基于云模型的文本特征自动提取算法
2011-06-01何中市
代 劲 ,何中市,胡 峰,
(1. 重庆大学 计算机科学与技术学院,重庆,400030;2. 重庆邮电大学 计算机科学与技术研究所,重庆,400065;3. 西南交通大学 信息科学与技术学院,四川 成都,610031)
文本自动分类是信息检索与数据挖掘领域的研究热点与核心技术,近年来得到了广泛关注和快速发展,在信息检索[1]、新闻推荐[2]、词义消歧[3]、文本主题识别[4]、网页分类[5]等领域有着广泛应用。文本自动分类的主要难题之一是特征空间维数过高[6],如何降低特征空间维数成为文本自动分类中需要首先解决的问题。特征选择是文本特征降维的一种有效方法[6],很多学者对此进行了深入的研究,并提出了很多有效的方法,比较经典的有文档频率DF[7]、信息增益IG[7]、χ2统计量 CHI[7]、互信息 MI[8]和多种方法组合[9]等。这些方法按其特征选择函数计算函数值,然后以降序选择靠前的特征集。在选择过程中,选择尺度是一个重要指标,直接影响着文本分类的性能。实验证明:多数分类器呈现出随特征数量增加,效果快速提高并能迅速接近平稳的特点;但若特征数过大,性能反而可能降低[10-13]。这表明合理的特征选择尺度不仅能大量降低处理开销,而且在很多情况下可以改善分类器的效果。在确定特征选择尺度时,现有特征选择方法通常采用经验估算方法:如给定特征数的经验值(PFC)或比例(THR)、考虑统计量阈值(MVS)或向量空间稀疏性(SPA)、特征数与文本数成比例(PCS)等一些选择方法[14]。这些方法在某些特定语料库上取得比较好的效果,但通常为观察所得或经验推断,理论基础不充分,不便于文本自动分类的进一步推广研究;因此,研究能适应文本特性的特征自动提取方法是非常必要的。云模型是一种定性定量转换模型[15-18],由于其具有良好的数学性质,可以表示自然科学、社会科学中大量的不确定现象[18]。云模型不需要先验知识,它可以从大量的原始数据中分析其统计规律,实现从定量向定性的转化。本文作者结合特征在整体与局部上的χ2分布情况,利用云模型在定性知识表示以及定性、定量知识转换时的桥梁作用,引入云隶属度概念对特征分布加以修正,并且构建了一种逐级动态聚类算法来获取特征集,在此基础上提出一种高性能文本特征自动提取算法。该算法不需要指定聚类数目,能根据特征分布特点自动获取隶属度高的特征集。分析和开放性实验结果表明:该特征集具有特征个数少、分类精度高的特点,性能明显比当前主要的特征选择方法的优。
1 文本特征选择方法
特征选择是通过构造一个特征评分函数,把测量空间的数据投影到特征空间,得到在特征空间的值,然后,根据特征空间中的值对每个特征进行评估。特征选择并没有改变原始特征空间的性质,只是从原始特征空间中选择了一部分重要的特征,组成一个新的低维空间。
特征选择是文本特征降维的一种有效方法。目前已有的特征选择方法主要分为 2类:(1) 倾向于词频的特征选择方法,如 DF,IG,χ2统计量 CHI和 MI等;(2) 倾向于类别的特征选择方法,如CTD特征选择方法[19]和带有强类别信息词SCIW特征选择方法[20]等。第1类方法强调词频在所有类别上的整体分布;第2类方法强调类别信息,而对词频在所有类别上的整体分布考虑不充分。如果能有效地结合词频在所有类别的整体分布和在单个类别上的分布情况,将会明显改善特征选择性能。
