基于RFID的二进制防碰撞算法的改进
2011-05-07王道强李志鹏
王道强,李志鹏
(东北林业大学交通学院,哈尔滨150040)
1 RFID系统中的二进制防碰撞算法
二进制防碰撞算法是基于二进制树理论,是把产生碰撞的标签分裂成两个结点0和1,若结点1中的标签继续发生碰撞,则再次分裂分成10和11两个结点[1]。依此类推,直到识别出结点1中的所有标签。如图1所示。
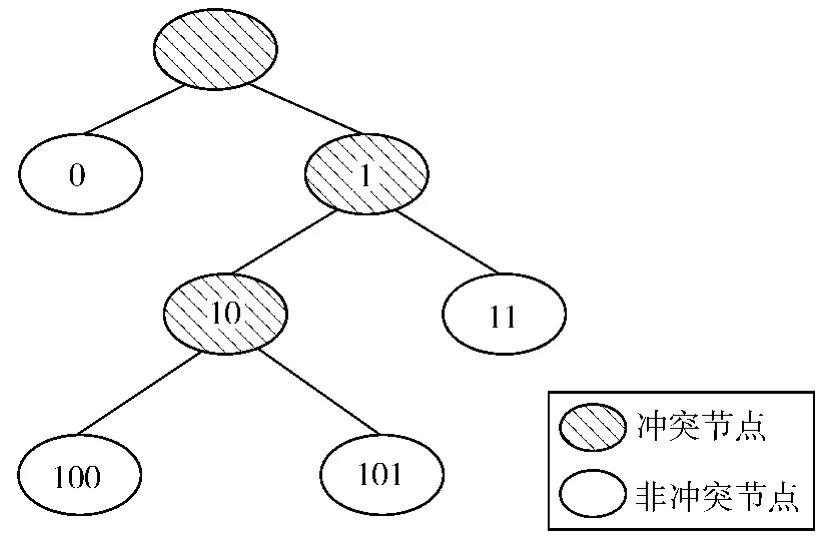
图1 二进制防碰撞算法模型Fig.1 Binary anti-collision algorithm model
2 二进制搜索 (Binary Search)算法
在二进制防碰撞算法的基础上提出了二进制搜索算法,这是一种无记忆的算法,为了在一组电子标签中选择任意一个,阅读器发出一个请求命令,有意识地将电子标签传输时的数据碰撞引导到阅读器上。阅读器的命令查询的是一个比特前缀,只有序列号与阅读器查询命令前缀相符的标签才能响应阅读器,并回送其序列号,当有多个标签同时响应的时候,阅读器把下一次发送的查询命令的前缀增加一个比特0,通过不断的增加命令前缀,使阅读器能够识别所有的标签[2]。
2.1 算法的命令
(1)REQUEST:请求命令,该命令发送一组序列号作为参数给电子标签。若电子标签的序列号小于或等于阅读器发送的序列号,则将自身的序列号回送给阅读器。
