一种混合式协作过滤服务推荐算法
2011-09-25张圣
张 圣
(南京工业大学 电子与信息科学学院,江苏 南京 210009)
0 引言
随着电子商务的飞速发展,用户得到的服务类型也在不断丰富,既有传统的实物交易,也有音乐、电影等各种类型的服务[1]。在此过程中,用户找到自己所需的个性化服务对象难度增大,服务提供商还要考虑以怎样的方式提供服务供用户选择,服务推荐作为解决这一问题的有效手段应运而生[2]。
协作过滤推荐是当前被广泛被采用服务推荐算法,然而基于这种协作过滤的服务推荐技术存在无法双向推荐的局限性[3]。
现提出了一种新的基于混合式协作过滤的双向服务推荐算法,同时考虑用户之间和服务之间的相似度,为用户和服务提供商产生双向推荐。实验结果表明该算法可以有效地解决传统协作过滤算法无法产生双向推荐的不足,显著提高推荐系统的推荐量。
1 传统协作过滤推荐算法
传统协作过滤算法基于一种假设:如果用户对某些服务的评分结果相似,那么其它服务的评分结果也较为相似。通过统计若干目标用户的最近邻居,利用最近邻居的评分来预测目标用户的评分,从而产生推荐[4]。
用户的评分数据可以由一个集合m×n阶矩阵R来表达,m行代表m个用户,n列代表n个项目,第i行第j列的元素Rij代表用户i对项目j的评分,如表1的矩阵所示。
然后通过传统的相似性度量方法如余弦相似性[5]来计算用户i和其它所有用户之间的相似度,通过对这些相似度进行排序,找出与用户i最相似的k个最近邻集合,最后通过设定的预测评分公式对k个最近邻集合中项目的评分进行计算,得到预测的用户i的评分数据。
传统协作过滤算法随着用户及服务的增大性能降低快,有人提出了结合用户间相似性和项目间相似性进行混合式协作过滤[6],这里进一步优化了混合式协作过滤算法,通过计算用户、项目和全局平均评分偏差的加权来同时得到用户、项目的预测评分,从而产生更高质量的推荐。
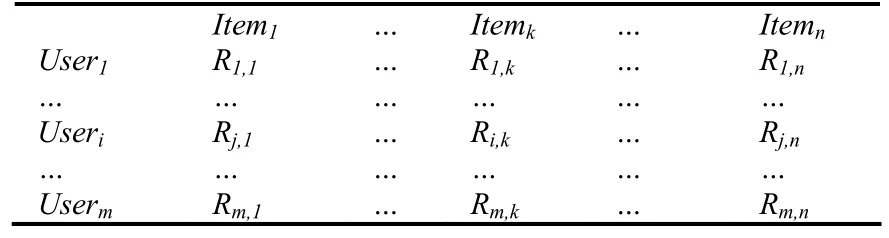
表1 用户项目评分矩阵
2 混合式协作过滤推荐算法
混合式协作过滤推荐算法的输入是用户-项目评分矩阵,用户集合U和项目集合I构成一个m×n阶矩阵R(m,n),其第a行第j列元素表示用户a对项目j的评分向量,描述了用户a对项目j的评分,如果用户a未对项目j评分,则将其评分向量设为0。
任取用户 a∈U,将 a在评分矩阵 R(m,n)中对应的第 a行元素的集合记为La,将集合La中不为0元素的项目集合记为Ia即用户a已经评分的项目集合。同样,项目j(j∈I)在评分矩阵R(m,n)中对应的第j列元素记为Cj,将集合Cj中不为0元素的用户集合记为Uj即项目j评分的用户集合。
2.1 相似性度量方法
相似性度量方法采用皮尔逊相关系数计算用户之间和项目之间的相似度,用户u和用户a的相似度如式(1)所示:

其中Iua表示用户u和用户a共同评分项目的集合,即Iua=Iu∩Ia,Lu和La分别表示Lu和La的平均值向量。由(1),sim(u,a)的范围在区间[-1,1]之间,当sim(u,a)∈[-1,0]时,用户u和用户a不相似;当sim(u,a)∈(0,1]时,sim(u,a)越接近于1用户u和用户a的相似度越高。同理,项目i和项目j的相似度采用同一公式,不再赘述。
为了解决用户u和a共同评分的项目集合Iua较小时,u和 a的相似度应当较小但是公式(1)计算出的相似度可能很大的问题,在式(1)的计算结果sim(u,a)上添加权重,式(2)给出调整后的用户u 和用户a的相似度:

其中|Iu∩Ia|和|Iu∪Ia|分别表示用户 u评分项目和用户 a评分项目的交集和并集中元素的个数。当评分交集Iua较小时,|Iu∩Ia|较小,用户u和用户a的相似度sim'(u,a)就较小。项目i和项目j的相似度同理。
2.2 预测值计算方法
由公式(2)可以计算出用户u和其他用户的相似度,将其从大到小排序,前k个用户就是u的k-最近邻集合[7]T(u)。在T(u)中将相似度不大于0时近邻用户去掉,得到集合N(u),如式(3)所示:
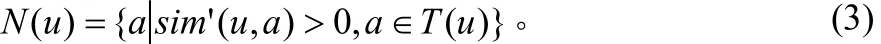
同理计算项目i的k-最近邻集合N(i)
混合式协作过滤推荐算法通过预测在线用户u对未评分项目i的评分,将预测评分高的项目推荐给该用户,将用户u对项目i的预测评分向量记为P(u,i)。这里提出一种新的预测评分向量计算方法,通过全局平均评分向量µ、用户u对µ的偏差、项目i对µ的偏差三者的加权和来得出P(u,i)。
全局平均评分向量µ是评分矩阵R(m,n)所有元素的平均值向量,如式(4)所示:

