基于声学统计建模的语音合成技术研究
2011-06-28凌震华王仁华戴礼荣
胡 郁,凌震华,王仁华,戴礼荣
(中国科学技术大学 讯飞语音实验室, 安徽 合肥 230027)
1 引言
语音合成又称文语转换(text-to-speech, TTS),是智能人机语音交互领域的一个重要研究方向,其研究历史可以追溯到18世纪,并经历了从机械装置合成、电子器件合成到基于计算机技术的语音合成的漫长发展阶段。从历史发展来看,最为常见的语音合成方法主要包括两种。一种方法是基于原始发音的单元挑选与波形拼接合成,通过学习自然语音中的规律寻找合成单元(一般为音素级)之间的拼接规律,拼接原始语音波形单元得到合成语音;一种方法是对语音信号的音段和超音段特征进行建模,利用语音合成器通过建模得到的参数控制产生合成语音。这两种方法在近20年来伴随着大数据量信息处理技术和统计信号处理建模技术的发展都取得了显著的进步,并利用其各自的特点在不同领域取得了很好的效果。
基于大语料库的单元挑选与波形拼接合成技术是随着20世纪90年代电子计算机的运算和存储能力的迅猛发展而逐渐成熟的,是波形拼接语音合成技术的最新进展。其基本思想是根据输入的文本分析信息,从预先录制和标注好的连续自然发音语音库中挑选合适的单元,进行少量的调整(或者不进行调整),然后拼接得到最终的合成语音[1-4]。由于最终的合成单元都是直接复制于录音音库,该方法可以保持原始发音人的音质,实现高自然度的语音合成。这种方法的优点是合成语音音质高,音色相似性好,较好的学习了自然发音中的自然韵律信息从而自然度较高,缺点是需要规模较大的语音数据库支撑,同时系统的稳定性有所欠缺,在给出高自然度合成语音的同时,可能会产生一些效果较差的合成语音结果。而在参数语音合成方面,在经历过共振峰合成器语音合成系统的发展以后,20世纪末,随着语音信号统计建模方法的日益成熟,基于统计声学建模的语音合成方法被提出,它将参数语音合成技术推进到了一个新的发展阶段。由于此方法可以实现系统的自动训练与构建,所以又被称为可训练的语音合成(Trainable TTS)[5]。其基本思想是基于统计建模和机器学习的方法,根据一定的语音数据训练声学模型并快速构建合成系统。Trainable TTS有多种实现形式,基于隐马尔可夫模型(hidden Markov model, HMM)的参数语音合成方法是其中的典型代表[6]。这种方法的优点是系统稳定性好,在超音段和音段方面可以稳定持续的以固定风格合成语句,系统需要的数据和资源容量较小,可以方便的进行音色等各方面的调整等; 缺点是合成语音的音质较差,而且在自然度表现方面比较呆板,合成语音表现力较差。
进入21世纪以后,国际语音合成领域的各主要研究单位在以上两个语音合成技术方向进行了大量的研究工作,并取得了一系列的进展。我们在这两个方面分别提出了针对中文、英文的技术与系统实现方案[7-13],并前瞻性地提出了将两种方法相互融合的新思路,形成了基于声学统计建模的语音合成技术与系统,融合了隐马尔可夫模型参数训练新方法,发音动作参数与声学参数综合建模,统计模型指导单元挑选与波形拼接等多项关键技术。基于这些新技术的语音合成系统在国际语音合成技术评测中保持了优异的成绩,有效地验证了新方法的领先性能。
本文首先简要回顾基于HMM的参数语音合成方法,并分析其技术特点;然后在此基础上,结合我们的实际工作,介绍基于声学统计建模的语音合成技术的最新进展。
2 基于HMM的参数语音合成
2.1 基于HMM的参数语音合成基本原理
图1为基于HMM的参数语音合成系统的基本框架,它主要包括训练和合成两部分。在训练阶段,首先通过参数分析算法从训练数据的语音文件中提取各帧对应的D维声学参数ct∈D,作为静态的观测特征,包括基频和频谱参数等;在静态特征基础上,通过计算相邻帧间的一阶与二阶差分,得到各帧完整的观测特征向量3D。然后以训练数据对应模型的似然值函数P(o|λ)最大为准则,训练一组上下文相关音素的HMM模型λ。这里,表示观测特征序列,(·)T表示矩阵转置,N表示序列的长度。在模型训练过程中,使用多空间概率分布(MSD)[14]对基频在清音段的缺失现象进行合理建模;基于最小描述长度(minimum description length, MDL)准则[15]训练决策树对上下文扩展后的模型进行聚类,以提高在数据稀疏情况下训练得到模型参数的鲁棒性并防止过训练;最后,使用训练得到的上下文相关HMM进行状态切分并且训练状态的时长概率模型[16]。
