移动通信网中基于用户社会化关系挖掘的协同过滤算法
2011-09-19黄武汉孟祥武王立才
黄武汉 孟祥武 王立才
(北京邮电大学智能通信软件与多媒体北京市重点实验室 北京 100876)
(北京邮电大学计算机学院 北京 100876)
1 引言
随着移动通信技术的飞速发展,移动设备逐渐成为人们获取信息的主要平台之一。与传统互联网终端相比,移动设备拥有移动性强、上下文感知能力强、可携带性好、入网方便等特点,使得人们可以随时随地获取移动网络服务和信息内容[1]。然而,随着移动多媒体技术和移动信息承载、传输能力的提升,尤其是移动社交网络的兴起,大量丰富多彩的移动服务和信息内容日益涌现,为人们带来严重的移动信息过载问题。此外,移动网络资源有限,移动设备也存在输入输出能力弱、电池续航能力弱等缺点,如何从浩瀚的移动信息海洋中发现用户真正感兴趣的内容,以提升移动用户的个性化服务体验,成为面向移动通信网络的个性化服务领域亟待解决的技术难题。传统推荐系统在解决互联网信息过载问题方面取得较大进展,成为辅助人们信息过滤和决策的主要工具之一。由于移动通信网络与传统桌面互联网相比,有自身的特点,而且移动信息传递也颇受上下文信息、移动社会化网络的影响,所以传统推荐系统的各种模型和算法并不能完全适用于移动通信网络中的数据建模与推荐。目前,国内外研究人员也开始研究如何将传统推荐系统的模型和算法应用于移动通信网络环境,并取得一定进展[2]。
本文面向移动通信网络中的信息过载问题,利用移动通信行为构建初步的移动社会化网络,并深入挖掘潜在的用户社会化关系,然后将其应用于协同过滤算法,帮助移动用户发现与其兴趣最相似的近邻用户,并进行移动用户偏好预测,最终提出一种移动通信网中基于用户社会化关系挖掘的改进协同过滤算法。本文第2节介绍了协同过滤算法、相似性计算方法、移动推荐系统等方面的相关工作;第3节提出移动通信网中基于用户社会化关系挖掘的协同过滤算法;第4节给出仿真实验分析和利用公开数据集展开的实验,结果表明了该方法的有效性和合理性;最后给出结论。
2 相关工作
推荐系统[3]作为缓解“信息过载”的重要手段,已得到广泛研究。从信息过滤的角度,可以将其分为:协同过滤、基于内容的过滤和混合式过滤[3]。其中,协同过滤源于“集体智慧”的思想,首先根据部分用户对项目的偏好信息或者评分信息计算用户之间或者项目之间的相似性,然后利用相似用户或者相似项目的用户偏好来预测未知的潜在用户偏好,最后按照偏好排序结果生成推荐。
协同过滤中的相似性计算方法主要有3种。第1种为余弦相似度公式[4],定义如下:
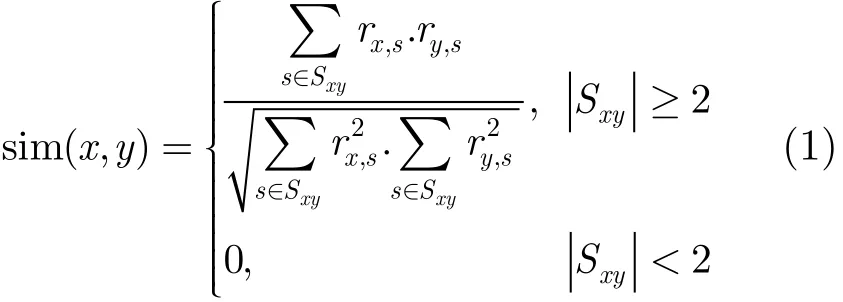
其中sim(x,y)表示用户x与y的相似度,rx,s表示用户x对项目s的偏好度,Sxy表示x与y共同评分的项目集合。
第 2种为 Pearson相关系数计算公式[5],表示用户x对已评分项目的平均评分值,定义如下:sim(x,y)=

