基于上下文的真词错误检查及校对方法
2011-10-15陆玉清姚建民朱巧明
陆玉清,洪 宇,陆 军,姚建民,朱巧明
(苏州大学江苏省计算机信息处理重点实验室,江苏苏州215006)
1 引言
拼写错误是英文文本中较常见的错误。Kukich[1]将英文文本中的错误分为两种类型,一类是上下文无关的错误(isolated-word error),也叫非词错误,即输入的词是一个无效的词,在字典中不存在。这种错误不需借助上下文,只要和词典中的词进行匹配就能发现,例如the错拼为teh、reluctant错拼为 reluctent。另一类是上下文有关的错误(context-dependent word error),也叫真词错误,即输入的词是和原词相似的另一个有效词,如:I have a peace of cake.其中peace实际上应为piece。目前,非词错误的纠错方法已经有很多研究,而真词错误检查及其校对要比非词错误校对困难得多。因为真词错误的单词是字典中正确的词。所以,对于错误使用的真词检查及给出的拼写建议,主要依据对该真词的上下文的考察。
本文研究真词错误的检查及修改的方法。对于所检查的真词错误[2]不仅包括一些“典型”的拼写错误,例如同音字错误,如peace和piece;拼字错误,如在句子“I'll be ready in five minuets.”其中的minuets应该是 minutes。同时还包括一些常见的语法错误,如among和between;以及代词的使用错误 ,如在句子“I had a great time with his.”其中的his应该用him代替;另外还包括跨境词边界错误,如maybe和may be。
实验最终的研究目标在于,基于已有的真词错误检查的研究,扩大从上下文中提取特征的范围,同时结合目前已有的特征筛选方法,进一步对所提取的特征进行筛选,再利用Winnow分类算法对句子中出现的易混淆词的使用正确与否给出判断。
2 相关工作及系统框架
2.1 相关工作
Daniel Lawrence[3]、美国的 Kukich[1]、Andrew R.Golding&Dan Rose[4-5]、Lidia Mangu[6]都做了关于真词拼写检查的研究。Lidia Mangu[6]使用了Bayesian和Winnow两种分类算法,结果表明Winnow算法的分类结果优于用Bayesian的分类结果,其中使用Winnow分类算法得到的正确率为94.01%。其在上下文中提取的特征为上下文的单词和词性,而没有考虑上下文中的单词与易混淆词之间的搭配,即连接词特征。Andrew R.Golding&Dan Rose[5]同样运用了Bayesian和Winnow算法,使用的特征为上下文单词以及上下文单词中与易混淆词之间的搭配,使得结果得到了改进,所研究的21组混淆集的平均正确率达94.87%。
