从Web获取部分整体关系语料的方法
2011-10-15曹馨宇曹存根
曹馨宇,曹存根
(1.中国科学院计算技术研究所智能信息处理重点实验室,北京100190;2.中国科学院研究生院,北京100190)
1 引言
语义关系的获取是知识发现中的一个重要问题。目前语义关系半自动/自动获取方法主要有两种[1]:一种是基于规则的方法,该方法主要利用语言学和自然语言处理技术,通过词法分析和语法分析获取语义关系模式,然后利用模式匹配发现语义关系,利用规则验证获取的语义关系;另一种是基于统计的语义关系获取方法,该方法利用模式匹配发现语义关系,基于语料库和统计语言模型验证获取的语义关系。部分整体关系作为一种重要的语义关系,表述了实体和其部分之间一种特殊的关联,如轮胎是汽车的一部分,表示了轮胎与汽车之间存在部分整体关系。Winston等[2]认为,如果概念 p和概念w可以用形如“p是w的一部分”或其他相似的自然语言形式表示,则可以认为概念p和概念w之间存在部分整体关系。即假设不知道内存与计算机之间的关系,但如果可以获取语句“内存是计算机中最重要的部件之一”、“计算机由内存、中央处理器和硬盘等组成”等,则可以认为内存和计算机之间存在部分整体关系。
传统的部分整体关系获取大都是基于语料库的,随着互联网的迅猛发展,大量的信息以电子文档的形式出现在人们面前,Web已经成为了一种非常重要的信息资源,人们所需的知识几乎都可以在Web中检索到。因此,研究从Web中获取部分整体知识的方法越来越有必要。
要从浩瀚的Web网页中获取知识,搜索引擎是一种有效的途径。目前,诸如Google、百度等搜索引擎已经成为用户浏览和查找Web中信息不可或缺的工具。这些搜索引擎的工作原理一般是,用户输入查询关键字提出查询请求,然后搜索引擎根据用户的查询请求在网页索引库中进行检索,最后以一定的算法将检索结果排序输出,其核心是关键词匹配。由于Web信息的异构性、海量性,这种查询机制使得搜索引擎只能检索数据,而无法提供知识[3]。然而,已有工作表明,在不对检索对象本身作出改变的情况下,可以通过改变检索串,使基于语义的搜索在语言学上具有可行性[4]。例如,我们想要获取关于汽车的部分整体关系,就可以构造一些特定的查询,如“汽车的部件”、“汽车由”、“组成”等,以得到包含更多部分整体关系的网页,从而进一步进行部分整体关系的获取。这些特定的查询需要具备两个特点,一是能索引到尽可能多的富含部分整体关系的语料;二是能够指导进一步的部分整体关系的获取。这些特定查询的构造是获取部分整体关系语料的重要步骤。
本文提出了一种基于意图构造查询的方法,用于从Web获取部分整体关系语料。该方法通过在查询中加入与部分整体关系相关的语境词,利用新的查询从Web中获取部分整体关系语料。通过与人工构造查询方法和基于语料库构造查询方法对比,本文方法所获取的部分整体关系语料在部分整体关系的含量和获取难易程度两个方面都有着明显的优势。
本论文的结构如下:第2节介绍了部分整体关系获取的研究现状;第3节给出了意图查询的构造方法;第4节详细介绍了实验对比;第5节是结论。
2 相关工作
目前对于部分整体关系获取,主要有手工获取和半自动/自动获取两种方式。
手工获取部分整体关系的研究工作包括Word-Net[5]、HowNet[6]等。WordNet是一部手工建立的、基于认知语言学的、包含语义信息的英语词典。其中描述了名词概念的层次,包括同义、反义、上下位和部分整体等关系。知网(HowNet)是手工编纂的中文词汇的结构化信息库,是一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。
在自动部分整体关系获取方面,目前对于部分整体关系自动获取的研究还是主要基于模式和语料库,即从语料库中使用模式的方法获取部分整体关系。自然语言中,我们通常使用一些固定的语法结构表示某种关系[1],称这些固定的语法结构为模式。这种方法通常首先是利用模式从语料库中匹配可能包含部分整体关系的半结构化文本,再从半结构化文本中抽取部分整体关系。这些半结构化文本即本文所指部分整体关系语料。Berland等[7]利用给定的整体概念和获取到的模式,从NANC语料库中得到部分整体关系语料,使用统计方法,从语料中获取给定整体概念的部分整体关系。