基于GAE的专业服务网信息获取技术研究*
2011-06-27胡金柱
胡 泉,胡金柱,谢 芳
(1.华中师范大学 武汉 430079;2.湖北工业大学 武汉 430068)
1 引言
专业服务网站是以行业或领域为服务对象的特殊网站,如面向机械、化工、电力、计算机等行业的服务网站,是针对某一特定领域、某一特定人群或某一特定需求,提供内容集中而深入的信息服务的网站。这类网站数量庞大,基本上都是免费开放,如各级政府的科技信息服务网或情报网、公司的服务网(如海尔公司的服务网站)等。
专业服务网站针对专业领域中的特定用户群,为其提供专业的、量身打造的服务,它能够限制用户查找信息类别的范围,使用户快速找到需要的信息。所以,网上信息应该简洁、明了,确保用户能在尽可能短的时间内找到最需要的信息内容。因此专业服务网的信息管理工作者,其主要任务之一是从相关的网站上及时、准确地获取有用信息,并对这些信息内容进行专业处理、深度加工和及时更新发布。网上信息一般是以标题、内容的形式发布,而不是以网页链接的形式表示。所以,直接搜索到的信息不仅仅是网页链接,而是网页内容的主体和标题等有用信息。因此,需要研究一种专用的信息自主更新系统,才能让信息管理工作者从枯燥、单调、杂乱无章的海量信息中及时、准确地获取有用信息。
目前,Google推出的谷歌应用软件引擎(Google application engine,GAE)是一种免费的云计算平台,它可以让开发人员编译基于Python的应用程序,并免费使用其基础设施进行托管。因此,用户在GAE下建设小型专业服务网站时,不再需要租用主机,寻找托管商;开发人员在GAE的框架内开发,不用再考虑CPU、内存、分布等复杂和难以控制的问题。
2 GAE下面向本体的专业信息服务网信息自主更新问题
本体(ontology)是共享概念模型的明确的形式化规范说明,包含概念的定义、概念间的复杂关系以及概念推理的规则。应用本体可以捕获相关领域的知识,提供对该领域知识的共同理解,确定该领域内共同认可的词汇(术语),并从不同层次的形式化模式上给出这些词汇间相互关系的明确定义。
2.1 信息自主更新的基本过程
GAE下面向本体的专业信息服务网信息自主更新的基本过程如下:
·利用网络爬虫爬取网页数据;
·本体按照指定的规则模板进行信息获取;
·将抽取的信息按照规定的格式存储到元数据库中;
·索引程序对存储的数据建立索引,并存入索引数据库;
·查询分析器分析用户的查询请求,并将分析的结果传递给推理机;
·根据推理机的处理结果构建查询对象,访问索引数据库,并将检索到的结果返回给用户;
·将得到的专业服务信息推送到专业信息服务网。其中,检索是面向本体语义检索的最重要的一部分,查询处理可描述成以下的IR模型。
本体模型、面向本体的标识Web资源的模型、面向本体的查询模型,将查询的关键词匹配成本体描述的匹配算法。在这些模型中,Web资源(R)与查询(Q)是相关的,仅在面向本体(O)建立的R和Q中,R满足Q。在云计算平台GAE下,本文采用本体与本体间的映射方法将查询关键词匹配成本体描述,让本体易于被机器所理解,并且使本体间在语义上达到概念的一致性。
2.2 本体语义搜索引擎的基本模型
实现面向本体语义搜索引擎的过程中,想让搜索引擎理解用户的搜索内容和目标,就必须实现如下两个基本功能:对爬虫程序爬取的信息进行基于本体的信息抽取;利用推理机进行分析查询。
基于这两点功能,本文设计了如图1所示的基本框架模型。
2.3 面向本体的信息获取过程
因为在云计算平台GAE下,不同的启发式规则生成的部分解可能是不一致的,所以面向本体的信息抽取过程大致可以分为5个步骤:文本结构解析和汉语分词、文本分类、假设生成、数据规格化处理与完整性检查、矛盾消解。其中,信息抽取由后3步完成。第3步产生各种可能的相互矛盾竞争的部分解,并在第4步加以去粗取精的处理,再通过检测评判从这些竞争部分解中析出最终的一致解。

