор русскогоязыка[ C]// Бюллетень машинного фонда русскогоязыка/отв.редактор В.М. Андрющенко / М.,1996, Вып.3 , с.53-57 .
[15]Саввина Г.В., Саввин И.В.Лемматизация словрусского языка в применении к распознаваниюслитнойречи[ C]// Диалог′2001.Т.2:Прикладныепроблемы.Аксаково, 2001:343-346 .
[16]М.В.Губин, А.Б.Морозов.Влияниеморфологическогоанализа на качествоинформационногопоиска[ C]//Pro ceeding s o f the RCDL 2006 .Россия.224-228 .
[17]КоваленкоА.Вероятностныйморфологическийанализаторрусского и украинского языков[ J]. Системныйадминистратор, 2002, 10(1):23-27 .
[18]Segalovich I.A Fast Morphological Algorithm with Unknown Word Guessing Induced By a Dictionary for a Web Search Engine[EB/OL].[2003-7-10].http://company.yandex.ru/articles/iseg-las-vegas.html
[19]Илья Сегалович, Михаил Маслов. Русскийморфологический анализ и синтез с генерациеймоделейсловоизменениядлянеописанныхвсловаресловКазань[ J].ООО“ Хэтер” , 1998, 9(2):547-552 .
[20]Аношкина Ж . Г. Морфологический процессоррусскогоязыка[ C]// Альманах“Говор” , Сыктывкар,1995 :17-23.
[21]Форум “ Оценка методов автоматического анализатекста:морфологические парсеры русского языка”[ EB/ OL].[ 2010-5-10].http :// ru-eval .ru .
[22]А в т о м ат и ч е с к аяО б р а б о т к а Т е к с т а[EB/OL].[2002-3-12].http://www.aot.ru/.
[23]LGPL 协 议[EB/OL].[2007-3-29].http://www.gnu.org/licenses/lgpl.html.
[24]ЗализнякА.А.Грамматический словарь русскогоязыка.Словоизменение.Около 100000 слов[ M ].Россия:“Русскийязык” , 1977 :1-880.
[25]Английский, украинскийирусскийморфологическийанализианализаторы[ EB/ OL].[ 2002-7-5].http://ling uist .nm .ru/ .
[26]Kovalenko A.Stemka:Morphological analyzer for small search systems[J].System Administrator.2002(10):57-61.
[27]Ispell[EB/OL].http://www.gnu.org/software/ispell/ispell.html.
[28]Cir_morp[EB/OL].http://uisrussia.msu.ru/docs/ips/n/cir.htm.
[29]FSTMorph/ ФСТМорфФ[EB/OL].http ://www.iitp.ru.
[30]mystem[EB/OL].http://company.yandex.ru/technology/mystem.
[31]Кросслятор[EB/OL].http://www.keldysh.ru/.
[32]Libmorphrus[EB/OL].http://www.keva.ru/.
[33]RCO Morphology[EB/OL].http://www.rco.ru/product.asp?ob_no=2871&part=docs.
[34]Russian Dictionaries and M orphology[EB/OL].http://starling.rinet.ru/
[35]MSSQL2008 数据库[OL].http://www.microsoft.com/sqlserver/2008/en/us/default.aspx.
[36]常见俄文词覆盖率列表[OL]http://www.artint.ru/projects/frqlist/analysis.txt.
[37]俄罗斯国防部分网站[EB/OL].http://www.mil.ru.