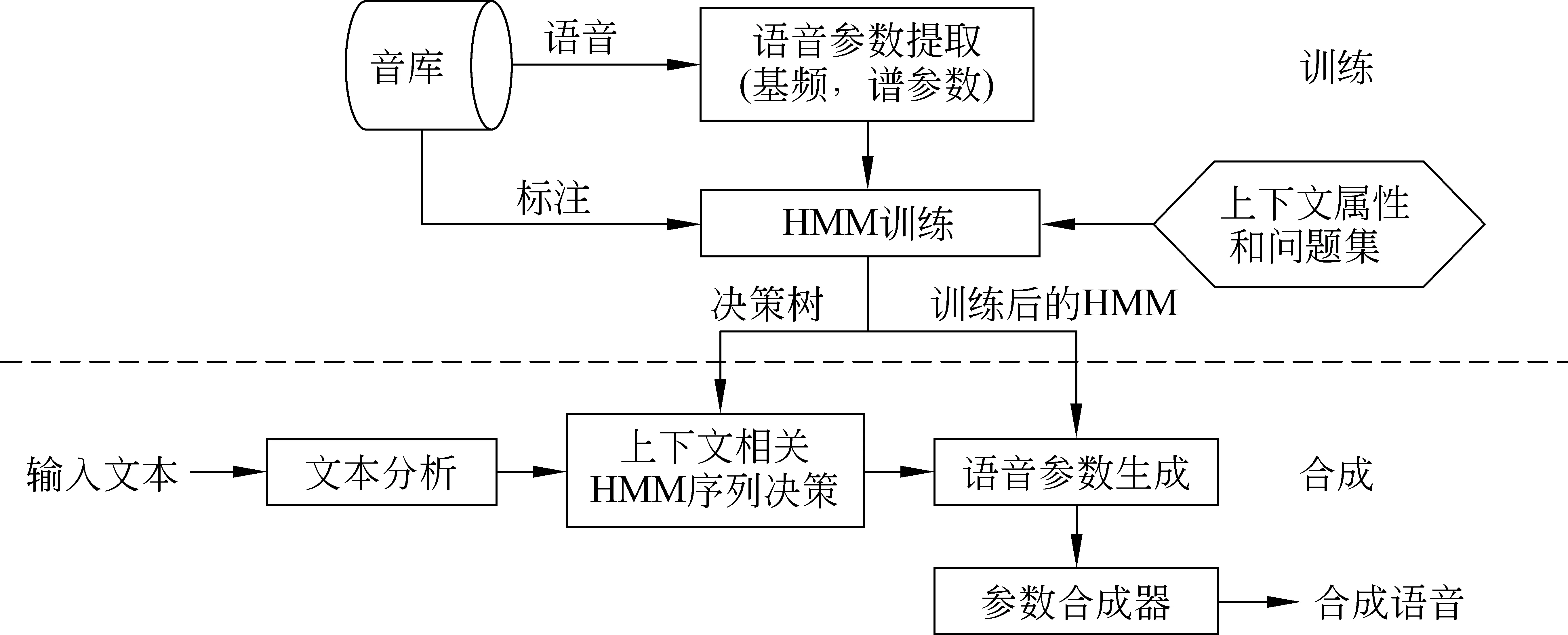
图1 基于HMM的参数语音合成系统框架
合成过程中,首先是对输入文本进行分析,得到各音素相应的上下文属性;根据这些属性分别通过时长、基频和谱参数的聚类决策树进行决策,得到待合成语句对应的HMM模型;然后,基于最大似然准则(maximum likelihood, ML)并使用动态参数约束来生成最优静态特征向量
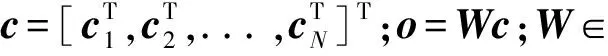
2.2 特点分析
基于HMM的参数语音合成方法所采用的统计建模、特征预测、参数合成的合成方法与传统的单元挑选与波形拼接合成方法有很大差异,我们对其技术优势与不足分析如下。
2.2.1 优势
1) 快速、自动的系统构建。其模型训练以及合成过程都是自动实现的,系统构建周期短,需要的人工干预很少;系统中绝大部分模块都是语种无关的。传统的单元挑选与波形拼接合成方法,则需要较多语种相关的专家知识进行人工调整其中的代价函数。
2) 合成语音平滑流畅,鲁棒性高。由于采用了基于统计模型的参数预测方法和基于合成器的语音恢复,合成语音比单元挑选与波形拼接合成方法更加平滑,韵律也更加流畅,不容易发生拼接合成中常见的基频不稳定现象,对不同领域文本的适应性也很强。
3) 系统构建需要的数据量少。常见的大语料库合成系统,往往会使用5~10小时,甚至更大规模的音库以保证合成语音的效果,造成在音库制作上的投入需要很大,限制了合成系统中的音色数目。而基于HMM的参数语音合成系统,一般只需要1小时的音库就可以合成出良好的语音,在降低系统成本上具有明显的优势。
4) 系统存储尺寸小。对于单元挑选与波形拼接合成方法,由于需要保留语料库的原始波形供合成时使用,因此整个系统的存储尺寸难以降低到很低的水平;而HMM参数合成方法在合成时不需要使用原始波形,只需使用训练得到的模型参数,这样,这个系统的尺寸可以控制在1MB以内,非常适合在资源受限的嵌入式设备上使用。
5) 系统灵活度高。对于传统的单元挑选与波形拼接合成方法,如果我们要改变发音者的音色或者实现不同风格的合成效果,往往意味着需要重新进行整个音库的录制,费时费力;而对基于HMM的参数合成方法,可以利用少量的目标发音人数据(如5~100句话),通过多种模型自适应或者模型内插的方法[18-20],实现需要的发音人音色或发音风格。
2.2.2 不足
1) 合成语音的音质不高。由于在基于HMM的参数语音合成方法中,最终的合成语音是通过参数合成器生成的,容易造成合成语音的音质受损;此外,统计建模过程中的平滑效应会进一步模糊合成语音的共振峰被,降低语音合成的清晰度。
2) 合成语音的韵律过于平淡。前面已经提到,基于统计建模的基频、时长预测方法使得合成语音的韵律特征很稳定,出错的几率很小;但也会造成合成语音中的韵律变化不够丰富,语句过于平淡,时间长了听者容易产生疲劳感。
3) 对数据的依赖性。虽然基于HMM的参数语音合成方法相比传统的基于语料库的单元挑选与拼接合成算法对于数据的依赖性已经大大减小,但是它从本质上说仍然是一种数据驱动的方法,不能摆脱其对数据的依赖,而一些语音学的规则很难被结合到这种针对声学参数的统计框架中。
3 基于统计建模的语音合成技术进展
针对上面提到的基于HMM的参数语音合成技术中存在的缺陷, 本节将重点介绍中国科学技术大学讯飞语音实验室近年来在基于统计建模的语音合成技术方面的主要研究进展及成果,包括以下几个方面。
1) 特征融合。首次在合成中将声学特征与描述语音产生机理的发音动作特征相结合,以期提高声学参数预测的灵活性和有效性。
2) 模型训练准则。提出以最小生成误差(minimum generation error, MGE)准则取代常用的最大似然准则,减小预测声学参数的误差,提高了合成语音的音质。
3) 波形生成方法。提出了一种新的基于HMM 的单元挑选合成方法。这种方法使用概率统计准则指导单元挑选,拼接自然波形生成语音信号,从根本上改善了参数语音合成中由于建模时的平均效应以及合成器的性能的限制造成的生成语音音质的不足。
3.1 发音动作参数与声学参数的融合
3.1.1 算法提出