图1 基于GAE的本体语义搜索引擎基本框架模型
该过程的关键是抽取规则模板和规则算法。本文中面向本体的信息抽取的规则模板采用概念断言进行描述,这样可以在云计算平台GAE下将本体的概念及其属性之间的关系与约束表示为概念断言。概念断言的形式如图2所示。

图2 概念断言的形式
图3是一个应用示例,即对旅游信息抽取的一些本体断言。
在云计算平台GAE下基于本体的信息抽取的规则算法描述如图4所示。
2.4 利用推理机分析查询目标
在云计算平台GAE下,语义检索的意义在于对概念及概念间的关系进行语义层面的检索,其关键在于对概念之间的推理。Jena提供了基于规则的推理机,包括RDFSReasoner、OWL Reasoner等,都具有一般的推理功能,目前一般都使用Jena对所建立的专用本体进行推理分析请求。利用Jena对前面所建立的旅游本体进行推理的部分过程如图5所示。

图3 对旅游信息抽取的一些本体断言

图4 基于本体的信息抽取的规则算法描述
这里的printStatements定义如下:
public void printStatements(Model m,Resource s,Property p,Resource o)
{
for(StmtIterator i=m.listStatements(s,p,o);i.hasNext();){Statement stmt=i.nextStatement();
System.out.println(“-”+PrintUtil.print(stmt));}
}
2.5 专业服务网信息爬取器的设计与实现
GAE下的专业服务网信息爬取器是搜索、获取信息的核心内容之一。本文设计并实现了一个面向主题的专业服务网信息爬取器,如图6所示,主要由协议处理、页面分析、页面内容检查、URL优先权判定和页面存储5部分组成。
·协议处理:处于系统的底层,主要通过各种协议完成数据的采集。

图5 旅游本体推理的部分过程
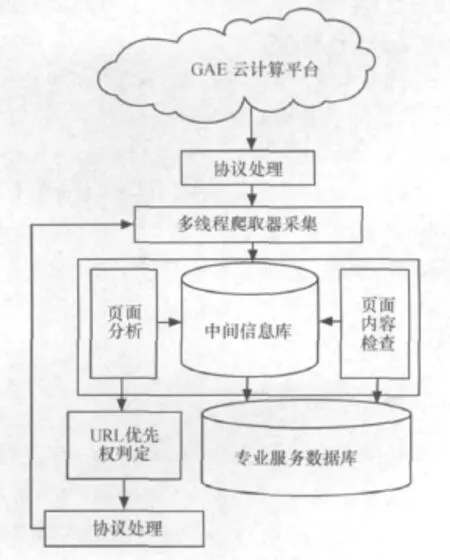
图6 GAE下专业信息服务网爬取器的基本结构
·页面分析:对于已采集到的页面,首先判别页面的类型,然后分析并提取未被访问的链接以及用于链接相关性预测的一些其他信息,如提取用于页面相关性判定的页面正文等。
·页面内容检查:对下载的页面内容,通过解析、计算其与主题的相似度,对页面进行检查,过滤相关度较低的页面内容,提高采集的准确度。
·页面存储:采集到的页面经过页面内容过滤后,被判定为符合主题要求的存入专业服务数据库,以供搜索引擎的索引需要。
·URL优先权判定:采用基于链接上下文的自适应爬取算法,计算待爬取的链接的优先权,并按该优先权进行排序,不断调整待爬行的队列,保证系统持续运行。
专业服务网信息爬取器在启动之前,需要设置必要的参数,提交需要采集的主题关键词以及一个比较好的初始爬取站点集合,经过系统的初始化,系统将以这些配置信息作为运行的初始值,进行基于主题的有选择性的网页爬行,以获取与主题相关的网页。
专业服务网信息爬取器需要维护3个队列:待爬行URL队列、已爬行队列和停用队列。其中,待爬行URL队列是爬取器爬行的依据,已爬行队列存储己经下载过的,停用队列存储那些明显不相关的或是因为别的原因被爬取器拒绝爬行的。待爬行URL队列随着爬取器的爬行不断动态变化,爬取器在爬行的过程中,不断地有新链接出现,根据启发式搜索策略,这些新的链接会按照主题相关性以由大到小的顺序排列,并被加入待爬行URL队列中。所以无论何时,主题相关性最高的URL一定在待爬行队列的头部,这样就保证了爬取器每次从该队列中取出用于访问的都是与主题最相关的。相应的网页被访问后便将其抽取出来,计算它与主题的相关性,然后将它插入该队列的相应位置。这个过程周而复始,以保证爬取器能够对与主题最相关的网页不断地爬行下去,直到该队列为空。爬取器的运行流程如图7所示。
3 实验及其结果分析
通常从召回率、准确率和检索时间3个方面评价搜索引擎的性能。其中,检索时间除了依赖于索引算法和检索算法外,还在一定程度上依赖于硬件配置。因此,本文主要统计分析召回率和准确率。表1给出了实验数据的处理结果,对于检索请求所要表达的意思在所建本体范围内的情况,在准确率和召回率上有很好的结果。
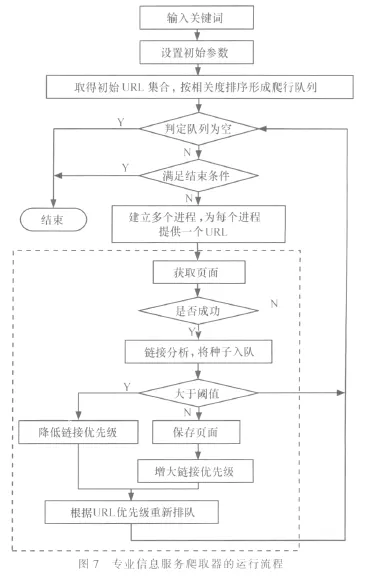