在国内,张磊,周明[7]介绍了真词错误检查时使用的一些方法,其中提到了通过基线①基线即通过设定阈值,选取出现频率较高的特征。、上下文词和搭配来获取特征的方法,同时详细分析了一些特征混合模型,包括决策列表,Bayesian分类器和Winnow分类算法。张仰森,俞士汶[8]综述了现有的基于上下文的文本错误校对方法主要有两种:①利用文本上下文的同现与搭配特征;②利用规则或语言学知识。他们的工作都只进行了方法的介绍,没有进行相关的实验。另一方面,李斌进行了真词错误检测的实验[9],其采用了基于混淆集的真词错误检测方法,并使用了Bayesian分类方法,但其在上下文中所提取的特征较少,只考虑到混淆集合中词的前后各一个词及其词性,造成了在检测过程中还存在一些误判,考虑更多的特征将会得到更好的效果[6]。
2.2 系统框架
本文扩大了在易混淆词的上下文中提取特征的种类和范围,同时进一步深入地进行了特征筛选。提取的特征包括连接词、词性两种句法特征,和上下文的词作为语义特征;提取特征的范围由原先的前后长度为1,扩展到前后长度为5。特征筛选时采用了文档频率和信息增益。该方法主要流程如图1。其中真词错误检查系统中的语料分为两个部分,分别为训练集和测试集。首先针对训练集中的每个句子,从易混淆词的上下文中提取特征。在这些特征的基础上,对其中的上下文单词特征进行筛选,选取其中对分类影响较大的特征。至此,特征提取的过程结束,接着利用Winnow算法进行权重训练,即先对每个特征赋给初始权重,再通过Winnow算法对每一个易混淆词的相关特征进行权重更新。最后依据训练得到的特征权重对测试集进行测试,得到最终的评判结果。

图1 真词错误检查系统流程图
3 基于上下文的真词错误检测方法
真词错误检查的过程被建模为词排歧的过程。将英文文本中彼此容易混淆的词收集在一起,形成一个混淆集[8]C={W1,W2,…,Wn}。当在句子中遇到任意一个Wi(称为目标单词)时,就要考虑混淆集C中的其他单词是否更适于该处的上下文。该过程可以描述为,首先从目标词的上下文中提取有效特征,将特征用向量表示后作为分类的输入,对目标词所在混淆集的所有单词分别利用Winnow分类算法进行判定,取其中值最大的结果所对应的单词作为最终判定。
3.1 特征提取
采用向量空间模型表示上下文信息,将目标单词的上下文特征用一组向量(T1,T2,…,Tn)表示,其中Ti为第i个特征的权重。
3.1.1 句法层面特征的提取
