居民收入样本分组数与基尼系数测算的关系探讨
2011-09-05陈建东
陈建东,戴 岱,冯 瑛
(1.西南财经大学 财税学院,成都 611130;2.西南财经大学 工商管理学院,成都 611130;3.成都电子机械高等专科学校,成都, 610031)
0 引言
衡量收入不平等的标准有很多,如泰尔-L指数、变异系数、平均离方差(又称库茨涅茨指数)和基尼系数等。不过两个最常用的标准是洛伦茨曲线和基尼系数(Sloman,2000)。而基尼系数是最重要的衡量收入不平等程度的指标(Sen,1997;Champernowne 和Cowell,1998)。意大利统计学家 Corrado Gini在1912年发表的Variability and Mutability一文中,首次提出了一种衡量不均等的指数及其计算方法。该方法后来便逐渐演变为大家熟知的基尼系数(李实,2002)。
测算基尼系数最理想的数据源就是原始的住户调查数据,根据(1)式,利用相关的软件1就能迅速准确地计算居民收入的基尼系数。(1)式中n代表人口总数(或家庭户数);u为平均收入;yi和yj分别代表第i和j居民(或家庭)的收入。

目前公开出版的相关统计年鉴有:《中国统计年鉴》、《中国城市(镇)生活与价格年鉴》、《农村住户调查年鉴》和《中国价格及城镇居民家庭收支调查统计年鉴》,后两者居民收入的分组数据和《中国统计年鉴》类似。虽然《中国城市(镇)生活与价格年鉴》提供的城镇居民分组数多于《中国统计年鉴》。但是《中国城市(镇)生活与价格年鉴》从2006年才正式出版。然而,目前公开出版的居民收入数据都是在原始住户调查数据的基础上重新按收入进行分组而得到的数据。
《中国统计年鉴》是估计我国居民收入基尼系数最主要的数据源,特别是在2000年以前没有住户调查年鉴的情况下。例如陈宗胜和周云波(陈宗胜,1999;陈宗胜和周云波,2002)就是以《中国统计年鉴》为基础并对其重新加工。但是《中国统计年鉴》中有关居民收入的数据遭到了广泛的质疑。Khan和Riskin(2001)认为《中国统计年鉴》提供的收入数据过于集中,从而影响了对收入不平等的深入分析。Fang、Zhang和Fan(2002)也认为过于集中的分组数据忽略了组内数据的差异,因此不够精确。如1996年《中国统计年鉴》提供的农村住户收入数据,人均年纯收入超过2000元的农村家庭占样本总数的38.4%,统计年鉴没有对这些农村中高收入家庭的收入进一步分组;2007年《中国统计年鉴》提供的农村住户收入数据,人均年纯收入超过5000元的农村家庭占样本总数的30.94%,统计年鉴也没有对这些农村中高收入家庭的收入进一步分组。所以,根据《中国统计年鉴》提供的数据我们只能计算出组间的收入差距,而组内的收入差距没办法计算,所以最终的结果必定被低估。
由于需要大量和复杂的统计调查,个人或非统计部门很难得到连续的有关我国居民收入的第一手数据。如果可以进入原始的住户调查数据源,利用(1)式就可以迅速准确地计算出我国居民收入的基尼系数。而在目前数据源的条件下,准确地计算中国基尼系数还需要克服很多技术问题。虽然大家都清楚目前居民收入的分组数据会导致基尼系数被低估,但是尚未发现相关文献对此给予实证的分析。另外,我们知道统计年鉴不可能提供原始的住户收入数据,但是分组数据太少如目前的5分组或7分组又不利于分析居民的收入差距。所以本文关注的是:样本收入分组数与准确测算基尼系数的关系,与此问题相联系的另一个问题是分组数多少才能比较准确地估计基尼系数。
1 分组数据对基尼系数测算的影响
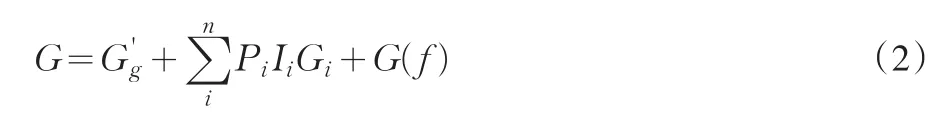
这里表示不同群体之间的基尼系数;Gi表示第i个群体内部的基尼系数;第i个群体的收入占总收入的比重为Ii,第i个群体的人口占全体人口的比重为Pi;G(f)大小取决于各个分组之间收入分布的重叠程度,只有当分组之间的收入分布完全不重叠时,该项才会等于零(Mookherjee和Shorrocks,1982;Shorrocks和 Wan,2005)。(2)式可以解释为什么运用统计年鉴的数据会低估基尼系数。《中国统计年鉴》提供的城镇和农村居民收入分组是按从低到高排序的,因此在计算城镇内部和农村内部的基尼系数时G(f)为零,但是利用《中国统计年鉴》测算城镇内部和农村内部的基尼系数时,没有办法计算各收入分组的组内收入差距,相当于省略了(2)式中的
本文利用分解基尼系数的方法来解释分组数据对基尼系数测算的影响。从不同的收入来源来分解基尼系数已为大家所熟知,而从不同的收入组来分解基尼系数相对来说则比较困难。最早从事该领域研究的是Bhattacharya和Mahalanobis(1967)。简言之,全体居民的基尼系数可以分解为:所以最终的结果必定被低估。
如果所有居民的收入按从低到高排列,则(2)式中G(f)=0,那么全体居民收入的基尼系数为:

如果所有居民的收入按从低到高排列,并且按人口平均分为两组,那么两组间居民收入的基尼系数为:

如果按人口平均分为四组,组间居民收入的基尼系数为:

(5)式中与(4)式中相同,(5)式相当于首先把全体居民按人口平均分成两组计算出两组间的基尼系数(),然后再分别计算两组组内的基尼系数
如果按人口平均分为八组,组间居民收入的基尼系数为:

如果按人口平均分为2n(n为正的偶数)组,组间居民收入的基尼系数为:


(8)式表明如果按人口平均分组,分组数每增加一倍引起的全体居民基尼系数的增加数至少以2的负1次方衰减,即随分组数的增加全体居民基尼系数也会增加,但是增幅呈收敛态势。
如果我们设定可接受的测算误差,我们就可以确定分组数的下限,如:如果样本为16等分组,基尼系数的计算误差一定小于7%(即1 24);32等分组,计算误差一定小于4%;64等分组,计算误差一定小于2%;128等分组,计算误差一定小于1%。这些误差结果都是理论上极限值,实际的误差会大大小于这些误差的上限。
2 分组数对测算基尼系数的影响的实证分析
2.1 收入分布函数的确定
为了研究分组数对最终测算结果的影响,我们通过拟合2004~2006年年我国城镇和农村居民的收入分布来观察来分组数的影响。在拟合居民收入分布之前,需要知道居民收入服从何种类型的分布函数。Slevn(1959)认为同类的群体,如农村居民,他们的收入分布可以很好地由对数正态分布(log-normal)来描述。Balintfy和Goodman(1973)强调收入分布是由一种特殊的随机过程产生的,对数正态分布可以很好地解释它。从实证的结果来看,世界银行在2006年的研究中(Lopez和Servén,2006)利用近40年包括发达国家和发展中国家的收入数据证明了收入分布服从对数正态分布。Souma(2000)通过对日本居民从1887年至1998年收入的研究,指出对数正态分布是居民收入分布的普遍结构(universal structure)。由于我国是一个典型的二元社会,城乡收入差距巨大,因此全体居民的收入分布与“哑铃型”类似。但是如果我们分别来考察城镇居民和农村居民的收入分布,我们不难发现它们仍服从服从对数正态分布。
假设城镇居民收入xi(i=12,…,n)为独立同分布随机变量,服从参数为μ和δ的对数正态分布,其密度函数为:

设μ和δ分别是对数正态分布的均值与方差(参见上式),洪兴建、李金昌(2006)已证明对收入变量x而言,若Lnx~N(μ,δ2),则基尼系数

根据(10)式,对任意δ,通过标准正态分布函数表能方便地计算出基尼系数。这里我们反其道而行之,利用国家统计局提供的城镇内部和农村内部的基尼系数和城乡居民的人均收入去找对应的μ和δ。由于Y=exp(μ+δ22),这里Y为已知的城镇或农村居民的平均收入,可以得到(11)式:

国家统计局城市社会经济调查总队和农村社会经济调查司提供了2004年到2006年城市内部和农村内部的基尼系数。我们利用Matlab编写的软件能在输入城镇内部和农村内部基尼系数后,直接计算出对应的δ值并且精确到小数点后4位。有了δ值和已知的城镇和农村居民平均收入(Y),根据(11)式可测算出μ。这样就可以得到从2004年到2006年农村居民和城镇居民收入的分布函数。接下来利用Matlab生成服从参数为μ和δ的对数正态分布的随机数,这些随机数就代表了单个居民的收入,可以近似地拟合真实的居民收入数据。在我们的实际计算中,运用Matlab生成的服从对数正态分布的随机数共计10000个,根据(1)式我们计算了在各种分组条件下城镇居民和农村居民收入的基尼系数。
在计算全国居民的基尼系数时,我们按城乡实际的人口数量来控制随机数的比率,随机数也是10000个。由于我们的目的不是为了准确测算全国居民的基尼系数,而是为了得到服从一定分布规律的随机数,我们只利用一次计算所生成的随机数。在另一项测算全国居民收入的基尼系数研究中,我们采用的是模拟100次结果的平均数。
除了上述方法,还可以通过“EM两步法”来估计参数μ和δ(邓明、杨艺,2004)。利用(11)式来测算μ和δ必须知道样本的平均收入和基尼系数,而运用“EM两步法”的前提是必须知道样本的分组数据,并且分组数不能太少,否则会影响最终结果。“EM两步法”是一种迭代方法,该方法主要用来求后验分布的众数(即最大似然估计),它的每次迭代由两步组成:E步(求期望)和M步(极大化)。记θ为未知参数,将上述E步和M步进行迭代直至‖θi+1-θi‖充分小时停止。该算法的最大优点是简单和稳定。
2.2 测算结果
根据(11)式,我们利用国家统计局城市社会经济调查总队和农村社会经济调查司提供了2004年到2006年城市内部和农村内部的基尼系数,得到了2004年至2006年我国城镇人口和农村居民收入分布的主要参数(见表1)。

表1 2004年至2006年城乡居民收入的主要参数
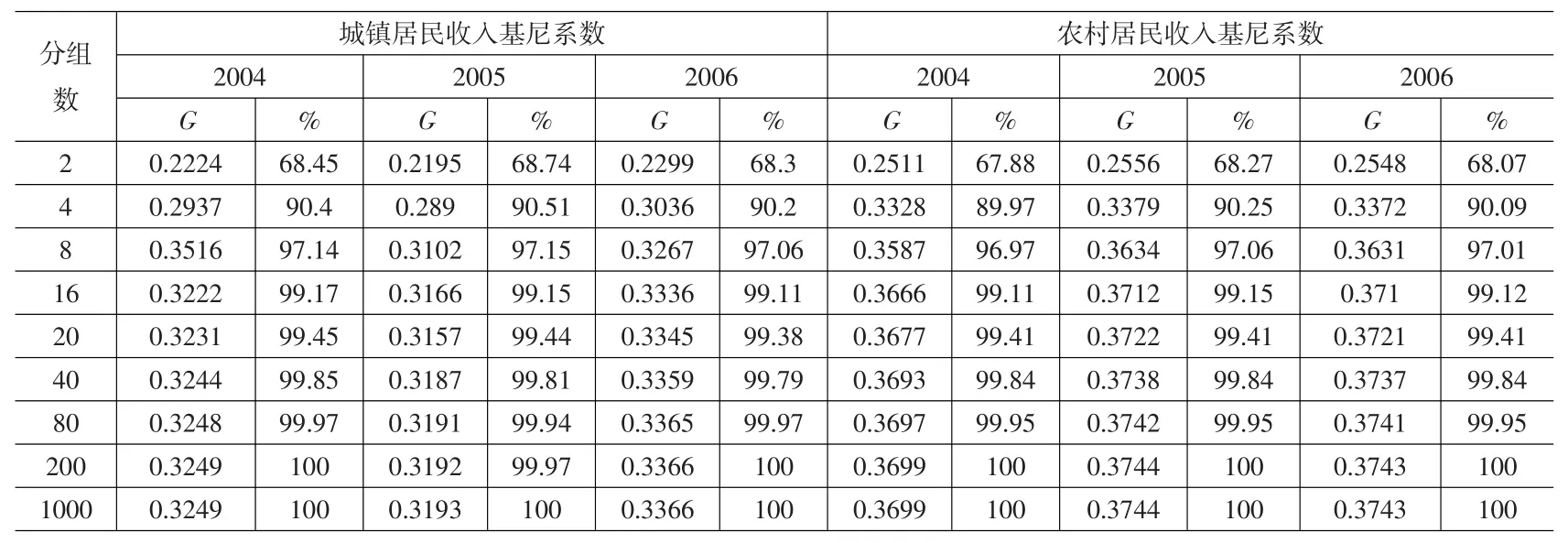
表2 不同分组数的城乡居民收入的基尼系数
根据表1,利用生成随即数的办法得到各有10000个样本的城镇居民和农村居民的收入数据,然后分别把样本等分成2组、4组、8组、16组、20组、40组、80组、200组和1000组,利用我们编制的程序分别计算了不同分组的组间基尼系数。表2是的计算结果。
式(8)表明基尼系数收敛速度与分组数之间的关系,我们列出了由于分组数增加导致的基尼系数增加的上限,而实际基尼系数的增幅应比较小。表2显示从2004年至2006年随分组数的增加,城镇居民和农村居民收入的基尼系数也在增加,但是收敛的速度更快。两分组得到的基尼系数占全体居民基尼系数的比重为2/3强;16分组得到的基尼系数占全体居民基尼系数的比重为99%;20分组得到的基尼系数占全体居民基尼系数的比重超过99%。如果以1%的误差为标准,16等分组或20等分组得到的基尼系数基本上能够反映全体城镇居民或农村居民收入的基尼系数。
测算全国居民的基尼系数的方法,不同于测算城镇居民或农村居民收入的基尼系数。以计算2006年全国居民收入基尼系数为例,2006年我国城镇居民人口比重为43.9%,根据表1中2006年城镇居民收入分布函数的参数,生成4390个随机数;同样根据表1中2006年农村居民收入分布函数的参数,生成5610个随机数。合并上述两部分随机数,我们就得到了2006年全国居民收入样本,根据该样本我们计算了各种分组情况下的基尼系数。通过表3,我们发现全国居民收入基尼系数与分组数的关系和城乡居民收入基尼系数与分组数的关系相同。如果城镇居民和农村居民的分组数都为16组或20组,则最终测算的全国基尼系数的误差小于1%。不过上述的分析都是基于服从特定参数的随即数,那么真实的情况是否也支持我们上面的分析?这里我们以2008年12月份四川省城镇居民的统计样本数据来检验分组数与基尼系数的关系,该统计样本超过10000户城镇家庭。计算结果表明2008年12月份四川省城镇居民收入的基尼系数为0.3421。在按收入从低到高排列四川省城镇居民收入数据后,我们仍然把样本按人口等分成2组、4组、8组、16组、20组、40组、80组、200组和1000组来分别计算相应的基尼系数。计算结果和基于服从特定参数的随即数得到的基尼系数基本一致,两分组得到的基尼系数占全体居民基尼系数的比重大约为2/3;16分组得到的基尼系数占全体居民基尼系数的比重大约为99%;20分组得到的基尼系数占全体居民基尼系数的比重超过99%。