但由于Berland等选取的模式数量和给定的整体概念较少,故此算法得到的部分整体关系语料中部分整体关系的数量较少,因此只得到了很少的部分整体关系实例,且准确率较低。Girju等[8]给出了一种监督的,领域独立的自动发现文本中部分整体关系的方法。算法受Hearst方法启发,手工总结表示部分整体关系的模式,然后从语料库中获取部分整体关系语料,从语料中抽取潜在的蕴含部分整体关系的概念对,进而应用统计方法从中确定真正蕴含部分整体关系的概念对。以上都是针对英文的部分整体关系获取。Cao等[9]在2008年给出了一种领域独立的,从语料库中获取中文部分整体关系的方法。该方法依然使用模式的方法首先从语料库中获取部分整体关系语料,从语料中获取可能蕴含部分整体关系的候选概念对,利用启发式规则,最终得到真正蕴含部分整体关系的概念对。但由于模式的语义限制,使得获取的部分整体关系语料受限,很难获取一般概念之间的部分整体关系。从以上方法中可以看出,部分整体关系语料的获取是部分整体关系自动获取中的首要步骤,部分整体关系语料中如果含有较少的部分整体关系,则最终的获取结果就会不理想。
互联网的迅猛发展使得大量的信息以电子文档的形式出现,人们所需的知识几乎都可以在Web中检索到,因此从Web中进行知识获取成为近来知识获取的研究重点之一。Hage等[10]在2006年提出一种基于模式的从Web中获取关于给定概念的部分整体关系的方法。该方法沿用从语料库中获取部分整体关系的方法,用 Web替代语料库,利用Google搜索引擎从Web中获取表示部分整体关系的模式,使用获取的模式和人工编纂的词典,再次利用Google搜索引擎从Web中获取部分整体关系语料,再从语料中获取给定概念的部分概念。Hage方法由于利用的词典是关于食品方面的,所以只获取了关于食品领域的给定概念的部分整体关系知识,且此种方法非常依赖于词典,不能扩展到独立领域的部分整体关系的获取。从后面的实验可以看出,Hage方法中获取的查询串对于从Web中获取部分整体关系语料效果并不是很好,主要是由于搜索引擎大都采用关键词匹配技术,即在信息检索中存在词不匹配问题,使得查询串不能很好的表示我们的查询意图,从Web中获取到部分整体关系语料,从而也不能进一步从中获取部分整体关系。如何在当前的搜索引擎技术条件之下,构造合适的查询串,使得获取的部分整体关系语料中含有更丰富的部分整体关系,是从Web中获取部分整体关系的重要组成部分。
3 语料获取方法
3.1 人工构造查询方法和基于语料库构造查询方法的缺陷
从Web中获取语料的最直观的方法就是人工构造查询方法,即手工构造合适的查询串,提交搜索引擎,检索符合我们查询意图的结果。通过下面的实验分析可以看出,人工构造查询的方法虽然很直接便利,但获取的语料质量却很低。
从Web中获取语料的另一种方法是利用目前从语料库中获取的表示部分整体关系的模式,将其直接转化为查询串,从Web中获取部分整体关系语料。我们从Beland,Girju,Cao的文章中选取获取中文和英文部分整体关系的最典型模式,将其转化为查询,具体实验详见第4节。从实验中可以看出,由这种方法获取的无论是中文或是英文部分整体关系语料,其含有的部分整体关系的数量并不多,且都不易于进一步从中获取部分整体关系。同时我们也对利用Hage提出的方法从Web中获取部分整体,结果表明该方法对于Web中英文部分整体关系的获取比例为10%,即获取语料的前100条语句中有10条包含部分整体关系;但对于中文部分整体关系知识的获取比例只有6%。实验表明:
1)中文的语料有其自己的获取方法,不能直接仿照获取英文语料的方法;
2)从Web中获取部分整体关系语料,查询串的构造不能直接借用基于语料库所获取的模式;
3)从Web中获取中文的部分整体关系语料,不论是人工构造查询方法还是基于语料库构造查询的方法对于获取的结果都不理想。
基于以上分析,本文给出一种通过构造含有语境词的查询,从Web中获取关于给定概念的部分整体关系语料的方法。
3.2 基本假设和总体框架
从Web获取部分整体关系语料基于以下两个前提:
1)部分整体关系可以由其共同频繁出现的某些词体现;
2)可以用多个蕴含部分整体关系的概念对代表部分整体关系。