此外,还有期望交叉熵(ECE)、文本证据权(WET)、优势率(OR)等一些特征选择方法,文献[21]对DF,IG,MI,CHI,ECE,WET和OR这些特征选择方法进行了比较,结果表明:OR方法的效果最好,IG,CHI和ECE的效果次之,WET和DF的效果再次之,MI的效果最差。而Yang等[7,22]认为IG是最好的测度之一。Forman等[10]分别从有效性、区分能力及获得最好效果的机会等方面对不同特征选择方法进行了广泛比较,结果表明:CHI和IG等统计量及组合方法具有一定的优势。
从上述分析看,这些方法对提高文本分类的效果都没有绝对优势。这是因为文本分类本身涉及训练数据集合本身的特点,同时,不同分类器的分类效果也不尽相同[10-11]。
2 基于χ2统计量的文本特征分布矩阵
χ2统计量[7]的概念来自列联表检验,用来衡量特征ti和类别Cj之间的统计相关性。实验证明是一种比较好的特征选择方法[10,21],它基于ti和Cj之间符合具有一阶自由度的χ2分布假设。ti关于Cj的χ2可由下式计算:

式中:N为训练语料中文档总数;A为属于类Cj的文档频数;B为不属于Cj类但包含ti的文档频数;C为属于 Cj类但不包含 ti的文档频数;D是既不属于 Cj也不包含ti的文档频数。可知当特征ti与类别Cj相互独立时, χ2( ti, Cj) = 0 ,此时特征 ti不包含任何与类别Cj有关的信息。特征ti与类别Cj的统计相关性越强,χ2( ti, Cj)越大,此时,特征ti包含的与类别Cj有关的信息就越多。
由χ2计算公式可以看出:χ2统计方法作为特征选择方法时,只考虑了特征在所有文档出现的文档频数。若某一特征只在一类文档的少量文档中频繁出现,则通过χ2计算公式计算的χ2统计值很低,在特征选择时,这种特征词就会被排除,但这种在少量文档中频繁出现的特征词很有可能对分类的贡献很大,如专指概念。这是 χ2统计的不足之处,它对低文档频的特征项不可靠。
基于以上分析,考虑特征在各个类别之间的分布情况,建立特征关于类别的χ2分布矩阵。定义如下:
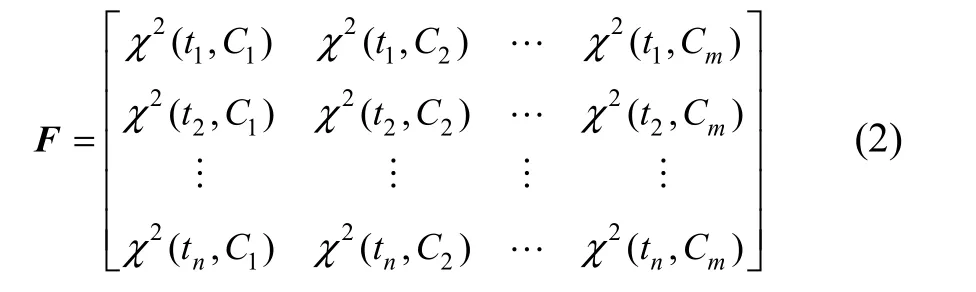
从F的构造可以看出:F中的每一行反映了特征在不同类别中的分布情况,每一列反映了在同一类别中不同特征的分布情况。将二者结合起来,能够完整反映整个特征集的分布,而且客观上弥补了χ2统计量作为特征选择方法上的缺点。
3 基于云隶属度的文本特征自动提取算法
通过分析每一类别上不同特征的 χ2分布情况可见:一些χ2较大的特征在类别中出现频率极低,而另一些在类别中出现比较频繁的特征χ2反而很小。这种异常的出现正是由于这些特征打破了χ2统计量基于ti和Cj之间符合具有一阶自由度的χ2分布,受整体分布影响较大,需要加以修正。由此,本文为每个特征引入一个模糊概念,用云模型对其在类别上的分布进行定量描述,将特征对于类别的χ2用相应的隶属度加以修正。
3.1 云模型简介
云模型用语言值表示某个定性概念与其定量表示之间的不确定性[15-18],已经在智能控制、模糊评测等多个领域得到应用。
定义1[15]设U是一个用数值表示的定量论域,C是U上定性概念。若定量值 Ux∈ 是定性概念C的一次随机实现,x对C的确定度]1,0[)(∈xμ是有稳定倾向的随机数,μ: U→[0, 1], Ux∈∀, x→μ(x),则x在论域U上的分布称为云,记为云C(X)。每一个x称为一个云滴。如果概念对应的论域是n维空间,那么可以拓广至n维云。