表3 不同分组数的全国居民收入的基尼系数以及四川居民收入的基尼系数
综上所述,如果统计年鉴能够提供按人口等分的16组或20组居民收入的数据,那么较为准确地估计相应样本总体的基尼系数就不再是一个难题。
3 结论
我们认为目前的数据源是困扰计算我国居民收入基尼系数的根本原因。进一步,目前年鉴提供的城镇居民和农村居民分组数据太少影响了对基尼系数的准确估计。研究表明,虽然分组的增加可以提高测算基尼系数的精度,但是基尼系数的增加幅度随分组数的不断提高呈快速收敛趋势。通过实证分析,我们认为如果能够提供16或20按人口等分组的收入数据,就可以比较准确地测算样本总体的基尼系数。因此建议统计部门提供更为详细的居民收入分组数据。同时我们建议为了克服数据源的限制,目前还需要从测算手段上进行突破。本文通过反推城镇居民和农村居民收入分布函数的方法尝试提出了测算全国居民收入基尼系数的新方法。
[1]陈宗胜.改革、发展与收入分配[M].上海:复旦大学出版社,1999.
[2]陈宗胜,周云波.再论改革与发展中的收入分配-中国发生两极分化了吗?[M].北京:经济科学出版社,2002.
[3]邓明,杨艺.基于分组数据的对数正态分布的参数估计[J].系统工程理论方法应用,2004,(6).
[4]国家统计局.中国统计年鉴[M].北京:中国统计出版社,2005~2007.
[5]国家统计局城市社会经济调查总队.中国城市(镇)生活与价格年鉴[M].北京:中国统计出版社,2006~2007.
[6]洪兴建,李金昌.关于基尼系数若干问题的再研究—与部分学者商榷[J].数量经济技术经济研究,2006,(2).
[7]李实.对基尼系数估算与分解的进一步说明[J].经济研究,2002,(5).
[8]Balintfy,L,Goodman,S.Socio-Economic Factors in Income Inequality:A Log-Normal Hypothesis[J].Zeitschrift fiir Nationalokonomie,1973,(33).
[9]Bhattacharya,N.,Mahalanobis,B.Regional Disparities in Household Consumption in India[J].Journal of the American Statistical Association,1967,(62).
[10]Champernowne,D.,Cowell,F.Economic Inequality and Income Distribution[M].Cambridge:Cambridge University Press,1998.
[11]Khan,A.,Riskin,C.Inequality and Poverty in China in the Age of Globalisation[M].Oxford:Oxford University Press,2001.
[12]Lambert,P,Aronson,R.Inequality Decomposition Analysis and the Gini Coefficient Revisited[J].The Economic Journal,1993,(103).