与部分整体关系联系紧密,可以体现部分整体关系的词,我们称为语境词。包含语境词和部分整体关系的语句片段,我们称为语境片段。由于语境词可以反映概念之间的关系,故构造带有语境词的查询串不仅可以从Web中获取富含大量部分整体关系的语料,同时可以根据查询串提供的信息进一步从获取的语料中得到部分整体关系。由于这种查询可以很好的反应我们的查询意图,在本文中将带有语境词的,基于意图的查询串称为意图查询。
本方法的主要步骤为:
步骤1:利用已知蕴含部分整体关系的概念对S和搜索引擎,从Web中获取一定长度的语境片段Occ;
步骤2:依据前提2,计算语境片段中频繁出现的词与部分整体关系的相关度,由相关度确定候选语境词CW;
步骤3:利用Web验证候选语境词,将语境词W和初始查询串提交搜索引擎,得到新的语境片段 Occ′;
步骤4:从新的语境片段中抽取意图查询Pattern,获取部分整体关系语料Corpus。
算法流程:

3.3 具体步骤
1)将已知蕴含部分整体关系的概念对(w,p),直接作为初始查询串q,提交搜索引擎,取检索结果集的Topk;
2)语境片段的获取包括以下两部分。
a)对于中文文件而言,通常一个句子表达一个相对较完整的意思[11],处于一个句子中的概念更能反映出意义上的相关性。故对查询串q返回的检索结果集的Topk文档,截取概念w和概念p所在句子,然后取句子中概念w和概念p固定长度为m的文档片段Dq为语境片段;
b)返回的网页中,搜索引擎通常会提供与查询有关的相关搜索,记检索结果中提供的相关搜索的内容为Drq;
3)对语境片段Dq和Drq分词,分别统计Dq和Drq中出现的各词的词频,由于动词和名词会表示比较明确的意义,故记Dq和Drq中出现的名词和动词的集合分别为Cq和Crq,C=Cq∪Crq;
4)取n对蕴含部分整体关系的概念对,重复1、2、3步骤,n个初始查询串组成查询集合Q;
5)计算词c(c∈Cq)与部分整体关系R的相关度。相关度高说明此词与部分整体关系联系密切。相关度的衡量基于以下两个假设:1)根据TF的计算方法,如果词c在查询串q的检索结果中出现次数较多,则词c与查询串q相关度高;2)查询同一个问题,可以构造多个查询串。词c出现在越多查询串的检索结果中,词c与这个问题越相关。在步骤1中,我们已经将已知蕴含部分整体关系的概念对转化为初始查询串,根据前提2和假设1),将相关度计算公式定义为
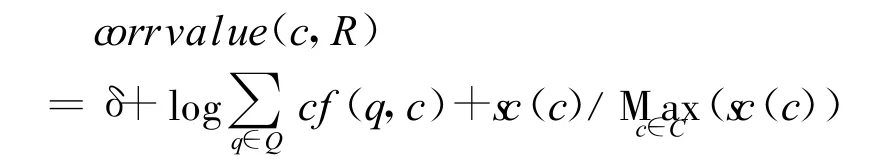
其中,cf(c,q)为查询q的检索结果中词c出现的次数,sc(c)表示与词c相关的查询串q的数目。当词c是由搜索引擎的相关搜索提供时,即c∈Crq,δ=0.1;否则 δ=0;
6)取corrvalue(c,R)值在Top10之内的词c作为候选语境词;
7)查找包含候选语境词的语境片段Dq,根据其出现的频度,确定语境词c与查询q频繁出现的形式,将其中的部分概念置为*,得到查询串 q′;将q′提交搜索引擎,如果返回的Top100检索结果中出现查询串q中的部分概念,则候选语境词c既是我们所需的语境词,查询串q′即是从Web中获取关于已知整体概念的部分整体关系的查询串。利用搜索引擎,查询串q′的检索结果即为包含已知整体概念的部分整体关系语料。我们可以从中进一步获取关于已知概念的部分整体关系。
例如,我们选取Google搜索引擎,利用本文提出的方法从Web中获取关于“汽车”的部分整体关系语料。
1)我们选取10对蕴含相同部分整体关系的概念对,例如,(计算机,硬盘)、(相机,镜头)、(飞机 ,机翼)等,分别构建初始查询串,如“计算机 硬盘”,“相机镜头”等,将其提交给Google。根据语境片段获取方法,我们得到例如“计算机硬盘技术”、“计算机硬盘维修”、“专业相机所用镜头”、“相机镜头知识”、“相机镜头清洗”和“飞机机翼的作用”、“飞机机翼结构”文档片段,通过计算相关度,共得到10个候选语境词,如技术、维修、作用等;
2)根据候选语境词在语境片段中出现的频率,选取包含高频度候选语境词的语境片段。构造查询串q′,如“相机镜头清洗”、“计算机硬盘技术”和“飞机机翼的作用”,其相应查询串q′分别为“相机*清洗”、“计算机 *技术”和“飞机 *的作用”。通过Web验证,最终得到8个语境词,分别为使用、维修、清洗、技术、原理、结构、类型、价格。同时获取查询串为:“汽车*的<!语境词>”,<!语境词>表示语境词变量,可以替换为任意一个语境词;