在基于HMM的参数语音合成方法中,一般只使用声学参数来作为表征语音的观测值以及建模的对象。实际上,声学参数并不是语音特征唯一的表征形式,发音动作参数[21-23]同样也是一种有效的语音描述方法。这里“发音动作参数”指的是对说话人在发音过程中使用的发音器官位置以及运动情况的定量描述。这些发音器官包括: 舌、下腭、嘴唇、软腭等。目前可以通过多种技术来收集这些发音动作参数,例如,电磁发音仪(electromagnetic articulography,EMA)、磁共振成像(magnetic resonance imaging,MRI)、超声波等。因为声学信号是由发音器官的运动产生的,所以声学参数和发音动作参数是彼此相关的。此外,语音产生的物理机理也决定了发音动作参数相对声学参数具有变化缓慢平滑、描述语音特征直接简便、噪声鲁棒性强等优点。
基于发音动作参数的这些优点,已有一些研究者将发音动作参数应用到基于HMM的自动语音识别中,并且在降低识别错误率方面取得了一些积极的效果[24-25]。我们首次尝试将发音动作参数应用到基于HMM的参数语音合成中,实现其与声学参数的联合建模与生成[21-22]。这样既使统计模型更加精确, 降低生成的声学参数的预测误差,又可以依据语音学规则方便地调整发音动作参数, 改变合成语音特征,提高了合成系统灵活性。
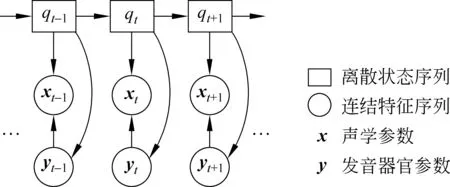
图2 声学参数/发音动作参数联合建模时的生成模型结构
3.1.2 实现方法
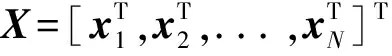
其中N(;μ,Σ)表示均值向量和协方差矩阵分别为μ和Σ的正态分布;Aj是从发音动作参数到声学参数的转换矩阵,表示在状态j上后者对前者依赖关系。我们可以使用EM算法[26]通过迭代更新的方法实现对模型参数的估计。
在合成时,同样基于最大似然准则,并且考虑动态参数的约束,以同时生成声学参数和发音动作参数,表达如下

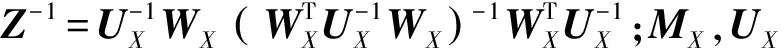
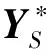
为了改善调整后发音动作参数与上下文相关转换矩阵Aj的失配问题,我们又提出了特征域转换矩阵绑定方法[23],对声学参数与发音动作参数之间的相关性进行了更加合理的描述,进一步提升了发音动作参数对声学参数生成的控制能力。
3.1.3 评测实验
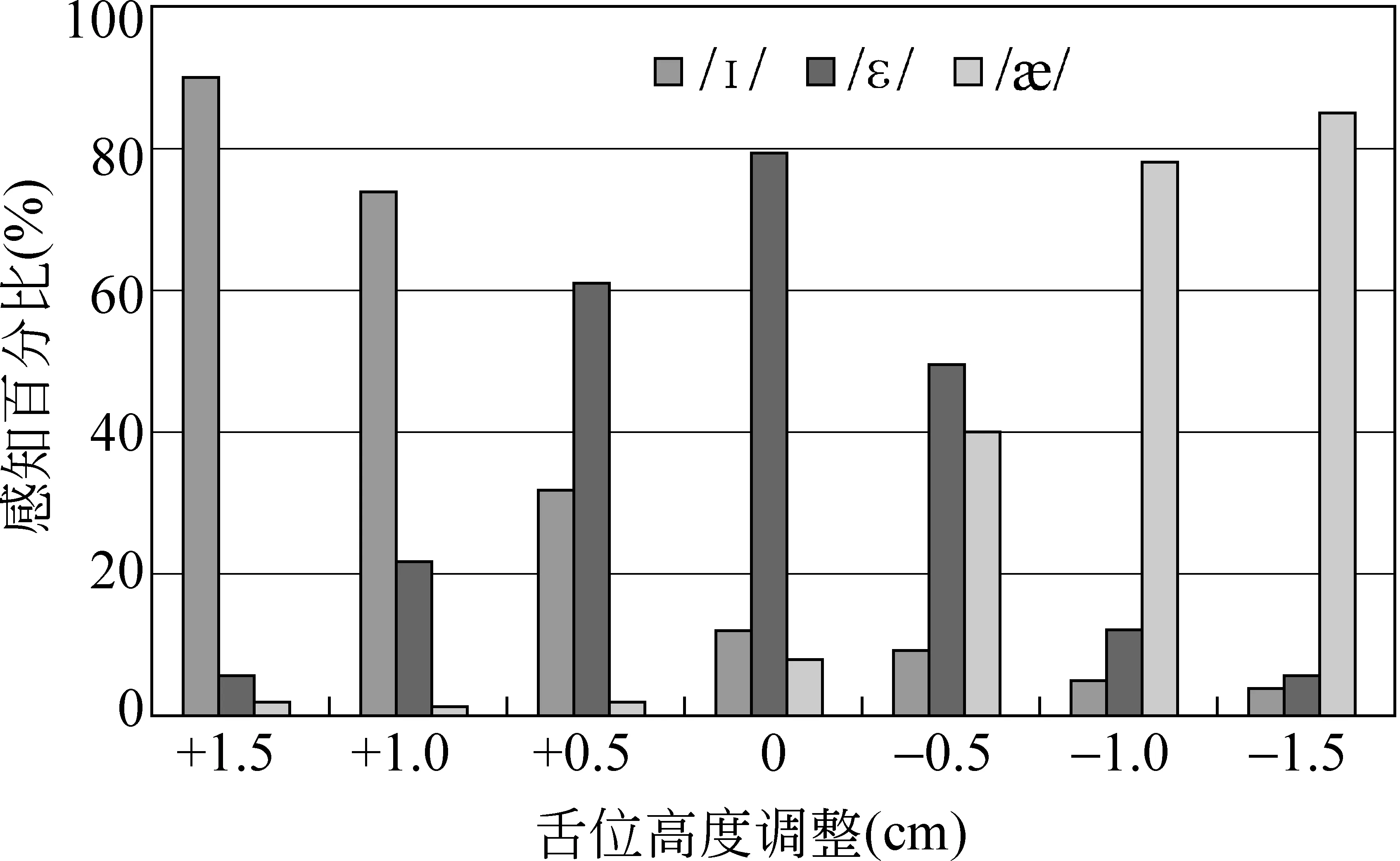
图3 通过EMA参数调整舌位高低后合成元音/ε/的感知测听结果
我们使用了一个双通道的英文语音数据库进行相关的实验验证工作[21-22],它同时采集了录音时的声学波形信号和电磁发音仪(EMA)信号。整个语音库包括音素平衡的1 263句话,由一名英式发音的男发音人朗读。波形录制使用16kHz采样,16bit量化的PCM格式,我们将从中提取的由STRAIGHT[27]谱包络导出的40阶线谱对(Line Spectral Pairs, LSP)和1维增益作为频谱参数。EMA数据的采集是通过在发音人的各发音器官上放置小的传感器,并利用电磁信号对发音过程中各传感器进行三维定位来实现的。实际使用了6个传感器,其具体摆放位置包括舌根、舌尖、舌面、下腭、上唇和下唇[22]。在实验中我们只使用各传感器y维(从前到后方向)和z维(从上到下方向)的位置信息,即一共得到12维的静态发音动作特征。对于声学参数和发音动作参数,我们依据图2所示的结构进行模型的训练,并且在合成过程中,测试了不同的调整函数f(·)对于合成语音特征的控制能力[21-22]。其中,我们进行了一个主观的感知测试以证明这种使用语音学规则的发音动作参数调整方法在控制合成语音中特定音素音色方面的能力[15]。实验中,使用了英语中的三个前元音/I/、/ε/ 和 //。这三个元音在发音上的最大区别就是舌位的高低。元音/I/ 对应的舌位最高,//对应的舌位最低,而/ε/在两者之间。在这个实验中,我们定义调整函数f(·)为调整舌根、舌面、舌尖上三个传感器的z坐标位置来模拟对于舌位高度的控制。正的调整表示升高舌位,而负的调整表示降低舌位。我们使用的测试文本为5个包含元音/ε/的单音素单词("bet"、"hem"、"led"、"peck"、"set"),并且将这些单词放入承载句"Now we’ll say ... again"中进行合成。对合成过程中舌位高度的调整为-1.5cm~1.5cm,每0.5cm合成一组语音,一共得到35个合成样本。在进行测听实验时,由20名英语母语的发音人参与,每名发音人对每句合成语音进行听写,记录下承载句中的核心单词。然后,对每一个调整距离,统计合成的元音被感知成/I/, /ε/ 和 //的比例如图3所示。从图中可以清晰地显示出,随着我们升高舌位,合成元音会逐步从/ε/变化为/I/;反之,如果我们降低舌位,元音会被从/ε/感知为//。这进一步验证了结合发音动作参数后,我们可以有效利用语音学规则,在不需要目标数据的情况下,实现对合成语音特征的有效控制,从而提高系统的灵活性。
