开发人员升级至ASE 15.0的10大理由(十)
2011-05-08赛贝斯软件有限公司
10.3.1 分区和插入性能
考虑插入的性能。Sybase最早对于分区的努力将能追溯至版本11.0,它旨在帮助查询性能。尽管如此,真正的驱动原因是降低或消除堆表最后一页的竞争。那时,Sybase仅支持全页锁定(APL),因此,并发的表插入常常被序列化到表的最后一页上。但是,它充其量只是些许的帮助,因为对于不断增加的数据元素,索引竞争依然存在(例如顺序列或当前时间)。随着11.9版本中数据行锁定的发布,通过分区来解除竞争的需求不再。但是,11.x/12.x中的轮循分区模式对插入性能帮助很大,因为它使用用户的SPID来决定用户数据将插入哪个分片中。不幸的是,在ASE 12.5及之前的版本,没有办法分别将特定的分区分片放置于与其他分片不同的指定段上—因此,没有达到完整的IO并发效果。ASE 15.0改进了轮循分区,支持不同分区放置于不同段,映射至不同设备上,从而支持IO并发。
使用分区需要考虑的一个方面就是使用全局索引或本地索引。全局索引—缺省项—通过单独的b-树结构实现如图23。

图23 分区表上的全局索引
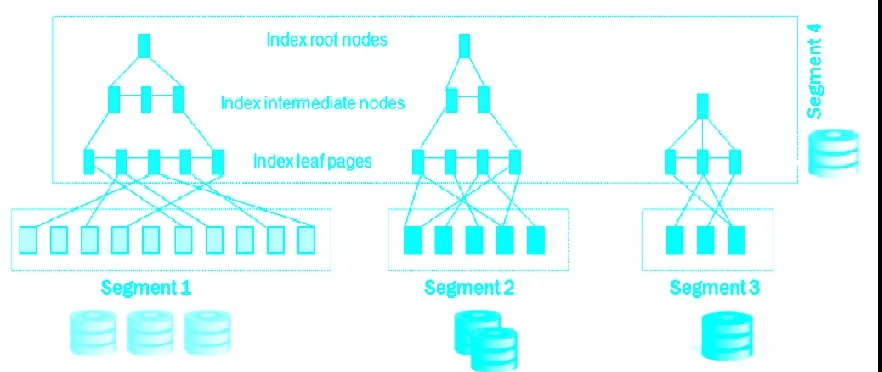
图24 分区表上的本地(分区)索引
正如所展示的,索引作为一个整体未分区的结构存储。另一方面,本地(分区)索引使用了与附表相同的分区模式和分区键进行分区。本地索引的结果类似,如图24。
注意索引本身是分区的。每种方法各有优劣,如表18。

表18 全局、本地(分区)索引优劣
在本地索引中(2),(3)部分的优势需要进一步解释为何其优势不如期望的那么大。根据每个分区的行数和索引键大小,本地分区可能中间级别的节点较少—即“较小”的索引高度。正如上面所显示的,原先的索引高度为4,而分区索引二的高度为三,分区三的高度为2。
10.3.2 分区与插入性能
这将能稍微改善每个插入的性能,因为需要更少的IO索引树遍历来插入每个索引键值。例如,假设在上表上有5个索引。在未分区的表中,将遍历主键/聚集索引以寻找行的插入点(读取索引树需要4个IO,1个用于读取数据页,加上写入数据页和写入索引页节点)。所以不得不遍历其他4个索引来寻找索引插入点(4个IO用于读取每个索引树加上对每个叶页面的写入)。假设不会发生页面分列、溢出页面等,一个对表的插入成本(只考虑读取)如表19。

表19 插入成本读取
作为对比,可考虑在范围分区的最末端分区上的插入。最常见的范围分区实现是“翻滚分区”,最后一个分区就是当前的插入点。结果,最初的分区插入可能只会有一个索引级别。假设如上面展示的,它达到了最大值2,则读取的IO成本应如表20。

