基于蚁群模糊聚类的协同过滤推荐算法
2011-08-11黄金凤雷筱珍
黄金凤,雷筱珍
(福建交通职业技术学院 信息系,福州350007)
0 引 言
企业通过电子商务网站能增强自身的竞争优势,个人通过使用电子商务网站能感受到足不出户购物的方便与快乐.但是电子商务网站存在一个亟待解决的问题:推荐适合当前浏览用户的商品给该浏览用户,从而避免用户由于在过多的商品中找到自己所需商品过于耗时耗力而离开.电子商务推荐系统就是解决此类问题的解决方案.许多大型电子商务网站早已开始使用电子商务推荐系统,如Amazon、当当网等.
在推荐系统中,协同过滤(Collaborative Filtering,CF)正迅速成为一项很受欢迎的技术.协同过滤分析用户兴趣,即用户会对邻居所喜欢的商品产生兴趣.在用户群中找到指定用户的相似兴趣用户,即邻居用户,综合这些邻居用户对某一项目的评价,形成系统对该指定用户对此项目的喜好程度预测,进而将预测评价最好的前N项商品推荐给该指定用户.
当网站的用户和项目数量增加时,CF的算法复杂度迅速递增,从而使得系统推荐性能不断下降,最终影响推荐的及时性[1][2].正是鉴于该问题,本文提出了基于蚁群模糊聚类的协同过滤推荐算法(CF-based ACVC,Collaborative filtering recommendation algorithm based on Ant Colony Vague clustering).基本思想是分先离线再在线两阶段.离线时利用蚁群模糊聚类算法对用户进行聚类,生成若干用户聚类中心,再计算每个用户和各聚类中心的相似性以得到相似性度量矩阵;在线时计算目标用户与各聚类中心的相似性,再以此搜索相似性度量矩阵找到其最近邻居并进行评论预测,最后生成推荐.同时,仿真实验结果表明,本算法在一定程度上提高了推荐速度和质量.
1 协同过滤算法
协同过滤算法是基于评分相似的最近邻居的评分数据向目标用户产生推荐.目标用户对未评分项目的评分可以通过最近邻居对该项目评分的加权平均值逼近.它通过构造用户对项目的偏好数据集来实现.
算法1协同过滤算法
协同过滤算法的输入数据通常表述为一个m×n的用户-项目评价矩阵R(m,n),其中m行表示m 个用户,n列表示n个项目,矩阵元素Ri,j表示用户i对项目j的评估值.
首先,计算每个用户对以往评价过的信息资源项目的平均打分:

其中,Iu为用户u的评分向量,|Iu|为Iu的长度,即用户打过分的数字资源数目,Ruj表示用户u对项目j的评分.
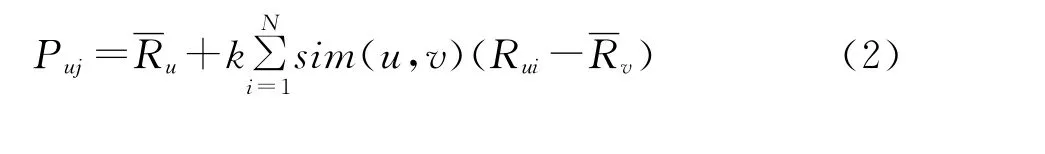
其次,计算目标用户对未评价过的信息资源项目的预测评分值:其中,Puj为目标用户u对信息资源项j的预测值.算法根据与目标用户相似的N个用户的评价进行预测,并非所有用户都参与预测Puj值,sim(u,v)为用户u和v之间的兴趣相似度,k为归一化因子.
算法的核心部分是计算用户的兴趣相似度sim(u,v),相似度量方法主要有三种:余弦相似性、相关相似性及修正的余弦相似性.鉴于文献[4]的结论,我们选择选用Pearson相关相似性度量作为本文的用户相似性度量方式.
设I表示用户u、v的共同评分项集,则用户u、v之间的相似性sim(u,v)通过Pearson度量,其计算公式:

最后,按Pu,i值从大到小取前N 个项目组成推荐集Irec={i1,i2…iN}推荐给用户u,从而完成整个推荐过程.
2 蚁群模糊聚类算法
聚类是基于“物以类聚”的思想,实质是依据项目在属性特征上的相似性对项目进行分类,将相似性高的项目归为一类,而不同类的项目之间的相似性低.FCM算法[4]是一种基于划分的在模糊集理论上的聚类算法.
蚂蚁觅食过程中,信息传递主要是通过信息素扩散完成的,是以信息素来决定蚂蚁的运动方向.先前蚂蚁对后面蚂蚁的行为发生影响时,后面蚂蚁一般不在先前蚂蚁的运动轨迹上,而是与该运动轨迹有着或大或小的距离.当距离比较小时,后面蚂蚁的行为受影响较大,这一特点对数据聚类是十分有用的.本文借鉴这一原理及文献[5],提出一种蚁群模糊聚类(基于蚁群算法的模糊聚类)算法.
该算法将数据对象视为具有不同属性的蚂蚁,聚类中心看作是蚂蚁所要寻找的“食物源”,这样,数据聚类过程就可以被看作是蚂蚁寻找食物的过程.
算法的思想是:在蚂蚁从食物源i到食物源j的过程中,如果找到合适的路径(子解),它就释放出相应浓度的信息素,该信息素一方面直接影响位于子解的两个聚类中心上的蚂蚁,另一方面它会以该路径为中心向外扩散,影响附近其他蚂蚁的行为,使它们在寻找路径时以更大的概率在下一步选择此路径[6].通过这种基于信息素的协作方式,其他数据对象在选择聚类中心时所受的干扰会减小,从而可提高算法的收敛速度.数据对象的归属根据转移概率的大小来决定;在下一轮循环中,引入聚类偏差的衡量标准,更新聚类中心,计算偏差,再次判断,直到偏差没有变化或在一定误差范围内,算法结束.
算法2 蚁群模糊聚类算法
令:X={Xi|Xi=(Xi1,Xi2,…,Xin),i=1,2,…,n}是待聚类的数据集合:
令:dij=‖P(Xi-Yi)‖2中,dij表示Xi到Yi之间的加权欧氏距离;P为权因子,可以根据各分量在聚类中的贡献不同而定.
t时刻,对于其他数据对象l,第k只蚂蚁从i到食物源j(聚类中心)的路径(i,j)上的信息素量(t)(如式(4)),此时,蚂蚁将分别以i和j为中心以r为半径向周围扩散信息素,则数据对象l由蚂蚁k所产生的信息量)定义为[69]:

以i为中心向周围扩散信息素,数据对象l由蚂蚁k所产生的信息量Δ(t)为:

以j为中心向周围扩散信息素,数据对象l由蚂蚁k所产生的信息量Δ(t)为:

数据对象Xi是否归并到聚类中心由转移概率Pij决定:

其中,S={Xs|dsj≤R,s=1,2,…,n},表示分布在聚类中心领域内的数据对象的集合;α表示残留信息的相对重要程度,β期望值的相对重要程度,ηij为t时刻蚂蚁由城市i选择城市j的某种启发信息.若Pij(t)≥P0(P0为一设定值),则 Xi归并到;否则,不归并.
令:CSj={Xi|dij≤R,i=1,2,…,J},表示所有归并到聚类中心Cj的数据对象的集合,J为该集合中数据对象的个数.根据公式(8)和公式(9)分别计算新的聚类中心和隶属矩阵ujl.第j个聚类的偏离误差εJ及此次分析的总体误差ε分别由公式(10)和公式(11)给出.

算法的伪代码如下:

算法的输出是K个聚类中心点向量和K*N的一个模糊划分矩阵,这个矩阵表示的是每个样本点属于每个类的隶属度.根据这个划分矩阵按照模糊集合中的最大隶属原则就能够确定每个样本点归为哪个类.聚类中心表示的是每个类的平均特征,可以认为是这个类的代表点.
3 基于蚁群模糊聚类的协同过滤算法(CF-based ACVC)
离线阶段,先对用户进行蚁群模糊聚类,产生若干聚类中心和一个类别隶属矩阵,这个矩阵表示每个用户属于每个类的隶属度.根据这个划分矩阵按照模糊集合中的最大隶属原则就能获得用户与聚类中心的相似性度量矩阵.在线阶段,只要计算目标用户与各个聚类中心的相似性,再通过对比离线时获得的相似性度量搜索矩阵搜索目标用户的最近邻居,并产生推荐.基于聚类的实质,离线阶段获得的聚类数目远远小于用户数目,在线阶段系统只需计算目标用户与少量的聚类中心的相似性,因此,提高了推荐的实时性.
3.1 离线时的蚁群模糊聚类
先用公式(3)代替蚁群模糊聚类算法中的公式(9)的右半部分计算隶属矩阵μjl,再利用算法2获得用户聚类中心C(k,n)以及每个用户属于每个类的隶属度矩阵U(k,n).
用户聚类中心C(k,n)表示n个项目的k个聚类中心,其元素cij表示用户聚类中心i对项目j的评分,也是第i类中的所有用户对项目j的平均评分.
基本用户的类别隶属度矩阵U(k,n)表示k个基本用户的n个用户聚类,其元素uij表示用户i对聚类中心j的相似性,即用户i和第j个用户聚类中心之间的Pearson相关相似性度量.
3.2 在线时查找目标用户的最近邻居并产生推荐
在离线处理结果的基础上,在线阶段,利用算法1完成整个推荐过程.
4 仿真实验及分析
通过仿真实验验证本文提出的算法,并文献[2]的算法进行了比较.
4.1 实验环境及实验数据集
实验所用PC机的配置为Intel(R)Core(TM)2Duo CPU T9550 2.66GHz、2GB RAM,Windows XP操作系统,Access数据库,算法用Matlab实现.
实验数据集采用 MovieLens数据集[8].MovieLens数据库集是美国Minnesota大学GroupLens项目组提供的,用于接收用户对电影的评分并提供相应的电影推荐列表.该数据集包含了943位用户对1682部电影作出的1000000条评分数据,分为5个base数据集和5个test数据集.我们使用十折交叉验证(10-fold cross-validation)方法进行实验.每次选择一对base数据集和test数据集,使用base数据集中的记录作为基本用户,对test数据集中的目标用户进行推荐测试.
4.2 评价标准
实验采用统计精度度量方法中广泛使用的平均绝对误差MAE(Mean Absolute Error)来衡量算法的预测精度.MAE是测试集中所有用户对资源打分的实际值与预测值的偏差的绝对值的平均[8].MAE值越小,说明推荐算法的预测精度越高.
4.3 实验结果及分析
为了验证本文提出算法的有效性,我们进行了仿真实验并与文献[2]的算法进行了对比.
在对MovieLens数据集的数据的预处理过程中,我们发现原始类别的前7类中,每个原始类别都包含相对较多的基本用户,而其他类则包含相对少量的用户,所以在验证本文算法时,我们取聚类数目k的值为7.采用最近邻用户数K分别取10、15、20、25、30、35、40,用户相似性度量方法采用Pearson相关系数,运行本文提出的算法CF-based ACVC和文献[2]的算法(IRP-CF),计算在不同最近邻用户数时两种算法各自的MAE.实验结果如图1所示.

图1 两种算法的评分预测质量比较
由图1可知CF-based ACVC具有更小的MAE
5 结 论
由前文对CF-based ACVC算法的分析可知,传统协同过滤算法是直接计算目标用户与所有的m个基本用户之间的相似性,而本文算法首先计算目标用户与基本用户聚类中心之间的相似性,基本用户聚类中心的个数相比于所有基本用户是小了很多,所以本文提出的算法提高了在线搜索目标用户的最近邻居的速度,从而在一定程度上提高了推荐系统的实时性.实验结果表明,本文算法在一定程度上提高了在线时的推荐生成速度,同时推荐质量也有一定的提高.实验结果还表明对于离线时基本用户的聚类,虽然我们并没有特别要求,比如聚类过程中k的选取等,CF-based ACVC仍然能够在一定程度上加快推荐产生速度.
[1] 邓爱林,左子叶,朱扬勇.基于项目聚类的协同过滤推荐算法[J].小型微型计算机系统,2004,25(9):1665-1670.
[2] B M Sarwar.Sparsity,Scalability,and Distribution in Recommender system[D].Minneapolis,MN:University of Minnesota,2001.
[3] H J Ahn.A New Similarity Measure for Collaborative Filtering to Alleviate the New User Cold-starting Problem[J].Inforamtion Sciences,2008,178(1):37-51.
[4] KANADE PM,HALL LO.Fuzzy Ants as a Cluste-ring Concept[A].Proceedings of the 22nd Interna-tional Conference of the North American Fuzzy In-formation Processing Society[C].USA,2003:227-232.
[5] 姜长元.基于混合信息素递减的蚁群算法[J].计算机工程与应用,2007,43(32):62-64.
[6] 马溪骏,潘若愚,杨善林.基于信息素递减的蚁群算法[J].系统仿真学报,2006,18(11):3297-3300.
[7] http://www.grouplens.org/node/73[EB/OL].
[8] Mobasher B,Jin X,Zhou Y Z.Semantically Enhanced Collaborative Filtering on the Web,Springer-Verlag,2004:57-76.