3.2 最小生成误差模型训练
3.2.1 算法提出
虽然基于HMM的参数语音合成方法可以取得较为理想的合成效果,但是其采用的基于最大似然(maximum likelihood, ML)的模型训练准则存在两个问题。第一个问题就是HMM训练算法与语音合成应用的不一致。一般而言,语音合成的目标就是使生成的语音(参数)与自然语音(参数)尽可能地接近,而现在采用的基于最大似然准则的HMM训练算法是从语音识别中借鉴过来的,它并非针对语音合成应用而设计,由此导致HMM训练算法与语音合成应用的不一致;另一个问题是在参数生成过程中通过考虑动态和静态参数之间的约束来进行参数平滑,而现在的训练过程中没有考虑到此约束条件,导致训练得到的HMM中静态和动态参数之间存在不一致。针对上述模型训练中的问题,我们提出了一种基于最小化生成误差(Minimum Generation Error, MGE)的训练准则[28-34],并将该准则应用到模型训练中。在基于MGE准则的模型训练算法中,我们首先定义一个与合成目标相符的生成误差函数,然后将参数生成加入到模型训练中来计算生成误差,并基于广义概率下降(GPD)算法实现对模型参数的优化。
3.2.2 实现方法
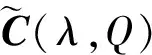
在计算C相对模型λ的生成误差时,严格来说需要考虑所有可能的状态序列Q。出于简化,我们只考虑单一状态序列,即由模型λ决定的C的最优状态序列Qopt,此时的生成误差可以记为
在以上误差函数定义下,我们将参数生成加入到HMM训练过程中来计算训练样本的生成误差,并采用广义概率下降算法(GPD)对模型参数进行调整,以达到最小化生成误差的目的。具体的算法描述与参数更新公式参见文献[28]。
3.2.3 评测实验
在实验过程中[28],我们使用的音库是一个音素平衡1 000句话的中文语料库,共包含25 096个声母和29 942个韵母,录音采样率为16kHz。在声学参数提取时,将由STRAIGHT谱包络导出的24阶LSP和1维增益作为频谱参数,分析帧移为5ms。对于基线系统,我们按照2.1节介绍的步骤,使用最大似然准则训练各上下文相关音素对应的模型,使用的模型结构为5状态自左向右无跳转的HMM,并且针对中文的特点进行了上下文属性的标注与问题集的设计。对于测试系统,使用上面介绍的最小生成误差准则进行模型参数的更新,在这个实验中,只更新了与频谱参数对应的模型参数。我们进行了针对合成语音自然度的主观测试。测试时,使用ML训练系统和MGE训练系统各合成了集外的50句话,由6名测听人员进行对比两个系统合成语音自然度的倾向性评分,最终的测试结果如图4所示[28]。从图4中可以看出,在进行MGE训练后,合成语音的质量有了明显而一致的提升。

图4 对比MGE训练与ML训练的自然度倾向性测试结果
在以上工作基础上,我们对MGE模型训练方法又进行了进一步的深入研究与应用拓展,包括将MGE准则应用于从模型聚类到聚类后模型优化的整个HMM训练过程[29];提出了MGE线性回归算法用于语音合成中的快速模型自适应[30];基于人耳感知特性设计MGE准则中的生成误差计算函数[31];使用MGE准则进行分层叠加基频模型的训练[32]与模型聚类决策树的规模优化[33];以及将MGE准则与发音动作特征模型相结合以提升声学参数到发音动作参数反响映射精度[34]等。相关研究结果均体现了MGE准则在语音合成声学模型训练中的有效性。
3.3 基于HMM的单元挑选与波形拼接合成
3.3.1 算法提出
前面已经提到,基于HMM的参数合成方法可以合成出平滑流畅的语音,但是由于使用了参数合成器以及参数建模与生成时的平均效应,使合成语音的音质和自然语音相比有较大差距;传统基于大语料库的单元挑选与波形拼接合成方法由于使用自然语音波形,可以合成出高自然度的语音,但是对于音库的尺寸要求较大,并且在系统构建过程中需要较多语种相关的人工干预,对不同领域文本合成效果的鲁棒性也不理想。为了综合以上两种方法的优点,我们将HMM参数合成中使用的统计建模思想应用到单元挑选与波形拼接合成方法中[35-39],提出了基于HMM的单元挑选与波形拼接合成算法。