隶属度在基础变量上的分布称为云。在对模糊集的处理过程中,论域中某一点到它的隶属度之间的映射是一对多的转换,不是一条明晰的隶属曲线,从而产生了云的概念。
云用期望Ex(Expected value)、熵En(Entropy)、超熵He(Hyper entropy)这3个数字特征来整体表征一个概念。期望Ex是云滴在论域空间分布的期望,是最能够代表定性概念的点;熵En代表定性概念的可度量粒度,熵越大,通常概念越宏观,也是定性概念不确定性的度量,由概念的随机性和模糊性共同决定。超熵He是熵的不确定性度量,即熵的熵,由熵的随机性和模糊性共同决定。用3个数字特征表示的定性概念的整体特征记作C(Ex,En,He),称为云的特征向量。
正向云算法[15]和逆向云算法[15]是云模型中2个最基本、最关键的算法。前者把定性概念的整体特征变换为定量数值表示,实现概念空间到数值空间的转换;后者实现从定量值到定性概念的转换,将一组定量数据转换为以数字特征{Ex,En,He}来表示的定性概念。
3.2 基于云隶属度的文本特征自动提取算法
通过特征χ2分布矩阵,特征的取值不仅反映了特征对整个分类作用大小,也反映了该特征对于每一类别的贡献程度。通过云模型隶属度函数的引入,更修正了特征在类别中的分布情况。通过提取每一类别隶属度最高的特征集,合并而成最终的分类特征集合,不仅可以保留对整个分类贡献最大的特征集,同时兼顾某些特征集较少(或者在某一类中出现频率大,但总体出现概率低的特征)的类别。
在对特征取值进行隶属度表示后,特征在类别上的取值表示成了[0,1]区间上的连续值。特征对类别的相关性越大,其隶属度越高。但每一类别仍包含大量特征,其中很大一部分特征对于类别的隶属度极低,需要对特征集进行初步筛选,减少特征提取计算量。
定义 3[17]一维论域中 U中,任一小区间上的云滴群Δx对定性概念A的贡献ΔC为:
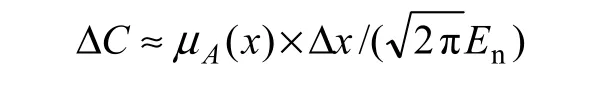
由定义3,可以计算得到U上所有元素对概念A的总贡献C为:
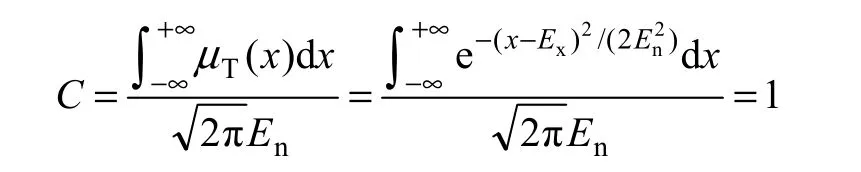
基于以上分析,通过计算可以得到位于区间[Ex-0.67En, Ex+0.67En]的特征,占特征总量的22.33%,但它们对类别的贡献占50%,能够满足特征提取需要,故将在此区间的特征筛选为初选特征集。
在特征的提取上,可以采用动态聚类方法进行处理。但是,在聚类过程中,类别个数应该是与数据本身特性有关,而不是一个经验值。因此,采用逐步试探聚类类别个数直至最终满足聚类要求的思路,提出了逐级动态聚类算法。
算法1:逐级动态聚类算法。
输入:类别向量Ci//即第2节中χ2分布矩阵F中的列向量。
输出:特征集合Ti。
算法步骤:
(1) 提取Ci中所有不重复的特征隶属度以升序构成新类别向量, Clusterid},其中Clusterid为聚类类别编号。
(3) 初始类别K=1,v=e+1 //v为循环控制变量。
(4) WHILE (v>e) DO //当v≤e时,各类的聚合程度已经比较好,聚类结束。
1) 构建中心类别表TC:将iC′平均分成K+1份,取区间右端点加入TC,作为C′在K情况下的初始类别,同时将iC′各元素Clusterid置为0;
2) 设定临时循环控制变量e1=0;
3) 当 e1≠v时,执行以下循环: //聚类稳定后,各类的标准差将收敛为稳定值。