句法层面的特征提取包括:①目标词前后一定范围内的连接词。②目标词前后一定范围内的单词的词性。其中,在上下文中所提取的连接词不仅仅限定为连词,只要是在句子中起到连接作用的词均为连接词。目标词前后的连接词,可以反映词之间的有序依赖关系。例如except周围可能出现的连接词有for、that等。我们还发现,一些单词前后常用的连接词并不在长度为1的范围内,如 The insurance policy can protect you against injury.其中against是protect周围常用的连接词,但却不在目标词protect的前后长度为1的范围内。因此为了尽可能多的获取该类信息,本文中扩大了连接词的查找范围,在连接词前后长度为3和5的范围内进行查找。
3.1.2 语义层面特征的提取及筛选
语义层面所提取的特征为目标词前后一定范围内的单词。对于某一个易混淆词,其前后可能出现的不同单词较多,而且不同单词出现的频率差异较大。例如在实验的训练语料中,易混淆词former周围的不同单词数量多达360个,其中出现频率最小的为1次,最大的为46次。在此我们假设,出现频率较低的单词对分类的影响力较小,可以忽略不计。因此在实验中,我们首先使用文档频率这一特征筛选方法,对出现在目标词前后的特征单词进行筛选,统计每个单词出现的频率,通过设定阈值去除其中文档频率较小的特征。
对于特征单词t和混淆集中的某一单词C,信息增益通过考察C所在的句子中出现和不出现t的句子频数,来衡量t对于C所提供的信息的多少,定义如下[10]:
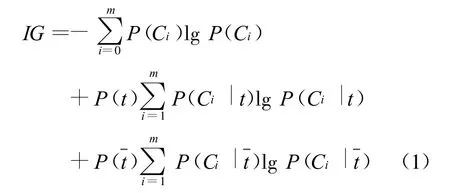
其中,P(Ci)表示某混淆集中的单词Ci在语料中出现的概率,P(t)表示语料中包含特征单词t的句子概率,P(Ci|t)表示句子中包含特征t时是单词Ci的条件概率,P()表示语料中不包含特征t的句子概率,P表示句子中不包含特征t时是单词Ci的条件概率,m表示该混淆集中单词总数。根据公式(1)计算某个易混淆词的每个特征的信息增益,进行非降次排序,选择大于一定阈值的词作为最终的特征集。
如果某特征仅出现在其中一类单词的句子中,且该特征的文档频率值较小时,该特征得到的信息增益同样较大。例如在易混淆词alone的上下文单词特征中有单词Nicola(在句子中作为人名使用)出现1次,其信息增益值为0.012。而往往出现频率较低的单词对分类的影响较小,这就造成了所选取的部分特征对分类的准确性产生了一定的影响。因此,在该实验中选择在应用信息增益进行特征筛选之前,利用文档频率预先筛选出一部分特征单词。
3.2 Winnow分类算法