3.3.2 实现方法
整个基于HMM的单元挑选与波形拼接合成系统可分为训练与合成两个阶段。
1) 训练阶段: 首先依据先验知识,提取一组我们认为可用于反映单元挑选与波形拼接合成系统自然度的特征参数,例如,各帧的频谱、基频,音素的时长等。针对每一种特征,训练其上下文相关音素的HMM模型,具体的模型训练方法,可以采用与基于HMM的参数合成算法中类似的模型训练流程,首先训练完全上下文展开的音素模型,再利用上下文相关的问题集,对模型进行聚类。假设最终提取的特征种类数为M,训练得到的模型集合为Λ=(Λ1,...,ΛM)。
2) 合成阶段: 合成阶段的核心是单元挑选算法。假设用符号F表示通过文本分析得到的待合成句的上下文描述信息;U=(u1,...,uN)代表合成一句话的一个备选单元序列,其中N是序列中的单元个数;这里对于每一个ui,i=1,...,N可以是任意尺度的单元,例如,音素、状态、帧等。我们要求挑选得到的最优单元序列U*满足
其中
gm(F,U;Λm)=LL(X(U,m),F,Λm)
-wKLDKLD(Λ(U,m),F,Λm)
(12)
表示使用第m个特征对应的统计模型Λm对单元序列U进行的客观评估;wm为模型Λm对应的权重。如式(12)所示,函数gm(·)由两部分组成,函数LL(·)表示计算单元序列U的声学参数对应模型Λm的似然值,X(U,m)为提取单元序列U对应的第m组特征;函数KLD(.)表示备选单元序列U对应的模型相对于目标模型的Kullback-Leibler距离(Kullback-Leibler Divergence, KLD)[40],Λ(U,m)为提取单元序列U的第m组特征对应的备选模型。式(12)的具体计算方法依赖于使用的特征提取方法。依据特征提取时前后单元之间的依赖关系,我们可以将式(11)转换成传统的“目标代价”和“连接代价”之和的形式,通过动态规划算法搜索最优的单元序列U*。
上述介绍的基于HMM的单元挑选与波形拼接合成方法可以有不同的具体实现方式,包括使用帧尺度的拼接单元和ML准则来进行单元的挑选[35]、使用音素和帧的两级尺度单元[36]等。下面结合Blizzard Challenge 2007 国际语音合成评测的结果来说明此算法的性能。
3.3.3 Blizzard Challenge 2007 国际合成语音评测
Blizzard Challenge是由美国卡耐基·梅隆大学的Black教授和日本名古屋工业大学的Tokuda教授于2005年发起的一项全球合成语音评测活动[41]。这个活动通过发布统一的合成音库,由各个参赛单位在短时间内构建合成系统,并且集中评测,实现对基于语料库的语音合成中各个技术点的较为有效的测试,从而推动整个语音合成技术的发展。 2007年我们首次使用上述基于HMM 的单元挑选与波形拼接方法构建合成系统参加此测试活动[39]。
2007年的参测单位为16家,包括Carnegie Mellon University,University of Edinburgh,HTS working group,Toshiba,Nokia等语音合成领域内的知名研究机构与公司。组织者对各个参赛单位提交的测试语音进行统一测试。所有参赛单位的系统被赋予代号,测试以匿名的形式进行。测试的指标包括合成语音的相似度、自然度(MOS得分)和可懂度(单词听写错误率)。测试过程基于网络进行,参加测试的人员包括语音技术专家、英语母语的学生以及网络上的志愿者等。
为了对统计声学模型框架下不同的合成方法进行更加充分的比较,我们同时提交了两个参测系统参与这一次的评测活动。它们分别为基于HMM的参数合成系统和基于HMM的单元挑选与波形拼接合成系统。前者采用3.2节中介绍的MGE训练方法构建参数合成系统;而后者采用本节中介绍的基于HMM的单元挑选算法框架,我们以音素作为基本拼接单元,在音素的基频、频谱、时长模型之外,又增加了度量音素拼接处声学参数变化的拼接模型,并且采用了基于KLD的单元预选方法来提高运行效率。图5~7显示了所有参测系统的平均相似度、自然度和可懂度评测结果。其中我们提交的基于HMM的参数合成系统的编号为“J”,基于HMM的单元挑选与波形拼接合成系统的编号为“A”,系统“I”为组织者提供的自然语音样本。从图5 中可以看出,我们提交的基于HMM的单元挑选与波形拼接合成系统(系统A)是所有参测系统中相似度得分最高的;而基于HMM的参数合成系统(系统J)在这方面的表现则不够理想,究其原因,我们认为是参数合成方法中使用的参数合成器对于合成语音的音色造成了损伤,使其相对原始语音的相似度下降。图6显示的自然度评测结果中,系统A仍然是表现最好的系统,优于系统J,表明了这种基于HMM的单元挑选合成算法在提高合成语音自然度方面的有效性。另一方面,参数合成方法在合成语音可懂度方面的优势在图7中表现了出来,系统J在所有参测系统中具有最小的单词听写错误率,这也体现了基于HMM的参数合成方法在合成效果的鲁棒性方面还是有其优势,尤其是MGE模型训练准则使合成语音的清晰度得到了明显提升。