(2)SELECT:选择命令,用某个事先确定好的序列号作为参数发送给电子标签。具有相同的序列号的标签将此作为执行其他的命令 (例如读出和写入)的切入开关,即选择了标签。
(3)READDATE:读出数据命令,选中的电子标签将其存储的数据发送给阅读器。
(4)UNSELECT:去选择命令,取消一个选中的标签,标签进入无声状态,这种状态中的电子标签完全是非激活的,对收到的REQUEST命令不作应答[3]。
2.2 算法的原理和执行过程
假设阅读器周围存在着四个电子标签T1、T2、T3、T4,并 且 它 们 的 ID分 别 为 10111101、10101111、10110101、10100111。
第1步,阅读器在其工作区域内发送命令REQUEST(11111111),标签序列号小于或等于阅读器命令的与阅读器进行通信。阅读器对应答的标签进行译码,得到解码数据101XX1X1,判断出发生碰撞的比特位D4、D3、D1[4],进行如下处理:将D4位置“0”,高于D4位的不变化,低于D4位的置“1”,得到下一次命令所需要的序列号10101111。
第2步,阅读器发送命令 REQUEST(10101111),标签T2和T4应答,对标签进行解码,得到解码数据为1010X111,将最高碰撞位D3置“0”,得到下一次命令所需要的序列号10100111。
第3步,阅读器发送命令 REQUEST(10100111),只有标签T4应答。无碰撞产生,阅读器处理完标签T4后,使其进入无声状态,接着重复上述过程直到识别所有的标签为止。识别过程见表1。
