基于CPU+GPU异构计算的编程方法研究
2011-05-22袁庆华沈健炜
冯 颖, 袁庆华, 沈健炜
(解放军总后勤部档案馆, 北京 100842)
0 引言
近年来,基于中央处理器(CPU)+图形处理器(GPU)的混合异构计算系统开始逐渐成为国内外高性能计算领域的热点研究方向。在实际应用中,许多基于CPU+GPU的混合异构计算机系统表现出了良好的性能。但是,由于各种历史和现实原因的制约,异构计算仍然面临着诸多方面的问题,其中最突出的问题是程序开发困难,尤其是扩展到集群规模级别时这个问题更为突出。
1 基于CPU+GPU异构计算的编程方法
1.1 基于CPU+GPU异构计算系统的优势
基于 CPU+GPU的异构计算系统是指在传统计算机系统中加入GPU作为加速部件并配合CPU共同承担计算任务的新型系统。相比于传统的单纯以 CPU作为计算部件的同构系统,异构系统优势明显。首先,GPU能够更出色的完成某些特殊应用,例如对于追求浮点运算性能的应用来说,目前GPU的浮点运算能力已经远远超过CPU,图1说明了近几年GPU与CPU浮点运算能力的对比[1];其次,原先只用于图形处理领域的 GPU正在逐渐向通用计算方向发展,在各GPU生产厂商的大力推动下,一些原先制约GPU通用化的障碍(如硬件结构、编程模型)已经不同程度地得到了克服;最后,当今单纯由 CPU搭建的高性能计算机系统遇到了许多难以克服的问题,例如扩展性问题、功耗问题等,而使用GPU加速部件可以很好地解决这些问题。

图1 CPU与GPU浮点性能比较
1.2 基于CPU+GPU异构计算系统编程方法面临的困难
虽然基于CPU+GPU的异构计算发展迅速,但是由于各种历史和现实原因制约,异构计算仍然面临诸多方面的问题,其中,最突出的是程序开发困难的问题。究其原因:一是 GPU的最初设计目标是专业图形处理而非通用计算,这导致了GPU本身的体系架构对通用计算存在很多硬件制约,例如数据传输限制、缺少数据校验机制、双精度性能偏低等,这使得程序开发人员在使用 GPU进行通用计算时不得不专门考虑这些问题。二是 GPU软件开发的编程模型及编程方式还不成熟,尽管英伟达(NVIDIA)公司推出的计算统一设备架构(CUDA)技术已经大大降低了GPU通用计算开发的难度,但是要程序开发人员转变长期以来的CPU模式X86编程习惯并非易事,而如何处理以往应用中的大量遗留代码也是个挑战。三是异构计算的标准开放计算语言(OpenCL)推出时间还比较短,尽管各 GPU主要生产厂商都已经宣布对OpenCL进行支持,但就目前来看,基于OpenCL的应用和开发还远未形成气候。
2 目前可用的程序开发方法及适用场合
目前,适合于CPU+GPU异构计算的程序开发方法可以大致分为以下四类:基于底层图形应用程序接口(API)的开发方法、基于低层次抽象的轻量级 GPU编程工具、基于高层次抽象的函数库或模板库和基于高层次抽象的使用编译器的方法。
2.1 基于底层图形API的开发方法
这是GPU通用计算领域早期使用的主流方法,在新的GPU上一般仍可使用。这种方法要求开发者必须熟悉GPU硬件底层图形 API,并需要设法将程序映射到图形处理过程。一般使用开发图形库着色语言(GLSL)等图形绘制语言进行编程。
早期的GPU产品都是基于分离渲染架构,即图形渲染过程分为顶点处理、片段处理等几个过程,这时的 GPU可编程能力比较差。随着2001年GeForce3的出现,顶点级可编程开始普及,人们开始使用它进行了通用编程。到了2002年人们开始利用纹理着色(Texture Shader)结合基于寄存器组合器(Register Combiner)来求解扩散方程,而到了2003年像素级可编程性出现,很多人开始利用像素程序来求解一般代数问题,甚至有限差分方程组求解(PDEs)和优化问题的求解。这个阶段的GPU都是通过底层图形API向图形程序员提供可控制能力。最常见的图形API有两种:开发图形语言(OpenGL)和DirectX。OpenGL作为事实上的工业标准已为学术界和工业界所普遍接受;DirectX作为微软视窗的标准,可以根据 GPU新产品功能的扩充与进展及时定义新的版本以扩充新的接口。