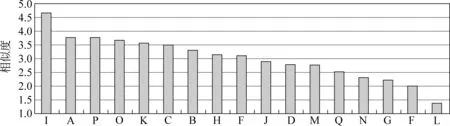
图5 Blizzard Challenge 2007相似度评测结果
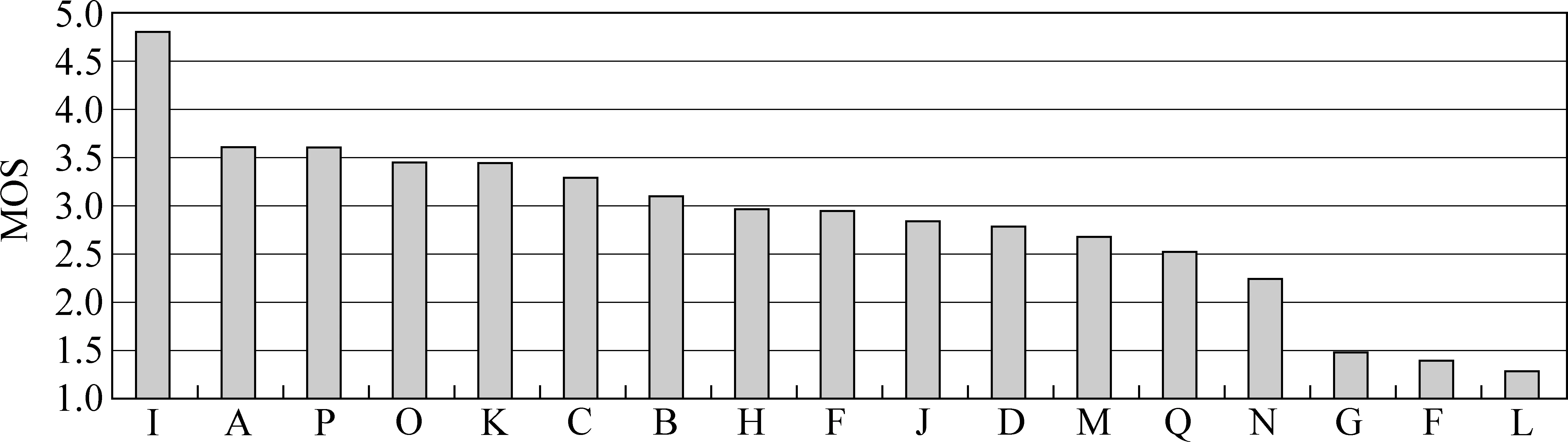
图6 Blizzard Challenge 2007自然度评测结果(MOS)

图7 Blizzard Challenge 2007可懂度评测结果(单词听写错误率)
在2008~2011年的Blizzard Challenge评测活动中,我们同样使用基于HMM的单元挑选与波形拼接方法构建了参测系统,并在音节级长时韵律特征使用[37]、模型聚类决策树规模优化、方差绑定的模型训练等方面进行了一系列技术改进。在这几年的评测活动中,我们提交的参测系统均取得了优异的性能表现。我们还在用于单元挑选的HMM模型训练准则方面进行了进一步的探索,提出了最小单元挑选误差准则(Minimum Unit Selection Error, MUSE)[38],实现了系统构建的完全自动化并提高了合成语音的自然度。
4 总结
本文在回顾语音合成技术发展历史的基础上,介绍了基于声学统计建模的语音合成方法。该方法的典型系统是基于HMM的参数语音合成,在对其基本的系统框架进行描述和分析之后,介绍了中国科学技术大学讯飞语音实验室近年来我们在此方面的所做的实际工作,包括: 在特征使用中,融合发音动作参数与声学参数,提高声学参数生成的灵活度;在模型训练阶段,以最小生成误差准则取代最大似然准则,更好地瞄准语音合成的应用,提高合成语音的音质;在语音生成阶段,使用单元挑选与波形拼接合成方法取代参数生成与合成器重构,从根本上改善HMM参数语音合成器在合成语音音质上的不足。这些研究成果不仅通过了严谨的实验证实,同时正在逐渐地应用到实际的语音合成系统中去,使得语音合成技术在系统构建和提高表现力方面有了质的突破,进一步促进了多语种的语音合成、说话人音色转换、语气语调的合成和情感语音合成等各方面的发展。Blizzard Challenge 国际语音合成评测更是对这些技术进展作出了全面、科学的肯定。
综上,声学统计建模思想的应用可以说是开创了语音合成发展的一个新的阶段,它为我们提供了更广阔的研究发展空间,在实现真正自然的人机语音交互的方向上迈出了重要的一步。
[1] Wang R H,Chen S H, Tao J, et al. Mandarin Text-To-Speech Synthesis[C]//Advances in Chinese Spoken Language Processing. Beijing: World Scientific Publishing, 2007.
[2] Campbell W N, Black A W. Prosody and the selection of source units for concatenative synthesis[J]. Progress in Speech Synthesis, 1996: 279-282.
[3] Iwahashi N, Kaiki N, SagisakaY. Concatenative speech synthesis by minimum distortion criteria[C]//International Conference on Acoustics, Speech, and Signal Processing.1992, 2: 65-68.
[4] Wang R H, Ma Z K, Zhu D L. A corpus-based Chinese speech synthesis with contextual-dependant unit selection[C]//International Conference on Spoken Language Processing. 2000: 391-394.