第3种算法为修正的Pearson相关系数计算公式[5],rmid表示修正中值, 定义如下:

近年来,研究人员针对移动通信网络环境和移动用户的特点,提出“移动推荐系统”的概念。文献[6]提出可以通过分析移动通信网下的服务内容,并结合用户使用的反馈信息等,为用户推荐其更喜欢的服务。文献[7]则认为要结合移动终端的可移动性特点,利用一些便携式的传感器设备,捕获用户在日常服务体验中的直接情感表达信息,从而为用户提供其所喜爱的服务。相对互联网而言,针对移动通信网中以社会化推荐方式进行用户评分预测的研究相对较少。文献[8]提出了一种基于社会化网络的混合推荐算法,该算法将传统的协同过滤与社会化网络中的人际关系结合,但并未陈述如何衡量社会化网络中的信任关系,而且并没有考虑如何利用移动通信行为构建社会化网络关系及其进一步挖掘。文献[9]直接以互联网下的邮件系统为例子,介绍了如何利用用户日常的邮件交互行为建立一个互联网下的社会化网络,以此来进行偏好预测,同样未考虑移动通信网络环境下的移动社会化网络与推荐系统之间的结合。
本文针对移动通信网中的个性化推荐问题,提出了一种基于移动用户社会化关系挖掘的协同过滤算法。首先对余弦相似度公式进行了改进,使得共同评分项目较少的用户间也能进行相似度计算,扩大推荐数据源;其次,通过挖掘移动社会化网络中存在的直接及其潜在关系,获得与用户喜好密切相关的用户数据,将这些重要的用户偏好信息作为填充初始推荐数据源的数据之一进行评分预测,在一定程度上缓解了数据稀疏性问题。
3 算法设计
3.1 建立原始数据模型
移动通信网中存在着大量的用户交互数据,主要包括电话、短信等通信记录及用户使用移动通信网服务的一些评价信息。这些信息对于分析移动网络用户需求和构建移动社会化网络具有重要价值。本文建立的数据模型包括4个数据集:
(1)用户集合,即所有移动通信网用户集合,使用U表示。
(2)移动网络服务集合,即需要处理的所有移动网络服务集合,使用S表示。
(3)用户社会化关系矩阵,即集合U中的用户间的交互行为,这种行为是双向的,本文使用F'来表示最初的通信关系矩阵,对这个矩阵中的数据本文将按一定的规则进行挖掘,计算出好友关系矩阵F,F是一个不对称矩阵,即用户x认为用户y是可以信任的好友并不代表y也认为x是可以信任的,在交互行为中,表现为x联系了y,那就表示x信任y。
(4)用户对服务的评分矩阵,即集合U中用户对集合S中服务的评分矩阵,这些数据来源于用户对所使用业务的反馈、评价等记录。如用户连续订阅了某个业务,就认为该用户喜欢这个业务;在一段时间内订阅,则表明用户对这个业务感兴趣等,结合用户的使用反馈及网上评分来修正这些数值,就可以挖掘出原始的评分矩阵,使用R表示。
在上述两个矩阵中,用fx→y表示F中存在用户x信任y的记录,rx,s表示用户x对于服务s的评分值。
3.2 好友关系挖掘
将F'中的短信与通话数据进行如下处理,来确定F。
步骤 1 将数据中的通信主体抽取出来,判断是否是所需要预测的目标,如果不是,则删除数据,形成矩阵F1,这一步是为了删除一些广告及网外用户号码的无用数据。
步骤 2 以用户x为例,将F1中由x充当发送方的短信数据提取出,统计短信总数c及各个充当接受方的用户i和对应短信数ci;将F1中由x充当主叫方的通话数据提取出,统计用户x通话总时间t,通话总次数q及各个充当被叫方的用户i与用户x通话的总时间ti,通话总次数qi。定义p为x对用户i的信任程度,则