2.2 基于低层次抽象的轻量级编程工具
CUDA是一种将GPU作为数据并行计算设备的软硬件体系,它是一个完整的用于通用目的计算的图形处理器(GPGPU)的解决方案,提供了硬件的直接访问接口,不用像传统方式一样必须依赖图形API来实现GPU的访问。CUDA采用 C语言作为编程语言,提供大量的高性能计算指令开发能力,使开发者能够在GPU计算能力的基础上建立起一种高效的密集数据计算解决方案。CUDA架构如图2 所示[2]。
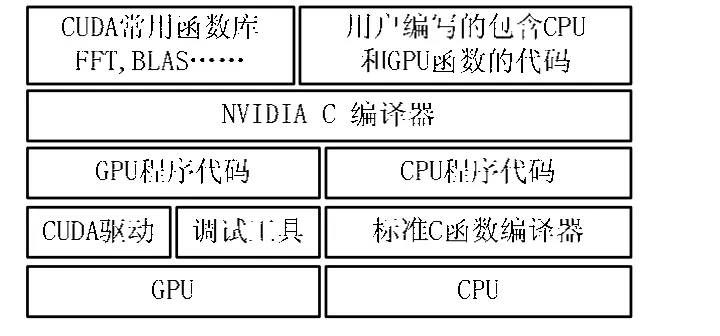
图2 CUDA架构图
OpenCL是第一个面向异构系统通用目的并行编程的开放标准和统一的编程环境,适用于CPU、GPU、Cell类型架构以及DSP等其他并行处理器。作为开放标准,可以为CPU、GPU和其他分离的计算设备(这些设备被组织到单个平台中)所组成的异构群进行编程。作为并行编程框架,OpenCL目前包括一种开发语言、API库和一个运行系统来支持软件开发,不必将算法映射到底层图形API上。
2.3 基于高层次抽象的函数库或模板库
CUDA快速傅里叶变换(CUFFT)是一个利用GPU进行傅里叶变换的函数库,提供了与广泛使用快速计算离散傅里叶变换的标准C语言程序库(FFTW)相似的接口。不同的是FFTW操作的数据存储在内存中,而基于CUDA离散傅里叶变换(CUFFT)的操作数据存储在显存,不能直接相互取代,必须加入显存与内存之间的数据交换,进行封装后才能替FFTW库。CUDA线性代数基础子程序库(CUBLAS)是一个基本的矩阵与向量的运算库,提供了与BLAST相似的接口,可以用于简单的矩阵计算,也可以作为基础构建更加复杂的函数包,如线性代数程序包(LAPACK)等。CUBLAS操作的数据也存储在显存中,同样需要封装后才能替代基本线性代数子程序(BLAST)中的函数[3]。
2.4 基于高层次抽象的使用编译器的方法
基于高层次抽象的使用编译器的方法是指通过使用指示语句、算法模板以及十分复杂的代码分析技术、编译器或语言运行时系统自动生成GPU内核程序。
PGI x86+GPU编译器是意法半导体子公司Portland Group的高性能并行编译器产品。它引进一组新指示语句(PRAGMAS)以用来指示哪一部分的代码可以被映射到GPU上执行。指示语句定义了内核程序区域,描述了循环结构以及它们与GPU上的线程块和线程之间的匹配。指示语句同时也用于指示哪个数据需要在主设备和GPU存储器之间复制。
超立方体大规模并行处理语言(HMPP)一个基于标签语法的多语言程序设计环境,利用它能够使软件和目标硬件设备保持独立,提供将已有应用程序部署到 GPU的有效工具。它同时拥有CUDA和OpenCL代码生成器,使用HMPP目标代码生成器可以改进硬件加速的关键程序段的性能。代码生成器用来从原来的C或Fortran程序中提取可以并行化的部分,并将其转换为CUDA或者OpenCL代码,不需要使用新的GPU开发语言重写程序。HMPP工作平台包括一个C和 Fortran的编译器、代码生成器以及一个无缝集成进开发环境中的运行时系统,HMPP工作平台架构如图3。
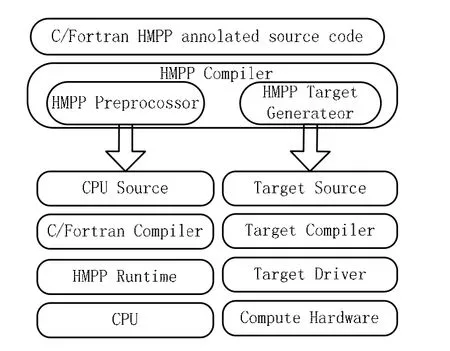
图3 HMPP工作平台架构图