① e1=v;
② 计算iC′中每个值与 TC中各类别距离,将其归并到距离最小的类别中;
③ 根据加权平均修正 TC中各类别的中心距离;
④ 计算 TC中各类别的标准差 Si,令
4) K=K+1 //聚类类别数加1,进行下一轮的聚类处理。
LOOP
(5) 聚类结束,K′=K-1即为聚类类别数。编号为K′的特征为类别 Ci隶属度最大的特征集,Ti= { tj|tj∈Ci∧Clusterid=K′}。
(6) RETURN Ti。
算法1的复杂度分析:设类别Ci上特征的平均个数为n,算法时间复杂度主要由步骤(4)决定。步骤(4)是一个典型的 k均值聚类[24],其时间复杂度为O ( k × n ),因此,步骤(4)的时间复杂度为 O ( k2× n )(其中,k为平均聚类个数)。故算法 1的时间复杂度为O ( k2× n ),空间复杂度为O(n)。
在算法1的基础上,提出了一种云隶属度下的文本特征自动提取算法。该算法不需要指定聚类数目,能根据特征分布特点自动获取隶属度高的特征集,具体见算法2。
算法 2:基于云隶属度的文本特征自动提取算法(FAS)。
输入:特征χ2分布矩阵F,训练集TR。
输出:经过特征选择后的训练集 RT′。
算法步骤:
初始化特征集φ=T;
依次选择F中每一列Ci,进行以下步骤处理:
1) 运用逆向云算法计算 Ci的数字特征 C(Ex, En,He);
2) 运用正向云算法将 Ci特征值转化成对应隶属度;
3) 将Ci中区间[Ex-0.67En, Ex+0.67En]外的特征删除,得到初次约简类别向量iC′;
4) 在iC′基础上调用逐级动态聚类算法(算法1)得到选择后特征集Ti;
5)iTTT∪=
6) 删除TR中不属于T的所有特征项,得到选择处理后训练集 RT′。
算法2的复杂度分析:设训练集类别平均特征数为 n,类别数为 m,则算法 2的时间复杂度为O(k2×n×m) (k为平均聚类个数),空间复杂度为O(n)。
4 实验及其结果分析
为了测试本文算法的有效性,对FAS算法进行横向对比测试。实验中,采用性能较好的kNN分类器算法[25](k=30)进行文本分类测试。测试结果用准确率(即分类正确数/实际分类数)、查全率(即分类正确数/应有数)和宏平均P为准确率;R为召回率)进行评测。
4.1 语料库
实验选用中文语料库 TanCorpV1.0[26]与英文语料库Reuters-21578[27]。 TanCorpV1.0包含文本14 150篇,共分为12类。经过停用词移除、词干还原等处理后,得到词条72 584个。
对于Reuters-21578,使用只有1个类别且每个类别至少包含5 个以上的文档。这样,得到训练集5 273篇、测试集1 767篇。经过停用词移除、词干还原等处理后,得到13 961个词条。
4.2 实验过程及结果分析
现有特征选择方法通常采用经验方式来确定特征数目,为了得到各特征选择方法在达到最佳分类性能时的特征数,采用了逐步增加特征数的方法来确定。测试结果如表1和2所示。
从表1和2可以看出:IG和CHI方法随着特征数的增加,分类性能提升较快,而 MI方法需要的特征数则较多,性能提升缓慢。同时,当特征数达到某个阈值时,各特征选择方法性能均会达到最佳状态。但此阈值的获取因特征选择方法的不同、语料库的差异而各有不同,需要大量实验才能得到。