用户u对µ的偏差记为D(u),根据用户u的k-最近邻集合,如式(5)所示:
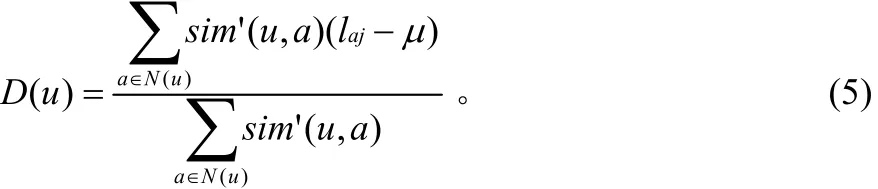
项目i对µ的偏差D(i)计算同D(u)。
为了调整基于用户的预测和基于项目的预测的依赖度[8]引入参数λ(0≤λ≤1)调整权重,P(u,i)如式(6)所示:
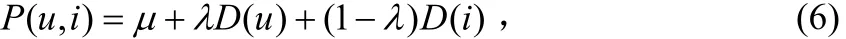
P(u,i) 描述了用户项目u对i诸方面属性的预测评分,面向用户和服务提供商进行双向推荐即为在线用户u推荐最有可能感兴趣的N个服务,同时为服务提供商i推荐最有可能对其感兴趣的M个在线用户。
3 实验结果及分析
3.1 实验数据集
采用MovieLens(接收用户对电影的评分并提供相应的电影推荐列表)站点提供的数据集(http://movielens.umn.edu/)。在该数据库中选择8 000条评分数据作为实验数据集,包含200个用户和800部电影,每个用户至少对20部电影进行了评分。
3.2 实验度量标准
采用平均绝对偏差(MAE,Mean Absolute Error)作为统计精度度量方法:设预测的用户评分的集合为{b1,b2,…,bN},对应的实际用户评分集合为{p1,p2,…,pN},则平均绝对误差MAE的定义如式(7)所示:

MAE通过计算用户的预测评分数据和用户的实际评分数据之间的偏差来度量预测的准确程度。MAE越小,推荐的质量越高。
3.3 K最近邻不同条件下的实验及分析
如图1所示,在K最近邻实验实验条件下,混合式协作过滤的双向服务推荐算法均具有最小的 MAE.由于综合考虑了用户和项目之间的相似性,同时考虑了多种评分偏差,因此与传统的协作过滤推荐算法相比,显著地提高推荐系统的推荐质量。
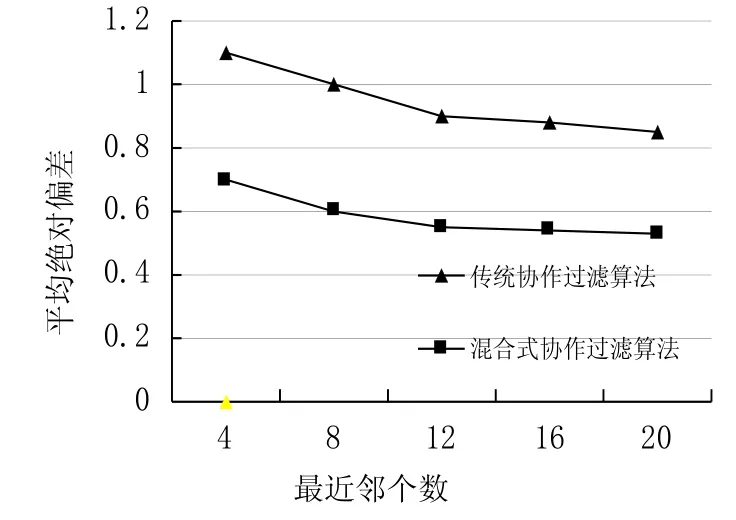
图1 两种算法对比
4 结语
这里在分析传统协作过滤推荐算法的不足之后,提出了一种基于混合式协作过滤的双向服务推荐算法,这种算法由于同时考虑了用户间相似性和项目间相似性,能够同时为用户和服务提供商进行双向的推荐,同时综合考虑了用户、项目、全局之间的评分偏差。实验结果表明,该算法不但能进行双向推荐,而且有效的提高了推荐质量。
[1] 赵攀,雷文,周刚. 基于电子商务背景的智能挖掘技术及其应用研究[J]. 通信技术, 2009,42(08):76-78.
[2] 韩家炜. 数据挖掘:概念与技术[M]. 北京:机械工业出版社,2004:137-147.
[3] 李岚. 数据挖掘技术在电子商务中的应用[J]. 通信技术, 2007,40(08): 74-76.
[4] 欧立奇. 协同过滤在电子商务推荐系统中的应用研究[D]. 西安:西北大学,2005.
[5] MA H, KING I, LYU M R. Effective Missing Data Prediction for Collaborative Filtering[M]. USA:ACM, 2007:39-46.
[6] Sung Ho Ha. Helping Online Customers Decide through Web Personalization[J]. IEEE Intelligent Systems, 2002(10-11):34-43.
[7] 赵亮, 胡乃静. 个性化推荐算法设计[J]. 计算机研究与发展,2002,39(08):986-991.
[8] 肖冬荣, 杨磊. 基于遗传算法的关联规则数据挖掘[J]. 通信技术,2010, 43(01): 205-207.