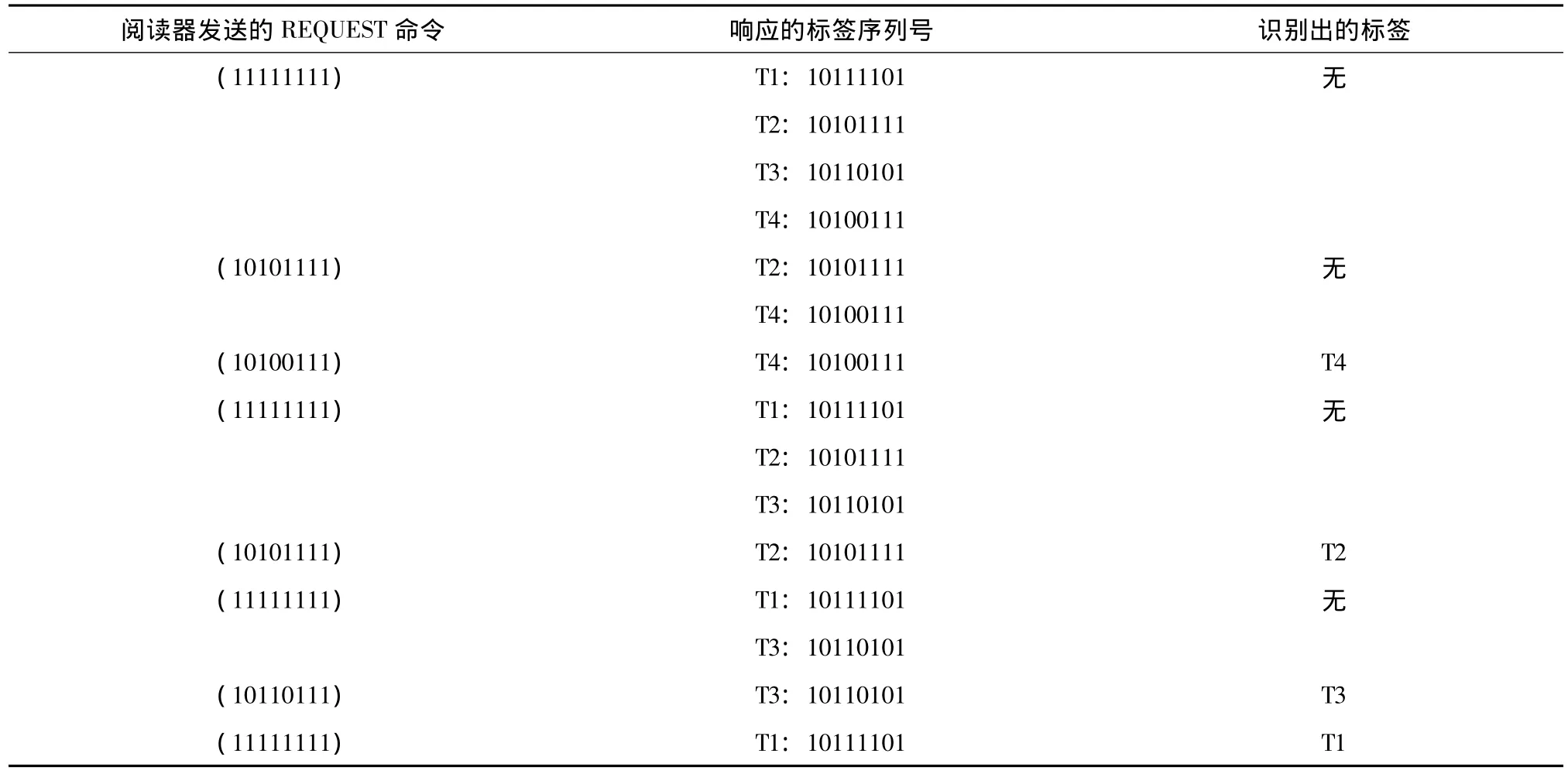
表1 二进制搜索算法的实现过程Tab.1 Realization of binary search algorithm
3 改进的二进制防碰撞算法
二进制搜索算法有着明显的缺陷,阅读器发给每个标签的比较序列,其中有用的信息只包含在高于上次碰撞碰撞位X比特的高位之中,而且每一次识别标签之后都要从头开始查询,算法执行时间较长,为了解决这些缺陷,本文提出了改进的算法。
3.1 算法编码原理
为了能够在算法中准确的辨认出数据碰撞的比特位,改进的算法采用Manchester编码[5]。该编码也叫做相位编码 (PE),是一个同步时钟编码技术,是用电平的跳变 (上升沿/下降沿)来表示数值位。这里,虚线所在位置由高电平跳变到低电平,编码为逻辑“1”;由低电平跳变到高电平,编码为逻辑“0”,若不产生跳变,则视为非法数据,当作错误数据识别。当两个或两个以上标签同时返回的数位出现不同值时,则上升沿与下降沿相互抵消,导致无状态跳变,可知阅读器的数据出现碰撞,出现了错误,应当进一步搜索,如图2所示。
3.2 算法的原理和执行过程
在二进制搜索算法命令的基础上,新增两个命令。
(1)新增命令REQUEST(ID,1):这里的ID的取值表示的是阅读器第一次与标签进行通讯之后,对标签的序列号进行译码,判断出产生碰撞的比特位,我们规定把产生碰撞的比特位置“1”,没有产生碰撞的比特位置“0”,从而得到的下一次寻呼的序列号。
