改进的移动网络数据业务忙时检测算法
2011-08-11刘俊霞贾振红覃锡忠
刘俊霞, 贾振红, 覃锡忠, 常 春, 王 浩
(①新疆大学 信息与工程学院,新疆 乌鲁木齐 830046;②中国移动通信集团新疆分公司,新疆 乌鲁木齐 830000;③新疆机电职业技术学院,新疆 乌鲁木齐 830011)
0 引言
由于无线频谱资源有限,移动网络中每个基站可用的载频数受限,该区域内的用户使用网络资源的时间又相对集中,因此,在GSM网络中存在相当多的忙时、忙点、忙区,特别是在推出(E)GPRS服务后,使这个问题变得更加突出。网络忙时和小区忙时,基站忙时和移动交换中心忙时,不同小区的忙时是不同的;无线网络是以满足全网忙时话务量需求为目标进行规划和建设的,故正确的忙时检测显得尤为重要。
1 忙时检测算法

其中m是测试次数,NX是X取离散值的个数,RU(X)的取值为[0,1],m>NX,当RU(X)=0时表示X是常量,其分布具有显著特征,当RU(X)=1时表明X服从均匀分布[1-4]。
文献[4]用上述相对熵理论检测EDGE网络忙时,取某个特定的时间测量网络的用户数X,计算RU(X)的值,分析X的分布特性。该方法中相对熵RU(X)公式(1)的计算结果受观测次数m的影响,若则当且仅当时,RU(X)=1,此时X的分布具有最大的不确定性,并不是我们检测忙时所要的。因此只有当m>NX时,相对熵理论才能用于检测忙时,此方法受观测次数的影响,具有一定的局限性。
2 改进的忙时检测算法
改进算法采用相对条件熵
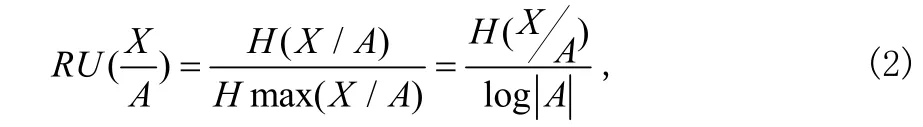
在(E)GPRS网络中,X是具有一维特征的观测变量,是不同时刻的用户数,A是X取特定值的集合。令是采样次数,mi是ai在m次采样中出现的次数;让
将采样数据值,分成2类S和R。S是A的子集,S中所有元素均大于R中所有元素,是的最小整数,则S中的元素的分布具有忙时特性,R中元素的分布接近均匀分布,无忙时特性。所以S中的元素即为检测出的忙时。
3 案例分析
数据从移动现网某小区提取,利用改进的忙时检测算法检测出该小区忙时是23点、0点和1点。
若将该小区的吞吐量值从现网数据中提取,可以得到如图1所示。
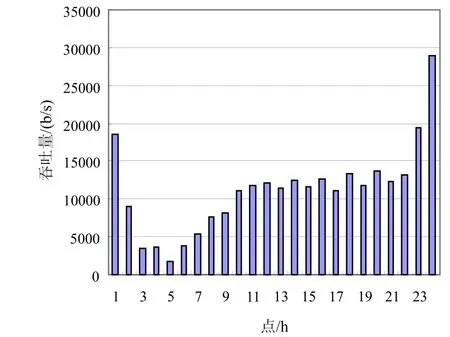
图1 现网某小区一周内24小时的平均吞吐量
可以看出吞吐量最大的时间是23点,0点和1点,与用本文采用的基于条件相对熵忙时检测算法结果是一致的,证明了该算法的有效性。
4 结语
无线网络是以满足全网忙时话务量需求为目标进行规划和建设的,故忙时检测在数据网络中变得越来越重要,本文将忙时算法进行改进可以准确的管理并检测出数据网络的忙时,不仅可以提高载频利用率还能更合理的分配网络资源,从而为网络优化提供依据。
[1]冯桂,林其伟,陈东华.信息论与编码技术[M].北京:清华大学出版社,2007:20-21.
[2]THOMAS M, CORER J, THOMAAS A.信息论基础[M].北京:机械工业出版社,2008:2-3.
[3]贾世楼,信息论基础[M].第 2版.哈尔滨:哈尔滨工业大学出版社,2004:35-36.
[4]LIU Lu, ZHOU Wenan, MA Fei, et al. QOE-oriented EDGE Network Busy Time Detection and Analysis[C].USA:IEEE International Conference on.,2009:232-236.
[5]XU Kuai, ZHANG Zhili, SUPRATIK Bhattacharyya. Profiling Internet Backbone Traffic: Behavior Models and Applications[C]. USA, Proceedings of the 2005 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications,2005: 169-180.