3)构造意图查询“汽车*的使用”OR“汽车*的维修”OR“汽车*的清洗”OR“汽车*的技术”OR“汽车*的原理”OR“汽车*的构造”OR“汽车*的类型”OR“汽车*的价格”提交Google搜索引擎,以其返回的Top100项检索结果作为语料,其中包含部分整体关系的语句共有70项,可以轻易地从语料中获取44个汽车部件,在不进行任何验证的情况下,手工检测其抽样结果的准确率为45.5%。
4 实验分析与对比
4.1 评价指标
我们从两个方面衡量语料质量:1)语料中含有部分整体关系的语句的数量;2)从语料中抽取部分整体关系的难易程度,即可以从语料中获取的部分整体关系数量。
4.2 对比试验
我们选取了100个不同的概念,例如,计算机、汽车、空调等,利用搜索引擎Google从Web中获取关于这些概念的部分整体关系语料,衡量平均一个概念获取的部分整体关系语料的质量。根据4.1节中提出的两个指标,计算获取的语料中含有部分整体关系的语句的数量和能得到的部分整体关系的数量,将本文中提出的意图查询方法与人工构造查询方法和基于语料库构造查询方法进行对比。
为了解某个概念C的部分,人们通常会构造查询“C有哪些部件”和“C的部件有哪些”。如“汽车有哪些部件”和“计算机的部件有哪些”等。表1给出了其检索结果的部分实例。
对于基于语料库构造查询方法,我们分别从Beland和Girju的文章中选取获取英文部分整体关系的最典型模式“NPXof NPY[7]”和“NNparts of NNwholes[8]”,将其转化为查询串“*of C” 、“*of the C”,在返回的Top100项中检索结果中,没有包含关于汽车的部分整体关系知识。从Cao文章中选取模式:<?c1>由<?c2><组成>,将其转化为查询“C由***组成”OR“C由****组成”OR“C由*****组成”OR“C由******组成”。其检索结果的部分实例如表2所示。
根据本文中提出的方法,可以构造查询:“C*的使用”OR“C*的维修”OR“C*的清洗”OR“C*的技术”OR“C*的原理”OR“C*的构造”OR“C*的类型”OR“C*的价格”,例如,“汽车*的价格”“汽车*的使用”“计算机*的价格”“计算机*的类型”。表3给出了检索结果的部分实例。

表1 人工构造查询方法获取的部分检索结果实例

表2 基于语料库构造查询方法获取的部分检索结果实例

续表

表3 意图查询方法获取的部分检索结果实例
根据Google的检索机制,将检索结果中匹配查询串关键词的部分标记为红字,我们用斜体黑体表示这些匹配的部分。
图1中比较三种不同方法中获取的部分整体关系语料中,含有部分整体关系语句的数量。由于人工构造查询方法获取的部分整体关系语料是一种完全非结构化的,因此不能利用查询串提供的信息自动获取其中的部分整体关系。图2对比基于语料库构造查询方法和意图查询方法获取的部分整体关系数量。
4.3 实验分析
从图1可以看出,在由返回的 Top100项、Top200项、Top300项、Top400项和 Top500项检索结果组成的部分整体关系语料中,人工构造查询方法所获取的各个语料中蕴含部分整体关系的语句数量最少,意图查询方法获取数量最多,且部分整体关系语料的规模越大,意图查询方法的优势越明显。

图1 三种不同方法获取的语料中含有部分整体关系的语句的数量

图2 基于语料库构造查询方法和意图查询方法获取的部分整体关系数量
在部分整体关系抽取难易方面,通过表1、表2和表3显示的三种方法各自获取的语料部分实例可以看出,人工构造查询方法获取的部分整体关系语料中,虽然包含了关于给定概念的部分整体关系,但其所在文本结构复杂,很难从中抽取部分整体关系,而且通常需要具备某些基础知识,才能判定语料中是否包括了部分整体关系。例如第三个实例中,需要知道“电脑”和“计算机”之间的关系以及“心脏”的含义。只单纯利用查询串提供的信息,不可能进一步从获取的语料中得到关于给定概念的部分整体关系;对于基于语料库构造查询方法,虽然通过查询串提供的信息可以从获取的语料中抽取关于给定概念的部分整体关系,抽取的部分概念也符合查询的本意,但得到的部分整体关系比较单一,即部分整体关系数量较少;通过表3所显示的本文所提意图查询方法获取的部分整体关系语料部分实例中可以看出,对于这种语料,我们能很容易的利用查询串本身提供的信息,从中抽取出符合我们查询本意的部分整体关系。通过图2中的实验数据可以看出,对比基于语料库构造查询方法,意图查询方法从获取的部分整体关系语料中可以多获取大约两倍的部分整体关系。