2.5 多GPU设备和GPU集群环境下的程序开发
在多GPU设备环境或GPU集群环境下开发程序,除了上面提到的四种程序开发技术之外,还需要其他必要辅助技术。一般来说,管理多个GPU设备可以使用OpenMP技术,在使用CUDA时还能够使用CUDA提供的特殊功能API来管理多GPU设备;在管理由CPU+GPU异构系统作为节点构造的集群时,可以使用 MPI技术,也可以使用 Charm++技术。具体应用中,OpenMP和MPI配合使用的情况居多。
3 现有编程方法的适用场合及优缺点分析
对于在 GPU通用计算上发展阶段积累了大量基于底层图形API方法程序的开发者来说,继续使用基于底层图形API方法仍然适用,这样可以解决如何处理遗留代码的问题,不用对原来的程序做太多修改。缺点主要表现为:首先,编程人员必须编写控制图形流水线的程序,如分配纹理存储、构造图形素元等,这要求编程人员对图形API以及GPU硬件特点与限制需要有详细了解。其次,编程人员仍然需要利用纹理、三角形等图形素元表达他们的算法。此外,这种方式在新的基于统一渲染架构的 GPU产品上运行时的代码执行效率会有些不足,在开发新程序时相比其他方法也没有优势。
对于那些采用少量专业领域算法的应用程序,这种场合中开发者往往无法在标准函数库找到对应程序,这时最佳的开发方法是使用诸如CUDA、OpenCL之类的基于低层次抽象的编程工具。在这种情况下,影响性能的关键代码往往集中于少量程序段,由开发者完全自己编写这些代码是切实可行的,这样可以充分利用 GPU的具体数据结构以及其他的优化方法,以获得最佳的加速效果。缺点是一般需要学习一门新的编程语言,不适用于遗留代码较多的场合。
对于大部分运行时间都用于执行标准函数的应用程序,使用 GPU加速版本的标准函数库可以很容易地提高执行效率,而获得效率的关键是尽量减少 GPU与主机之间的通讯。基于高层次抽象的函数库或模板库方法的缺点是这类函数库的灵活性稍差,并且有可能造成多余的存储器访问。
对于大量使用专业领域算法应用程序的场合,在标准函数库内找不到对应,而开发者自己编写全部代码又不现实,这时可以使用基于编译器的方法。由于发展时间较短,目前这种方法也存在很多缺点,以Portland Group并没有很好地隐藏内核程序并行化的复杂度,用户仍需要去做所有较大的工作,例如如何将嵌套循环结构映射到底层的流处理器。
4 结语
CPU+GPU异构计算模式在当前的高性能计算领域逐渐成为热点研究方向。文中分析了基于CPU+GPU异构计算模式程序开发面临的主要困难,总结了当前主要的可用解决途径和研究方向,并对各种编程方法的适用场合和各自的优缺点进行了详细分析。目前,GPU产品的硬件架构在向着有利于程序设计的方向不断改进,学术界和工业界对基于CPU+GPU异构计算的编程方法研究也在快速发展,可以预见,随着 GPU编程方法研究的不断深入,基于 CPU+GPU的异构计算系统将会在高性能计算领域发挥更大的作用。
[1]NVIDIA Corporation. CUDA Programming Guide 2.3[Z/OL].(2009-11-02)[2010-06-03].http://developer.nvidia.com/objec t/cuda.html.
[2]NVIDIA Corporation. NVIDIA Tesla GPU Computing Technical Brief 1.0[Z/OL]. (2007-5-05)[2010-06-03]. http://developer.nvidia.com/object/cuda.html.
[3]张舒, 褚艳利. GPU高性能计算之CUDA[Z]. 北京:中国水利水电出版社, 2009.