表20 IO成本读取
也不是太惊人—一半。该问题可以很快地被引申至查询的执行也只需要一半的时间。这并非必须。从一个独立用户的角度,这可能不明显。例如,很可能索引树的最近部分都在数据缓存中—因此,所有的读取都是逻辑读取。考虑到逻辑读取的速度(内存访问),节省的时间可能只是几毫秒。可采用以下测试来证明:
(1)创建了一张有5个索引的数据行锁定表(未分区)。该表预装了约3千万行数据。然后在单独的主机上有20个客户端线程使用延迟提交和完整的准备语句执行1百万个原子插入。客户端线程也可放在相同的主机上—或者就简单地在ASE中进行处理,目的只是要模仿更为真实的配置。
(2)该表被删除,随后重建,使用基于date列上的30个分区。该表仍有5个索引—但是其中之一被创建为全局索引。最初的3千万行数据被插入前面的29个分区中。相同的20个客户端线程将1百万行数据插入最后(第30个)分区中。
(3)使用基于date列的30个哈希分区重复第二项测试。结果将使30个分区中值分布均衡。
(4)使用轮循分区(30个分区)重复测试。由于轮循分区不支持本地索引,5个索引都被创建为全局索引。
(5)用30个范围分区重复同样的测试—单本次都使用本地索引。
(6)同样的测试在全部本地索引的哈希分区上重复。
结果如表21。

表21 表分区索引数据
正如可以看到的,将全局索引改变为本地索引将只能节省在大约160 s中5 s~6 s—或大约4%的时间。其次,范围和轮循分区也只仅仅比基表插入快一点—除非范围分区表仅包含本地索引。另一方面,哈希分区落后于未分区表,除非将全局索引改变为本地索引。哈希值在30个分区中的分布被验证有2%的中间数值,因此并非是非平衡的模式造成的。值得注意的是,如果仅有20个客户端,轮循模式仅使用30个分区中的20个—因此它是非平衡的。这对轮循分区是正常的。以上部分的结论是什么呢?
(1)如果因插入性能而分区,在全页锁定下将得到最佳效果,因为严格分区是降低竞争的手段。另一替代方法是仅使用数据行锁定。比数据行锁定还好的的是基于哈希的分区(以降低竞争),因为本地索引将能在索引级别帮助缓解竞争(与轮循分区比较)。
(2)单独插入在分区上提升最小,因为索引的高度将由在缓存中的逻辑IO弥补,因为它们已经够快了而额外的索引级别并不会太显眼。
(3)可能能在真正小且持续小分区上获得提升,因为与未分区表相比,索引高度可能有几个或更多级别的巨大差别。
实际上,均衡分区对插入的优势可忽略不计,而对至少两个有序较小分区的插入可能优势更大。
10.3.3 分区和查询性能
如果分区对插入性能没有太大帮助的话—那么减少的索引高度何时才能起作用呢?答案是在包含了连接的查询中…当然也有可能有伤害。先来看看它的优势。在上例中,对表新增了一百万行。我们假设在夜里会运行一些批处理任务,用于鉴别需要进一步处理的特殊记录。典型的批处理任务看起来像:
select row _id=identity(20),
into #rowsToBeProcessed
from trans _detail
where
and tran_date between
update trans_detail
set
from #rowsToBeProcessed r, trans_detail t
where r.
普通得就像电灯开关一样。不同之处是通常只影响一小部分子集的更新被嵌入循环中以避免竞争。
继续假设该批处理将在最近的行中鉴别出10%的行—本例中是10万行。基于3 100万行的不同分区模式的统计结果见表22。