[5] Donovan R E. Trainable speech synthesis[D]. Ph.D Dissertation, Cambridge University, 1996.
[6] Tokuda K, Zen H, Black A W. HMM-based approach to multilingual speech synthesis[C]//Text to Speech Synthesis: New Paradigms and Advances. New York: Prentice Hall, 2004.
[7] Hu Y, Liu Q F, Wang R H. Prosody generation in Chinese synthesis using the template of quantified prosodic unit and base intonation contour[C]//International Conference on Spoken Language Processing. 2000: 55-58.
[8] 王仁华, 胡郁, 李威, 等. 基于决策树的汉语大语料库合成系统[C]//第六届全国人机语音通信学术会议论文集, 2001: 183-186.
[9] Li W, Ling Z H, Hu Y, et al. A statistical method for computing candidate unit cost in corpus based Chinese speech synthesis system[C]//International Conference on Chinese Computing. 2001: 167-170.
[10] Shuang Z W, Ling Z H, Hu Y, et al. A miniature Chinese TTS system based on tailored corpus[C]//International Conference on Spoken Language Processing. 2002: 2389-2392.
[11] Ling Z H, Hu Y, Shuang Z W, et al. Decision tree based unit pre-selection In Mandarin Chinese synthesis[C]//International Symposium on Chinese Spoken Language Processing. 2002: 277-280.
[12] Sun L, Hu Y, Wang R H. Polynomial regression model for duration prediction in Mandarin[C]//International Conference on Spoken Language Processing. 2004: 769-772.
[13] Wang R H, Hu Y. Statistical modeling of pitch contour in standard Chinese[C]//From Traditional Phonology to Modern Speech Processing. Beijing: Foreign Language Teaching and Research Press,2004.
[14] Tokuda K, Masuko T, Miyazaki N, et al. Hidden Markov models based on multi-space probability distribution for pitch pattern modeling[C]//International Conference on Acoustics, Speech, and Signal Processing. 1999,1:229-232.
[15] Shinoda K, Watanabe T. MDL-based context-dependent subword modeling for speech recognition[J]. Journal of Acoustical Society of Japan , 2000, 21(2): 79-86.