本文认为,在F1中的所有通信组合中,x仅与其通信对象中的 80%用户是好友关系,所以取p最高的 80%用户,将这些用户定义为x信任的对象即好友,并将信任程度p作为数值加入矩阵F2中。
步骤 3 对于U中的每一个用户,都执行步骤2,并把好友关系及信任程度p写入矩阵F2中,则F2就是从通信记录中挖掘出的直接好友关系矩阵。
由通信记录确定的直接好友关系比较稀疏,不利于推荐,而且现实中,也不是所有的好友间都有通信行为,因而从通信记录中无法全面地获取用户间的好友关系,所以需要通过矩阵F2挖掘更多有用的信息。对于任意两个好友而言,他们的好友集合或多或少会存在交集。用fx表示x的好友集合,如果x与y是好友关系,则fx与fy将存在交集,基于此本文认为:当fx∩fy中的元素在fx中的比例达到某个阈值α(如50%)时,x信任y,即y是x的好友。所以进一步做如下处理:
步骤 4 以用户x为例,将F2中的fx取出,与U中x的非好友关系用户在F2中的好友集合进行比较,用fy表示y的好友集合,当满足条件式(5)时,将y定义为x的好友。
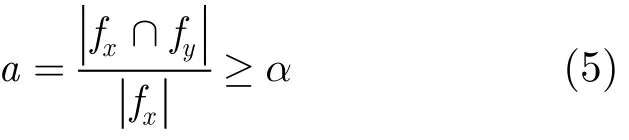
步骤 5 由于集合fx∩fy确定了y与x的好友关系,因此x对y的信任程度也应由此集合确定,用p表示集合x对fx∩fy所有用户信任程度的平均值,即

其中pi表示x对用户i的信任程度。使用式(7)计算py:

将好友关系及对应的信任程度p写入矩阵F3中。显然,这里的信任程度只是对以单个用户为中心的社交网络关系的描述,在全局网络中不具有可比性。
步骤 6 对F2中每一个有好友的用户都重复步骤4,步骤5,将这种间接好友关系及信任程度写入矩阵F3。
步骤 7 由F2与F3最终确定好友关系矩阵F,如式(8)所示,其中F2代表直接好友关系矩阵,F3代表间接好友关系矩阵。

3.3 基于评分数据的用户相似度计算
对于U中的任意用户组合x与y,用其共同评分项目来计算他们之间基于业务评分的相似度,从而得到相似度集合SM。

其中sim(x,y)表示x与y的相似度,用rmax表示R中所定义的最大评分值,rmin表示最小评分值,相似度计算公式如式(10)所示。

3.4 用户偏好预测
用SMx表示x与集合U中其他用户的相似度集合,mx表示x与好友的相似度集合,用nx表示x与非好友的相似度集合,其中mx中的各个用户与x还存在着通过社会化关系而得到的信任程度关系,显然,

数据选取方式可以根据3种不同方法进行。
方法1:选取SMx中相似度大小为前50的用户数据。
方法2:选取mx中相似度大小在前t%的用户数据。
方法3:选取nx中相似度大小为前50的用户数据与mx中相似度大小在前t%的用户数据。
第1种是传统的协同过滤算法中的数据选取方式(Traditional Data Selection,TDS);第2种是建立在好友关系的数据选择方式(Data Selection Based on Friends,DSBF);第3种是本文所提出的基于用户社会化关系挖掘的混合数据选择方式(Data Selection Based on the Combination of Tradition and Friends,DSBCTF)。
将通过社会化关系挖掘出的好友关系及其信任程度与传统的基于项目评分的相似度结合,进行评分预测,具体如式(12)。