Winnow算法是一种在二值属性数据集上的线性分类算法[11]。该算法中有3个参数,一个阈值参数 θ,两个权重更新参数 α、β,其中 α>1,0<β<1。该算法分类的步骤为,对于某易混淆词,其周围的n个特征单词可以表示为一维向量X={x1,x2,…,xn},对应的每个特征单词的权重向量可以表示为:
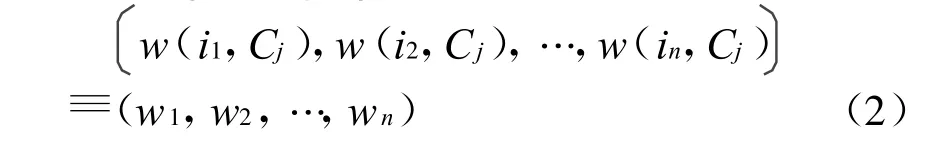
其中w(i,C)为C类中特征的权重。该算法给出判定为1当
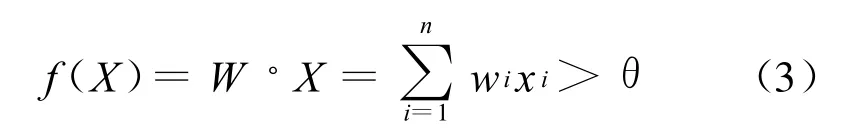
其中xi为0或1,用于表明该特征是否出现,wi是与xi对应的特征的权重。训练是错误驱动的,也就是说只有对样本分类产生错误时才会利用参数α、β调整权重向量W。
4 实验设计与结果分析
实验中我们选取了61组混淆集,其中混淆集单词个数为2的有60组,单词个数为3的为1组。从英国国家语料库(British National Corpus)中收集了与混淆集中的单词相关的句子约5000句,选取部分句子使用相应混淆集中的词进行替换,将其中的80%作为训练集,剩余的为测试集。在提取单词词性特征时,使用了斯坦福大学NLP Group开发的词性标注工具(Stanford Log-linear Part-Of-Speech Tagger)[12]。实验中共收集了140个连接词,作为在上下文中查找连接词的“字典”。另外考虑到,所提取的连接词与上下文特征单词有重复的部分,此时在上下文单词特征中删除重复的特征单词。实验中Winnow算法的相关参数被设置为:α=1.3,β=0.8,θ=1.1,各个特征的初始权重为0.2。
在实验中采用准确率(p)、召回率(r)和F1测度来评价结果的好坏,这些性能评价指标定义如下:

4.1 进行特征选择的实验结果与分析
为了确定最佳的连接词特征的查找范围,实验中分别在距离目标词前后长度为1、3、5范围内进行查找,得到的对应的F1值分别为20.76%、42.83%、42.57%。为了降低特征向量的维数及计算的复杂度,并希望能够选择一些和分类相关性大的特征来提高分类的准确性,选择长度为3范围内的连接词,较选择在1、5范围内的连接词作为特征更为合适。
在前后单词特征筛选时,首先利用了文档频率的方法,分别实验了在去除词频小于等于2、4、5的情况下得到的正确率,如表1所示。
从表1中可以清晰地看出,DF=4时得到的正确率为70.81%,较DF=2和DF=5的情况下得到的正确率高,因为出现次数太少的词(低频词,或者叫生僻词)往往是表意能力很差的词,而删除太多的词又会降低对语意的理解。因此下面在利用信息增益进行特征筛选时,是基于DF=4时所筛选出来的特征进行的。