表1 TanCorpV1.0上各特征选择方法在不同特征数下性能比较Table1 Performance of feature selection methods with different number of features on TanCorpV1.0

表2 Reuters-21578上各特征选择方法在不同特征数下性能比较Table2 Performance of feature selection methods with different number of features on Reuters-21578
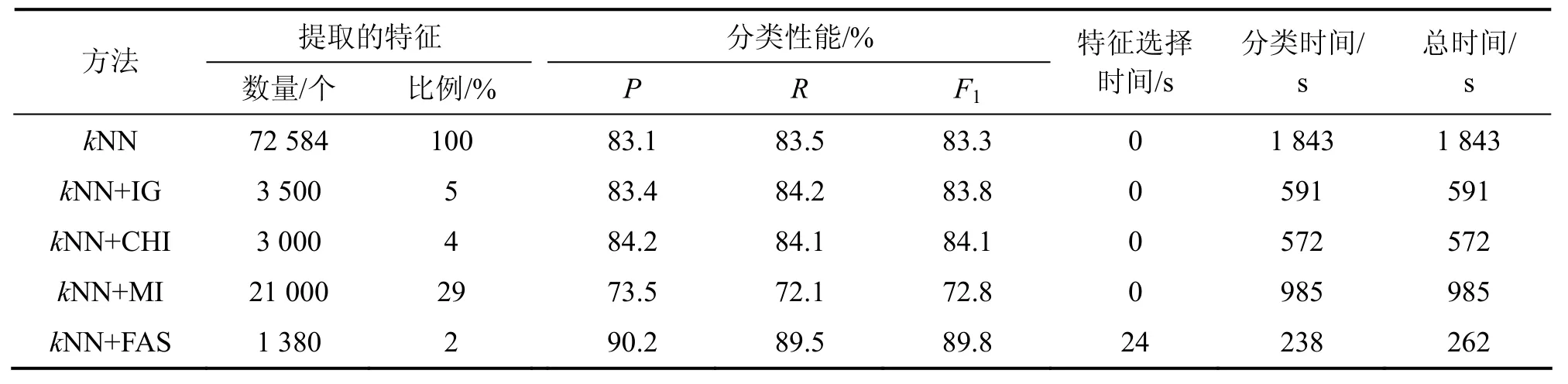
表3 TanCorpV1.0上各特征选择方法分类性能比较Table3 Classification performance comparison on TanCorpV1.0
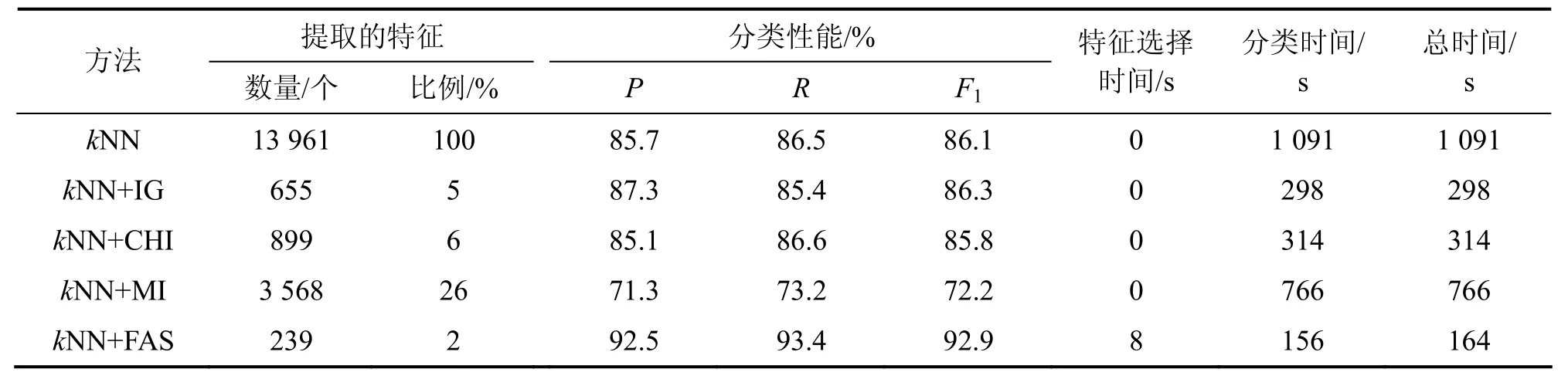
表4 Reuters-21578上各特征选择方法分类性能比较Table4 Classification performance comparison on Reuters-21578
而使用FAS算法在TanCorpV1.0上自动提取的特征数平均为1 380个,在Reuters-21578上自动提取的特征数平均为239个,不仅不需要任何经验知识,而且特征数明显少于已有特征选择方法的特征数。将FAS算法选择的特征集进行分类测试,性能比较结果见表3和4。
从表3和4可以看出:与IG,CHI和MI这3种算法相比,FAS算法提取的特征集具有个数少、分类精度高的特点。kNN方法在TanCorpV1.0上的最好宏平均(F1=84.78%)[26]与 Reuters-21578上的最好宏平均(F1=86.1%)[22]相比,基于FAS算法提取特征集上,kNN方法宏平均提高了5%~6%,说明该算法提取的特征集具有比较高的类别描述能力。
从分类的时间开销来看,虽然FAS算法在特征提取阶段耗费了一定的时间,但从整体上看,远低于其他方法所需的时间。这是因为整个分类的时间主要由特征选择及分类耗时组成。FAS算法的时间复杂度为O(k2×n×m)(k为平均聚类个数,n为特征数,m为类别数),而通常分类算法的时间复杂度至少为O ( m × n2)以上,特征数的多少对整个分类时间耗费起着至关重要的作用。IG,CHI和MI虽然在选择阶段不需要耗费时间,但一方面如何找到最优的特征数需要多次测试,另一方面由于所选特征远较 FAS算法多,直接导致整个分类时间耗费大幅度增加。
从性能比较分析发现,FAS算法提取出来的特征虽然不到IG和CHI算法的结果的一半,但分类性能明显高于后者。性能提升是特征集的选取变化所致。为此,以TanCorpV1.0为例,考察特征集分布情况,如图1所示。
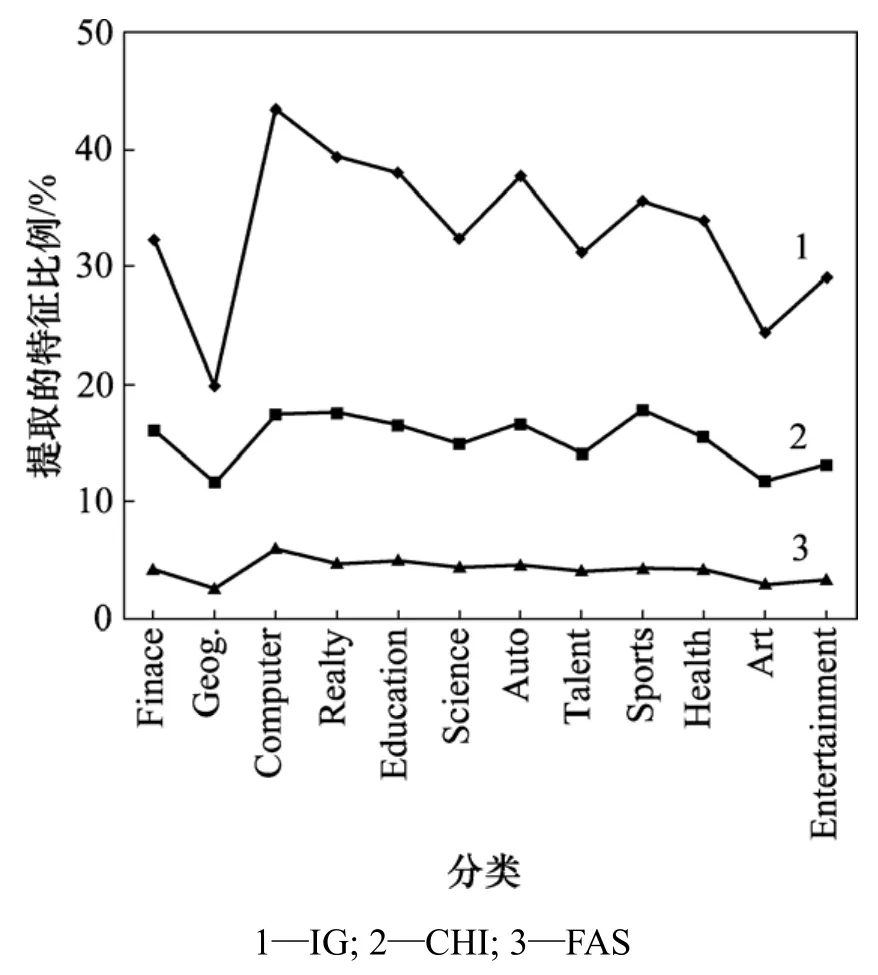
图1 TanCorpV1.0上各特征选择方法特征集分布情况Fig.1 Distribution of feature sets selected by different selection method on TanCorpV1.0
从图1可以看出,FAS算法提取了每个类别较重要的特征集,保证了不同类别之间关键特征大致均匀分布,同时引入的云隶属度概念对特征值的χ2分布进行比较好的修正,因而有效提高了文本的分类性能,这在特征数少的类别中尤为明显。
5 结论