与传统协同过滤算法相比,本文算法增加了通过社会化关系挖掘出的好友关系及其信任程度对推荐结果的影响,而且当预测用户无评分项目即=0 时,采用与预测用户及其相关用户的其他间接评分无关的预测公式,使得推荐结果更加符合实际。公式中C表示上述提到的3种不同的用户集合,表示x已知评分的平均值,py表示x对y的信任程度,当y不是x好友时:py=0 。对于 3种数据选取方式,本文将用实验的方法确定最优解;其中t% 的取值,将在4.2节中确定。通过计算,便可以得到x对未知评分业务的评分值。若无法预测,将用0代替。
4 实验
本文实验环境为:2 GB内存,2.93 GHz双核CPU,Windows XP2操作系统,Java1.6开发语言,Eclipse3.5集成环境,Mysql5.0数据库。实验将分成两个部分:(1)使用仿真数据集展开实验表明本算法的可行性和有效性;(2)使用公开数据集来研究相关参数的选择方法以及与其他基准算法的性能比较。
4.1 基于模拟数据集的实验
4.1.1 模拟数据集介绍实验所需要生成的模拟数据包括移动用户列表,移动业务列表,移动用户的关系列表和移动用户对移动业务的原始评分列表,其中移动用户的关系列表只是直接的好友关系,实验中,将根据这个列表进一步挖掘潜在的社会化关系。为了使实验更加简便,直接规定:对单个用户而言,他对所有好友的信任程度相等,并且等于直接参与评分预测的好友数的倒数。
这里用实际的900个移动手机号码代表用户,将用户分成3个集合,假定每个集合中的用户在业务评分上相似,不同集合中的用户业务评分差异较大;移动业务数为90,这些业务分为3个集合,分别代表电话套餐、短信套餐和GPRS套餐业务。另外随机确定一些好友关系组合,其中每个用户平均有10-30个好友。这些好友分布在不同的3个集合中,本集合成员(自己除外)占有 80%的比例,其余两个集合成员占有20%的比例,形成最初的用户关系矩阵。
假定3个集合的用户对3种不同的套餐业务评分差异很大并预先规定了这些评分矩阵的不同取值范围,具体如表1所示,表中U_S1表示用户对电话套餐业务集合的评分值范围,U_S2表示用户对短信套餐业务集合的评分值范围,U_S3表示用户对GPRS套餐业务集合的评分值范围。根据这个规则和设定的评分覆盖率(这里为30%),形成原始评分矩阵。
4.1.2 评价方法本文使用两种度量标准来衡量实验结果:首先借鉴信息检索领域广泛使用的查准率[10],查准率(Precise),又称“准确率”,用来衡量系统的查准率。定义如下:

表1 评分范围限定

其中Th表示可预测结果中,符合表1所述规则的数据量,T表示可预测结果的总数据量。
然后,使用MAE[10]公式的另一种形式的绝对误差率|,来评价实验结果,定义如下:

其中N表示可预测数据量,ri表示预测结果中不符合表1的评分值,ti表示与ri对应的在表1中应该所处的范围的临界值。rmax与rmin表示数据集中的最大与最小评分值,本实验中rmax=10,rmin=0。
4.1.3 实验描述及结果分析首先我们从模拟生成的初始好友矩阵中挖掘出更多的社会化关系,其中间接好友关系挖掘阈值α定为50%。而后将数据作为输入,代入本文所提的DSBCTF数据选择算法中进行评分预测,其中t%定为70%,在预测评分阶段,数据集中的好友信任程度,由参与计算的好友数的倒数确定。
经过计算,将得到了一个预测的评分表。利用4.1.2节中的评价标准衡量实验结果,结果显示:本文算法的准确率P=8 0.74%,绝对误差率|E|=5.56%。
处于同一个社交网络的用户,由于在生活中频繁的交流,使得他们的业务喜好相近。通过周围好友的偏好数据,能够更加准确且合理的预测出用户偏好。试验结果表明,本文所提出的移动网络用户社会化关系挖掘算法在实践中是可行的,理论上通过对用户社会化关系的挖掘可以使推荐结果更加准确。
4.2 基于公开数据集的实验
4.2.1 公开数据集介绍公开数据集使用Filmtipset[11],Filmtipset是瑞士最大的电影推荐社区,它拥有超过90000位注册用户和两千万以上的电影评分数据。这个数据集包含:用于 Weekly Recommendation的训练集、用于圣诞周推荐任务测试集和评测集、用于奥斯卡周推荐任务的测试集和评测集;用于社会化推荐任务的训练集、测试集和评测集。本文选择其中有关1000个用户与500部电影的数据集合,并选取了这1000个用户的关系矩阵和1000个用户对500部电影的评分集。对于这些评分数据按照不同的训练集和测试集比划分,形成15组测试数据,每组测试数据包含1个训练集和1个测试集。
4.2.2 评价方法本实验使用4.1.2节中介绍的绝对误差率||来评价试验结果,对于式(17)中的参数,N表示预测结果数据量,ri表示由训练集中数据经本文算法预测得到的评分值,ti表示与ri对应的测试集评分值,rmax与rmin表示数据集中的最大与最小评分值,本实验中rmax=10,rmin=0。
4.2.3 实验描述及结果分析
(1)基于参数t%的交叉实验 使用本文提出的DSBCTF数据选取方式,将4.2.2节中的15组训练集数据随机抽取10组分别代入本文的算法进行计算,使用改进的余弦相似度计算方法,间接好友关系挖掘阈值α定为50%,当好友选取比例分别为20%,50%和70%时,||值比较如图1所示。
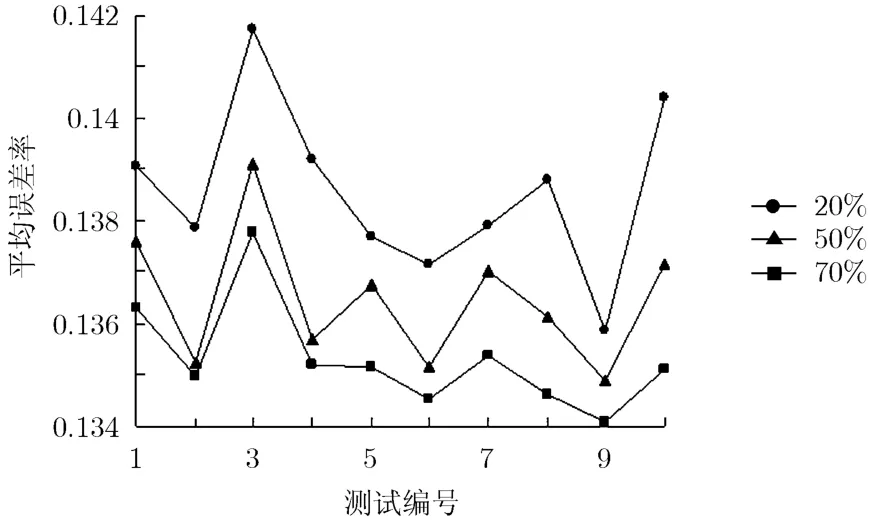
图1 不同好友数据选取比例的平均误差率比较
对于挖掘出的好友关系,仅表明他们之间的信任程度很高,但是他们的业务喜好也有可能差异很大,所以不能将这些关系全部用于预测业务评分。从这些好友关系中通过他们之间基于业务评分的相似性大小来选取部分数据,将使得推荐更加合理。选取比例决定了选取的好友数量,当参与预测的数量过少时,有可能忽略掉某些关键数据的影响,通过试验发现:当好友选取比例为70%时,平均误差率比较小,所以本文将参数t%定为70%。
(2)TDS、DSBF、DSBCTF对比实验 将4.2.2节中的15组训练集数据随机抽取10组代入本文算法进行偏好预测,其中t%的取值定为70%,间接好友关系挖掘阈值α定为50%,当选用3种不同的数据选取方式时,||值比较如图2所示。
3种算法中,从直接参与评分预测的数据量上看,DSBCTF方法所选取的数据量最多,它包含了传统基于项目评分相似性及社会化关系挖掘的用户信息,TDS,DSBF则仅有部分数据;从数据的推荐意义上看,TDS缺少了来自社会化关系挖掘的好友数据,而DSBF缺少了来自传统基于项目评分相似性的用户数据,与DSBCTF相比,这两种方法都不能较全面地预测用户项目评分。实验结果也表明:本文提出的基于用户社会化关系挖掘的混合数据选取算法(DSBCTF)性能最好,误差率最小。