从表2中可以看出,当信息增益中所设定的阈值为0.015时得到的正确率最高为71.92%。由此,通过前面的文档频率和信息增益两步筛选,得到了最终确定的特征单词。
4.2 使用不同特征的实验结果与讨论
依据上述评价指标,得到的在利用不同特征情况下,各混淆集的正确率和召回率的结果见表3。

表1 利用DF进行特征筛选的各混淆集的实验结果
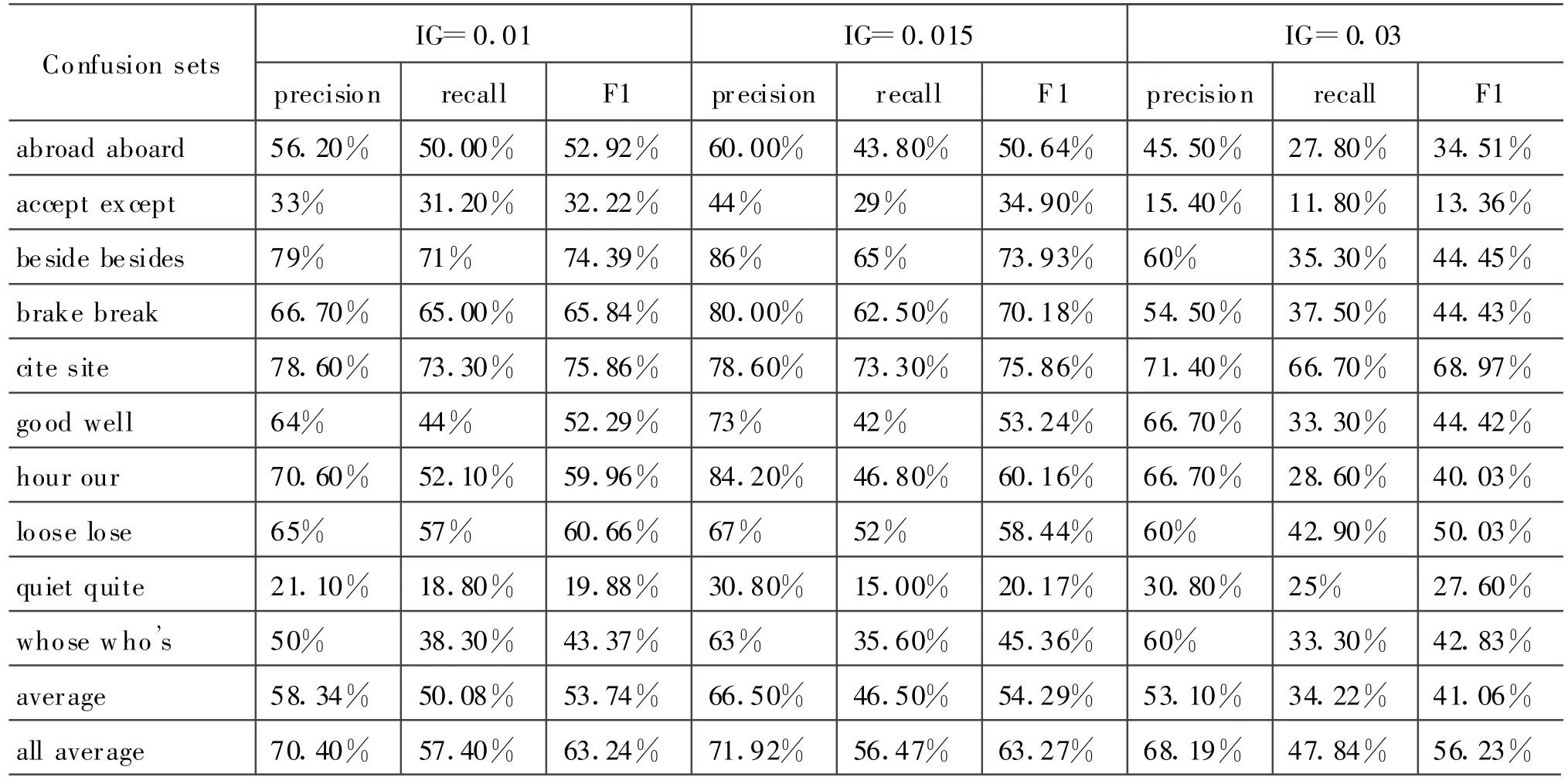
表2 利用IG进行特征筛选的各混淆集的实验结果
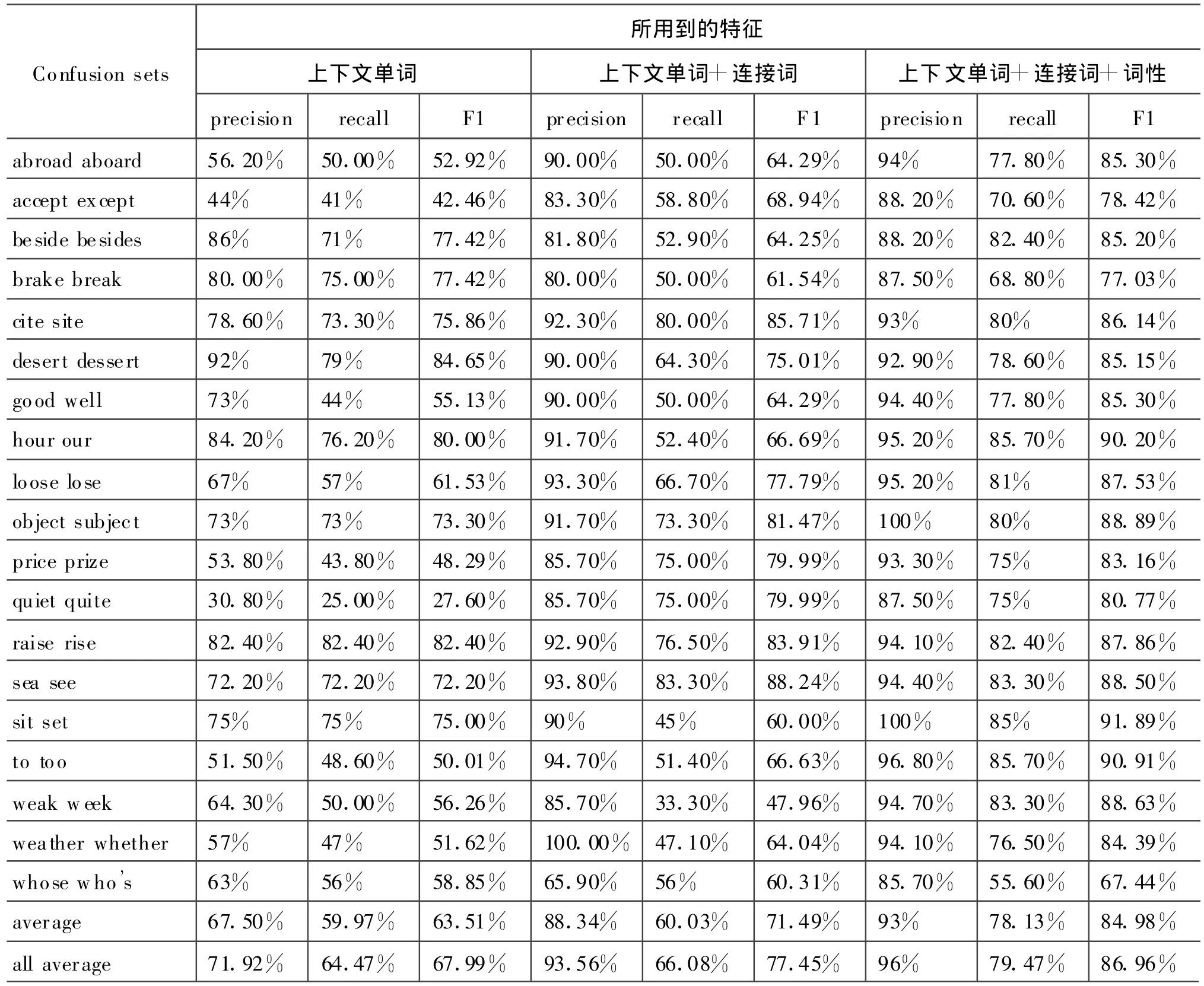
表3 利用不同特征所得到的各混淆集的实验结果
从表3中可以看出,当所用到的特征仅为上下文单词时,考察的是目标词周围的语义环境。例如混淆集{desert,dessert},其中desert上下文单词特征中有:basin,river,flower等;dessert上下文单词特征有:sweet,cheese,wine等。在上下文单词的基础上加入连接词特征,正确率得到了较大的提高。因为对于某些单词,特别是动词,其前后的连接词对于确定该单词具有较好的效果。例如混淆集{abroad,aboard},其中abroad前后的连接词特征有:from,on,at等;aboard前后的连接词特征有:off,into等。在前两个特征的基础上,加入词性特征,使得正确率得到提高,同时较大的提升了召回率。由于提取出来的词性特征比较集中,最多的一组混淆集的词性特征只有29个,这使得给出判定的可能性增大,进而提高了召回率。
5 总结与展望
本文扩大了在上下文中提取特征的种类和范围。通过从易混淆词的上下文中提取语义和句法两个方面的特征,并能够对特征进行有效的筛选,使得最终确定的特征为分类提供依据。实验表明,扩大特征提取的范围及选取有效的特征能够使得系统的性能更好。本文下一步的工作是扩大语料,以能够尽可能广泛地收集易混淆词的语言环境中的信息,从而得到更多的特征为分类服务。
[1]Kukich.Techniques for automatically correcting words in text[J].ACM Computing Surveys,1992,24(2):377-439.
[2]Andrew.J.Carlson,Jeffrey Rosen,Dan Roth.Scaling Up Context-Sensitive Text Correction[C]//American Association forArtificial Intelligence(www.aaai.org),2001.