(1) 本文提出的FAS算法提取出来的特征不仅具有特征个数少、分类精度高的特点,而且整体大幅度降低了分类时间。
(2) FAS算法的性能明显比当前主要特征选择方法的性能优。
[1] Charles-Antoine J, John E, France B. Controlled user evaluations of information visualization interfaces for text retrieval:literature review and meta-analysis[J]. Journal of the American Society for Information Science and Technology, 2008, 59(6):1012-1024.
[2] Haruechaivasak, Choochart J, Wittawat S. Implementing news article category browsing based on text categorization technique[C]// Proc of Web Intelligence and Intelligent Agent Technology (WI-IAT 2008). Piscataway: IEEE, 2008: 143-146.
[3] Myunggwon H, Chang C, Byungsu Y, et al. Word sense disambiguation based on relation structure[C]// Proc of Advanced Language Processing and Web Information Technology (ALPIT 2008). Piscataway: IEEE, 2008: 15-20.
[4] Xuerui W, Mccallum A, Xing W. Topical n-grams: phrase and topic discovery, with and application to information retrieval[C]// 7th IEEE International Conference on Data Mining(ICDM 2007). Piscataway: IEEE, 2007: 697-702.
[5] Selvakuberan K, Indradevi M, Rajaram R. Combined feature selection and classification: A novel approach for the categorization of web pages[J]. Journal of Information and Computing Science, 2008, 3(2): 83-89.
[6] 苏金树, 张博锋, 徐昕. 基于机器学习的文本分类技术研究进展[J]. 软件学报, 2006, 17(9): 1848-1859.
SU Jin-shu, ZHANG Bo-feng, XU Xin. Advances in machine learning based text categorization[J]. Journal of Software, 2006,17(9): 1848-1859.