[16] Yoshimura T, Tokuda K, Masuko T, et al. Duration modeling in HMM-based speech synthesis system[C]//International Conference on Spoken Language Processing. 1998, 2: 29-32.
[17] Tokuda K, Kobayashi T, Imai S. Speech parameter generation from HMM using dynamic features[C]//International Conference on Acoustics, Speech, and Signal Processing. 1995: 660-663.
[18] Nose T, Yamagishi J, Masuko T, et al. A style control technique for HMM-based expressive speech synthesis[J]. IEICE Transactions on Infomation and Systems, 2007, E90-D(9): 1406-1413.
[19] Shichiri K, Sawabe A, Tokuda K, et al. Eigenvoices for HMM-based speech synthesis[C]//International Conference on Spoken Language Processing. 2002: 1269-1272.
[20] Qin L, Ling Z H, Wu Y, et al. HMM-based emotional speech synthesis using average emotion model[C]//Proceedings of 5th International Symposium on Chinese Spoken Language Processing. 2006: 233-240.
[21] Ling Z H, Richmond K, Yamagishi J, et al. Articulatory control of HMM-based parametric speech synthesis driven by phonetic knowledge [C]//Proceedings of Interspeech. 2008: 573-576.
[22] Ling Z H, Richmond K, Yamagisihi J, et al. Integrating articulatory features into HMM-based parametric speech synthesis[J]. IEEE Transaction on Audio, Speech, and Language Processing, 2009, 17(6): 1171-1185.
[23] Ling Z H, Richmond K, Yamagishi J. Feature-space transform tying in unified acoustic-articulatory modelling for articulatory control of HMM-based speech synthesis [C]//Proceedings of Interspeech. 2011: 117-120.
[24] King S, Frankel J, Livescu K, et al. Speech production knowledge in automatic speech recognition[J]. Journal of the Acoustical Society of America, 2007, 121(2): 723-742.
[25] Markov K, Dang J, Nakamura S. Integration of articulatory and spectrum features based on the hybrid HMM/BN modeling framework[J]. Speech Communication, 2006, 48(2): 161-175.
[26] Dempster A P, Laird N M, Rubin D B. Maximum likelihood from incomplete data via the EM algorithm[J]. Journal of the Royal Statistical Society, 1977, 39(1): 1-38.
[27] Kawahara H, Masuda-Katsuse I, de Cheveigné A. Restructuring speech representations using a pitch-adaptive time-frequency smoothing and an instantaneous-frequency-based F0 extraction: possible role of a repetitive structure in sounds[J]. Speech Communication, 1999, 27(3-4): 187-207.
[28] Wu Y J, Wang R H. Minimum generation error training for HMM-based speech synthesis[C]//International Conference on Acoustics, Speech and Signal Processing. INSPEC, 2006, 1: 89-92.
[29] Wu Y J, Wang R H, Soong F. Full HMM training for minimizing generation error in synthesis[C]//International Conference on Acoustics, Speech and Signal Processing. Hawaii, USA: IEEE Press, 2007, 4: 517-520.
[30] Qin L, Wu Y J, Ling Z H, et al. Minimum generation error lineal regression based model adaptation for HMM-based speech synthesis[C]//International Conference on Acoustics, Speech and Signal Processing. Las Vegas: IEEE Press, 2008: 3953-3956.
[31] Lei M, Ling Z H, Dai L R. Minimum generation error training with weighted Euclidean distance on LSP for HMM-based speech synthesis [C]//International Conference on Acoustics, Speech and Signal Processing. 2010: 4230-4233.
[32] Lei M, Wu Y J, Soong F, et al. A hierarchical F0 modeling method for HMM-based speech synthesis [C]//Proceedings of Interspeech. 2010: 2170-2173.
[33] Lu H, Ling Z H, Dai L R, et al. Cross-validation and minimum generation error based decision tree pruning for HMM-based speech synthesis[J]. Computational Linguistics and Chinese Language Processing, 2010, 15(1): 61-76.
[34] Zhao T Y, Ling Z H, Lei M, et al. Minimum generation error training for HMM-based prediction of articulatory movements [C]//International Symposium on Chinese Spoken Language Processing. 2010: 99-102.
[35] Ling Z H, Wang R H. HMM-based unit selection using frame sized speech segments[C]//Proceedings of Interspeech. 2006: 2034-2037.
[36] Ling Z H, Wang R H. HMM-based hierarchical unit selection combining Kullback-Leibler divergence with likelihood criterion[C]//International Conference on Acoustics, Speech and Signal Processing. INSPEC, 2007,4: 1245-1248.
[37] Ling Z H, Wang Z H, Dai L R. Statistical modeling of syllable-level F0 features for HMM-based unit selection speech synthesis [C]//International Symposium on Chinese Spoken Language Processing. 2010: 144-147.
[38] Ling Z H, Wang R H. Minimum unit selection error training for HMM-based unit selection speech synthesis system[C]//International Conference on Acoustics, Speech and Signal Processing. 2008: 3949-3952.
[39] Ling Z H, Qin L, Lu H, et al. The USTC and iFLYTEK speech synthesis systems for Blizzard Challenge 2007[EB/OL]. http://festvox.org/blizzard/bc2007/blizzard_2007/blz3_017.html.
[40] Liu P, Soong F K. Kullback-Leibler divergence between two hidden Markov models[R]. Microsoft Research Asia, 2005.
[41] Black A W, Tokuda K. The Blizzard Challenge 2005: Evaluating corpus- based speech synthesis on common databases[C]//Proceedings of the Interspeech. 2005: 77-80.