图2 3种数据选取方法的性能比较
5 结论
基于移动社交网络服务现状,多数用户更相信来自真实社交网络中朋友而非系统的推荐信息,且交往密切的用户在兴趣上较为相似。本文面向移动通信网,提出一种基于移动用户社会化关系挖掘的协同过滤算法,通过对移动通信网下的社会化潜在关系进行挖掘,将好友数据融入传统的协同过滤算法中。在实验部分,首先通过一个仿真数据实验验证了该方案的可行性和有效性,然后通过公开的Filmtipset数据集实验确定了合理的参数设置,并与TDS,DSBF数据选取方法进行了性能比较。实验结果表明,本文算法不仅缓解了评分矩阵稀疏性问题,而且有效地提高了偏好预测和推荐结果的准确度。
[1]Jonna H,Albrecht S,Jani M,et al..Context-aware mobile media and social networks.Proceedings of the 11th International Conference on Human-Computer Interaction with Mobile Devices and Services,Bonn,Germany,2009:1-3.
[2]Ricci F.Mobile recommender systems.International Journal of Information Technology and Tourism,2011,12(3):205-231.
[3]Wang L C,Meng X W,Zhang Y J,et al..New approaches to mood-based hybrid collaborative filtering.Proceedings of the Workshop on Context-Aware Movie Recommendation at the 4th ACM Conference on Recommender Systems (ACM Recsys’10),Barcelona,Spain,2010:28-33.
[4]Gediminas A and Alexander T.Toward the next generation of recommender systems:a survey of the state-of-the-art and possible extensions.IEEE Transactions on Knowledge and Data Engineering,2005,17(6):152-162.
[5]方娟,梁文灿.一种基于协同过滤的网格门户推荐模型.电子与信息学报,2010,32(7):1585-1590.Fang Juan and Liang Wen-can.A grid portal recommendation model based on collaborative filtering.Journal of Electronics&Information Technology,2010,32(7):1585-1590.
[6]Matthias B and Gernot B.Improving the recommendation of mobile services by interpreting the user’s icon arrangement.Proceedings of the 11th International Conference on Human-Computer Interaction with Mobile Devices and Services,Bonn,Germany,2009:15-18.
[7]Gupta A,Kalra A,Boston D,et al..MobiSoC:a middleware for mobile social computing applications.Mobile Networks and Applications,2009,14(10):35-52.
[8]Arazy O,Kumar N,and Shapira B.Improving social recommender systems.IT Professional,2009,11(4):38-44.
[9]Dijiang H and Vetri A.Email-based social network trust.IEEE International Conference on Social Computing /IEEE International Conference on Privacy,Security,Risk and Trust,Boston,USA,2010:363-370.
[10]Herlocker J,Konstan J,Terveen L,et al..Evaluating collaborative filtering recommender systems.ACM Transactions on Information Systems,2004,22(1):20-21.
[11]Fernando D and Pedro G C.Movie recommendations based in explicit and implicit features extracted from the Filmtipset dataset.Proceedings of the Workshop on Context-Aware Movie Recommendation at the 4th ACM Conference on Recommender Systems (ACM Recsys’10),Barcelona,Spain,2010:45-52.