[7] Yang Y M, Pedersen J O. A comparative study on feature selection in text categorization[C]// Proc of the 14th International Conference on Machine Learning (ICML 1997). San Francisco:MIT Press, 1997: 412-420.
[8] Jana N, Petr S, Michal H. Conditional mutual information based feature selection for classification task[C]// Proc of the 12th Iberoamericann Congress on Pattern Recognition (CIAPR 2007).Berlin: Springer-Verlag, 2007: 417-426.
[9] Santana L E A, de Oliveira D F, Canuto A M P, et al. A comparative analysis of feature selection methods for ensembles with different combination methods[C]// Proc of Internation Joint Conference on Neural Networks (IJCNN 2007). Piscataway:IEEE, 2007: 643-648.
[10] Forman G. An extensive empirical study of feature selection metrics for text classification[J]. Journal of Machine Learning Research, 2003, 3(1): 1533-7928.
[11] Kim H, Howland P, Park H. Dimension reduction in text classification with support vector machines[J]. Journal of Machine Learning Research, 2005, 6(1): 37-53.
[12] Rogati M, Yang Y. High-performing feature selection for text classification[C]// Proc of the 11th ACM Int’l Conf on Information and Knowledge Management (CIKM 2002).McLean: ACM Press, 2002: 659-661.
[13] Makrehchi M, Kame M S. Text classification using small number of features[C]// Proc of the 4th International Conference on Machine Learning and Data Mining in Pattern Recognition(MLDM 2005). Berlin: Springer-Verlag, 2005: 580-589.