表22 分区模式统计结果
在本例中,再次显示出只节省了10万次逻辑IO– 它意味着更少的物理IO因为不太可能所有需要的行都在内存中—它能从根本上减少执行时间。注意,即使是全部缓存的情况下,10万个逻辑IO也不足以弥补额外的查询编译和开销复杂度—但是也仅讨论了3 000万行数据。包含了1亿条数据的分区表可能会有优势。和原来一样,可能区别很大。
区别一方面可能依赖于查询的类型。例如,考虑以下典型的范围查询:
-- list all the transactions for a customer in last 10 days
-- (local) index on customer_id, tran_date
select *
from trans_detail
where customer_id =
and tran_date between dateadd (dd,-10, getdate ()) and getdate ()
现在,假设DBA成功说服了用每天一个分区的范围分区来简化维护需求。在该情况下,查询比未分区表需要更长时间,使用更多IO!
未分区表—查询将遍历索引寻找第一行(10天前的)然后执行表或索引范围扫描直至当前行。
范围分区表(每天一个分区)—查询将遍历10个分区中的每个本地索引,然后在每个分区中执行表/索引范围扫描来找到前10天的数据。
假设在高度为8的索引上每天100个事务,且5个事务一页,则未分区表将使用总计8(索引) + 200(扫描)=208个逻辑IO。范围分区表将需要8*10=80(索引遍历) + 10*20 = 200 (扫描),总IO成本为280。虽然区别颇小,但请考虑如果查询跨越一年的问题—它将会有365个分区。不仅如此—并非所有的数据都在内存中—使用未分区表,服务器将选择异步预取(APF)和大IO来从磁盘中快速读取数据,而在较小的分区中可能需要对每个扫描选择开启APF和大IO。这将造成总体成本偏高—可能到达优化器选择另一低成本索引的程度(或甚至是分区扫描),如果统计值陈旧。
关键要考虑的因素是要确保分区范围与业务需求一致。例如,大部分商业操作是基于季度的—因此按照完整的季度范围的日期分区将能满足大部分查询(诸如典型的季度销售、季度的语句和季度与季度间的分析)能完全利用APF和大IO。而DBA可能感到维护影响,考虑以下内容:
(1)大部分大型维护操作都被安排在周末—通常可能一个季度只有一次。因此,像归档这样的大型操作可能每个季度只发生一次—粒度更小的分区没有帮助。
(2)在某天发生的销售将可能在后续几天有诸如递送、计费等销售后的活动影响事务。因此,统计更新(可能)需要在分区上每周执行一次。
(3)在一些业务中,大部分销售都是季度的最后几个星期中完成的—因此许多分区可能会是空的—或接近于空。
再次强调,需求可能是不同的—但重要的是更了解业务需求的开发人员,而不是DBA,需要与DBA一起确保分区的粒度能满足大部分的查询范围。显然是不利的方面。
但是,也有一个有利的方面。还记得前面作为分区实现,跨越多张物理表(用于积极聚合)的联合视图?语义分区对其有很大的优势。在原来的讨论中,我们注意到在allrows_mix情况下,优化器选择使用将所有数据联合至工作表中,对工作表排序然后再对销售数据使用和并连接。使用工作表来做联合是因为优化器不清楚哪些数据在哪些“分区”(或表)中。例如,除了应用程序逻辑外—没有别的办法能阻止2008数据出现在2007“分区”中。使用语义分区,优化器了解哪些数据在哪些分区中并能避免不必要的union all/合并排序。它列出了每种方法的优劣,如表23。

表23 语义分区各种方法的优劣
需要记住的是—不是二者必须选一—通过在一个或多个可能使用了语义分区的物理表上使用联合视图“分区表”,两者可以结合使用。
11 结束语
ASE 15.0.x为应用程序开发人员提供了一些有趣的功能以及必须从较早版本升级的理由。从新的较大数据类型—到可读性较强的#temp表名—到函数索引和计算列—SQL用户定义函数和替代触发器—到查询优化的改善—对开发人员友好的新工具的功能—到XTP一览—到表分区。
正如展示的,通常当这些功能结合使用时,他们的威力才能被真正认识。不论是为“自动解析”关键元素而在XML上建立的函数索引和计算列—还是在联合视图上的替代触发器和DSS优化,诸如跨OLTP和归档系统的积极聚合。结果证明了Sybase ASE的新发布不仅是对DBA需求的另一个升级平台—而且为开发人员提供了满足当今对高容量/高速度业务环境中涌现出的应用程序开发需求。