5 结束语
目前人们使用搜索引擎作为从Web获取知识的有效手段,但网上绝大多数搜索引擎都使用基于关键词匹配的全文检索技术,不支持语义搜索。因为不易对检索对象本身做出处理[4],我们只能对查询串本身做出某些改变,使其接近我们需要的语义。故本文提出了一种新的用于从Web获取部分整体关系语料的基于意图的查询构造方法即意图查询方法。在查询中加入与部分整体相关度高的语境词,构造新的查询,从Web中检索富含部分整体关系的网页,即部分整体关系语料。通过与人工构造查询方法和基于语料库构造查询方法对比实验表明,在分别由返回的Top100项、Top200项、Top300项、Top400项和Top500项检索结果构成的语料中,本方法可以获取更多的蕴含给定概念部分整体关系的语句,且容易进一步从中获取部分整体关系。本方法获取的部分整体关系数量远多于基于语料库构造查询方法。
[1]Marti A.Hearst,Automatic Acquisition of hyponyms from large text corpora[C]//Proceedings of the 14th International Conference on Computational Linguistics,1992,539-545.
[2]Morton E.Winston,Roger Chaffin,and Douglas Hermann.A taxonomy of part-whole relations[J].Cognitive Science,1987,417-444.
[3]张森,王斌.Web检索查询意图分类技术综述[J].中文信息学报,2008,22(4):75-82.
[4]袁毓林.用同义表达形式来扩充信息检索的查询语句例证研究——对于一种基于语义的搜索方式的若干设想[J].语言文字应用.2008,123-131.
[5]Christiane Fellbaum.WordNet:An Electronic Lexical Database[M].1998.MIT Press.
[6]知网:http://www.keenage.com/[DB/OL]
[7]Matthew Berland and Eugene Charniak.Finding Parts in Very Large Corpora[C]//Proceedings of the the 37th Annual Meeting of the Association for Computational Linguistics.1999.
[8]Roxana Girju,Adriana Badulescu and Dan Moldovan,Automatic Discoveryof Part-WholeRelations[J].Computational Linguistics,2006,32(1):83-135.
[9]Xinyu Cao,Cungen Cao,Shi Wang and Han Lu.Extracting Part-Whole Relations from Unstructured Chinese Corpus[C]//Proceedings 4th International Conference on Natural Computation and 5th International Conference on Fuzzy Systems and Knowledge Discovery.2008.
[10]Robert Van HageWillem,Hap Kolb and Guus Schreiber.A method for learning part-whole relations[C]//Proceedings of the 5th Int.Semantic Web Conf.,2006:723-736.
[11]贺宏朝,何丕廉,高剑峰,等.一种基于上下文的中文信息检索查询扩展[J].中文信息学报,2002,16(6):32-37.