[14] Soucy P, Mineau G W. Feature selection strategies for text categorization[C]// Proc of the 16th Conf of the Canadian Society for Computational Studies of Intelligence (CSCSI 2003).Halifax: Springer-Verlag, 2003: 505-509.
[15] 李德毅. 不确定性人工智能[M]. 北京: 国防工业出版社,2005: 171-177.
LI De-yi. Artificial intelligence with uncertainty[M]. Beijing:National Defense Industry Press, 2005: 171-177.
[16] 李德毅, 刘常昱. 论正态云模型的普适性[J]. 中国工程科学,2004, 6(8): 28-34.
LI De-yi, LIU Chang-yu. Study on the universality of the normal cloud model[J]. Engineering Science, 2004, 6(8): 28-34.
[17] 李德毅, 刘常昱, 杜鹢, 等. 不确定性人工智能[J]. 软件学报,2004, 15(11): 1583-1594.
LI De-yi, LIU Chang-yu, DU Yi, et al. Artificial intelligence with uncertainty[J]. Journal of Software, 2004, 15(11):1583-1594.
[18] 张光卫, 康建初, 李鹤松, 等. 基于云模型的全局最优化算法[J]. 北京航空航天大学学报, 2007, 33(4): 486-491.
ZHANG Guang-wei, KANG Jian-chu, LI He-song, et al. Cloud model based algorithm for global optimization of functions[J].Journal of Beijing University of Aeronautics and Astronautics,2007, 33(4): 486-491.
[19] Bong C H, Narayanan K. An empirical study of feature selection for text categorization based on term weightage[C]// Proc of the IEEE/WLC/ACM Int’l Conf on Web Intelligence (WI 2004).Beijing: IEEE Computer Society Press, 2004: 599-602.
[20] Li S, Zong C Q. A new approach to feature selection for text categorization[C]// Proc of the IEEE Int’1 Conf on Natural Language Processing and Knowledge Engineering (NLP-KE 2005). Wuhan: IEEE Press, 2005: 626-630.
[21] 胡佳妮, 徐蔚然, 郭军, 等. 中文文本分类中的特征选择算法研究[J]. 光通信研究, 2005, 3(129): 44-46.
HU Jia-ni, XU Wei-ran, GUO Jun, et al. Study on feature selection methods in Chinese text categorization[J]. Study on Optical Communications, 2005, 3(129): 44-46.
[22] 徐燕, 李锦涛, 王斌, 等. 文本分类中特征选择的约束研究[J].计算机研究与发展, 2008, 45(4): 596-602.
XU Yan, LI Jing-tao, WANG Bin, et al. A study on constraints for feature selection in text categorization[J]. Journal of Computer Research and Development, 2008, 45(4): 596-602.
[23] 张光卫, 李德毅, 李鹏, 等. 基于云模型的协同过滤推荐算法[J]. 软件学报, 2007, 18(10): 2403-2411.
ZHANG Guang-wei, LI De-yi, LI Peng, et al. A collaborative filtering recommendation algorithm based on cloud model[J].Journal of Software, 2007, 18(10): 2403-2411.
[24] Dai W H, Jiao C Z, He T. Research of k-means clustering method based on parallel genetic algorithm[C]// Proc of the 3rd Int’l Conf on Intelligent Information Hiding and Multimedia Signal Processing (IIHMSP 2007). 2007: 158-161.
[25] Yang Y, Liu X. A re-examination of text categorization methods[C]// Proc of the 22nd Annual Int’l ACM SIGIR Conf on Research and Development in Information Retrieval (SIGIR 1999). Berkeley, 1999: 42-49.
[26] Tan S, Cheng X, Ghanem M, et al. A novel refinement approach for text categorization[C]// Proc of the 14th ACM Conf on Information and Knowledge Management (CIKM 2005).Bremen: ACM Press, 2005: 469-476.
[27] David L. Reuters-21578 test collection[EB/OL]. [2007-02-04].http://www.daviddlewis.corn/resources/testcollections/reuters 21578/.