[3]Daniel Lawrence.SpellingCheckerand Corrector[S].1992.
[4]Andrew R.Golding&Dan Rose.Applying Winnow to Context-Sensitive Spelling Correction[C]//Proc.of the 13thICML,Bari,Italy,1996.
[5]Andrew R.Golding.A Winnow based approach to context-sensitive spelling correction[J].Machine Learning 34(1-3):107-130.Roth.Special Issue on Machine Learning and Natural Language.1999.
[6]Lidia Mangu,Eric Brill.Automatic Rule Acquisition for Spelling Correction[C]//Proceeding of the 14thInternational Conference on Machine Learning,1997:187-194.
[7]张磊,周明,黄昌宁,等.中文文本自动校对[J].语言文字应用,2001,(1):19-26.
[8]张仰森,俞士汶.文本自动校对技术研究综述[J].计算机应用研究,2006,(6):8-12.
[9]李斌,姚建民,朱巧明.英文作文的自动拼写检查研究[J].郑州大学学报(理学版),2008,(3):48-51.
[10]Y.Yang,J.P.Pedersen.A Comparative Study on Feature Selection in Text Categorization[C]//Proceedings of the 14th International Conference on Machine Learning.1997:412-420.
[11]Littlestone N.Learning quickly when irrelevant attributes abound:a new linear threshold algorithm[J].M achine Learning,1988,4(2):285-318.
[12]KristinaToutanova.Stanford Log-linearPart-Of-Speech Tagger[DB/OL].http://nlp.stanford.edu/software/tagger.shtml,2009-12-24/2010-3-12.