表1 实验数据处理结果
本实验环境为独立开发的省情网和农民工信息服务网,这是两个典型的专业信息服务网,是为专门领域的专门人群提供相应的信息服务的网络,按照图1所示的基本框架模型设计,并各自建有相应的本体库。
4 结束语
针对传统信息更新系统中存在的不能理解查询语义的问题,本文研究了一种基于GAE面向本体语义的专业信息服务网信息更新系统的框架结构,充分利用本体语义的优点,可以从知识库中快速查找与用户需求密切相关的信息。在省情网和农民工信息服务网上得到具体实现,证明了其信息获取技术的有效性和准确性。同时,在GAE下建设小型专业服务网站时,不再需要非云计算环境下的主机租用和寻找托管商等繁琐工作;开发人员在GAE的框架内开发,也不用再考虑非云计算环境下的CPU、内存、分布等复杂和难以控制的问题。但如果所要获取的信息需求所表达的语义不在系统本体的范围内,搜索到的结果不太理想,这是需要进一步研究的问题。
1 陈全,邓倩妮.云计算及其关键技术.计算机应用,2009,29(9)
2 栾静,李军锋.基于Lucene全文检索引擎的应用研究.计算机与数字工程,2010,38(12)
3 He B,Chang K C C.Automatic complex schema matching across Web queryinterfaces:a correlation mining approach.ACM Transactions on Database Systems(TODS),2006,31(1):346~395
4 Su W F,Wang J Y,Lochovsky F.Automatic hierarchical classification of structured deep Web databases.Web Information Systems-Wise,Proceedings Lecture Notes in Computer Science,2006(4 255):210~221
5 Caverlee J,Liu L,Rocco D.Discovering interesting relationships among deep Web databases:a source-biased approach.World Wide Web-Internet and Web Information Systems,2006,9(4):585~622
6 Shestakov D,Bhowmick S S,Lim E P.DEQUE:querying the deep Web.Data&Knowledge Engineering,2005,52(3):273~311
7 Caverlee J,Liu L.QA-pagelet:data preparation techniques for large-scale data analysis of the deep Web.IEEE Transactions on Knowledge and Data Engineering,2005,17(9):1 247~1 262