1表示的是先处理锁定的标签碰撞位中最高位为1的标签组。
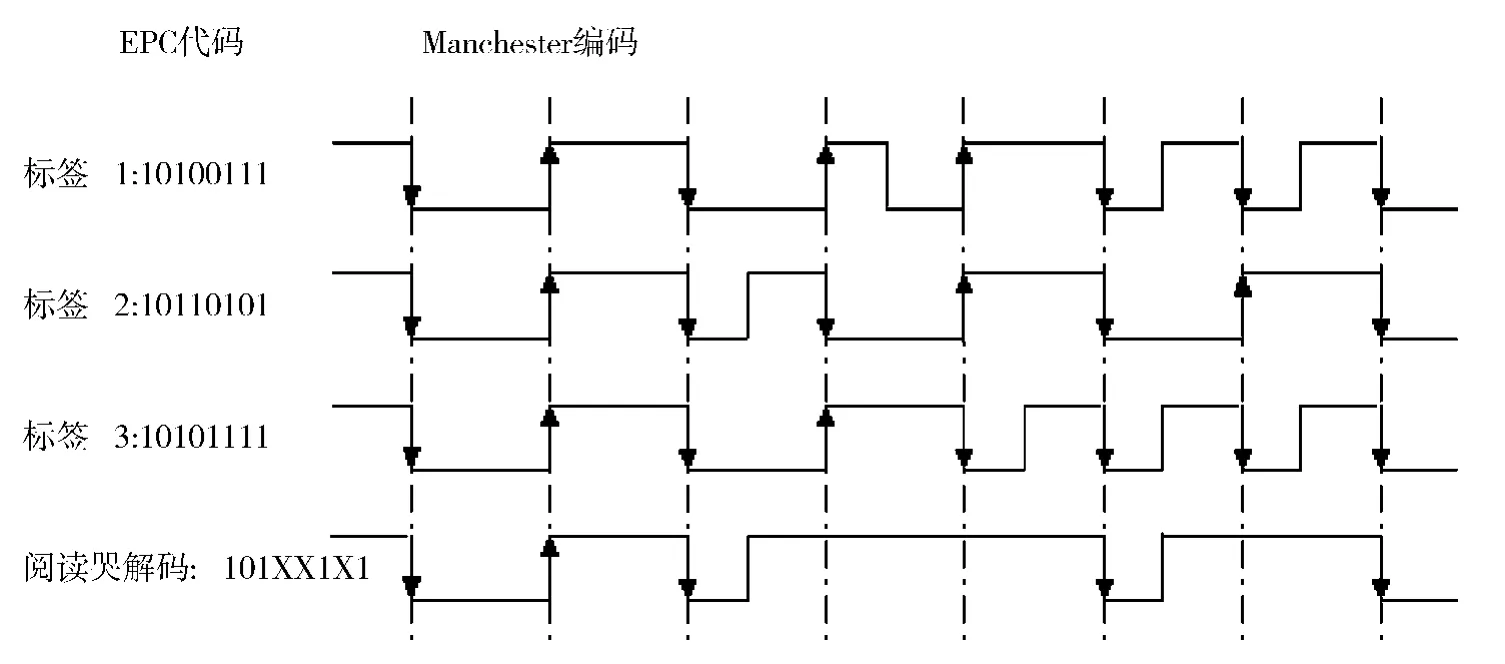
图2 Manchester编码得到的冲突位Fig.2 The conflict bit in Manchester coding
(2)新增命令REQUEST(ID):
这里的ID的取值表示的是阅读器在进行REQUEST(ID,1)命令之后,如果标签继续产生碰撞,同样我们规定把产生碰撞的比特位置1,没有产生碰撞的比特位置0,则标签锁定阅读器第一次发出的ID中值为1的比特位,在接下来的防碰撞处理过程中,参与数据发送的仅仅是锁定的几个产生标签碰撞的比特位,然后通过对标签的译码所得到的下一次寻呼的锁定序列号[6]。这里产生碰撞的标签中,首先将锁定的所有比特位中的最高位的值为1的标签回送自己的序列号给阅读器,并且返回锁定位除最高位以外的其他锁定位。
改进的二进制算法的工作流程图如图3所示。
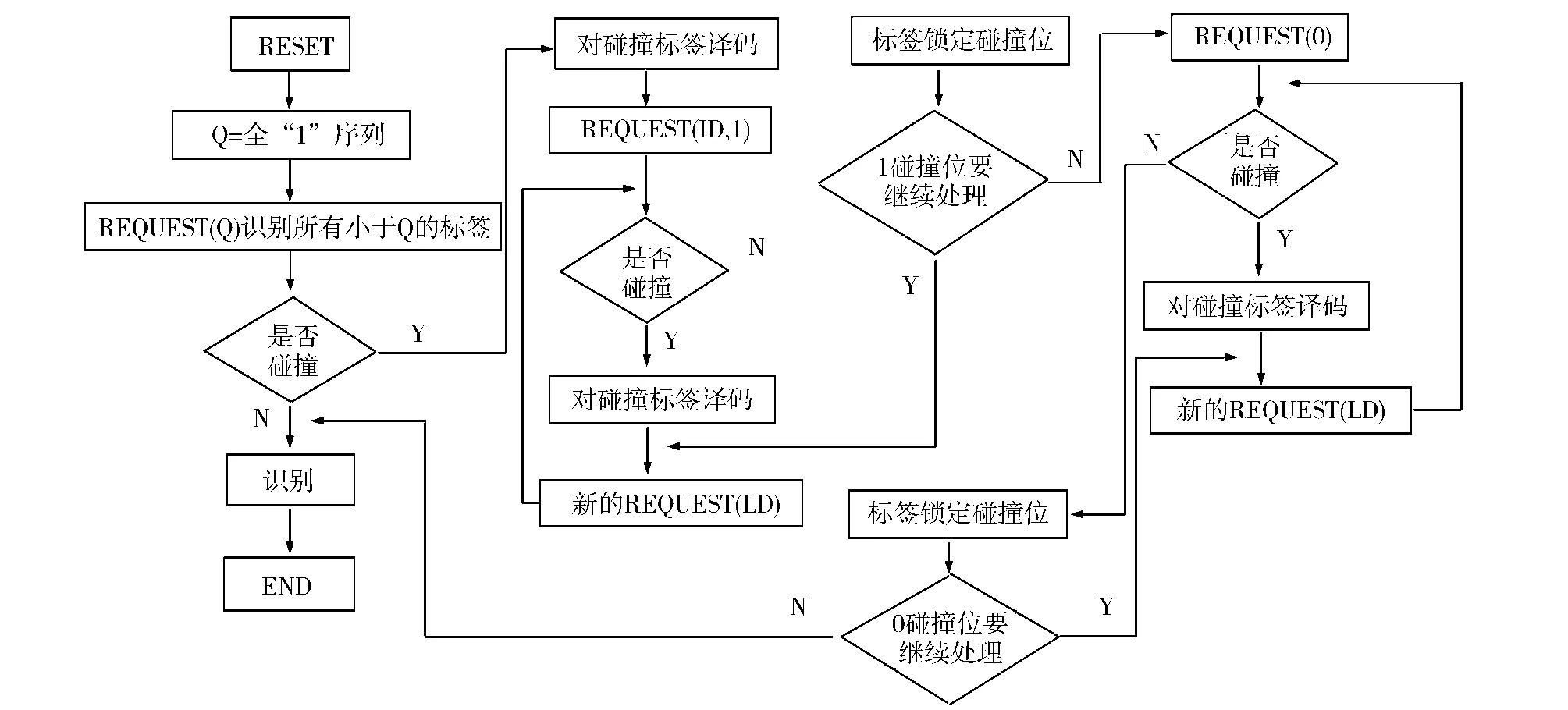
图3 改进的二进制防碰撞算法的工作流程图Fig.3 Work flowchart of the improved binary anti-collision algorithm
改进的二进制算法的主要工作步骤为:
第1步,阅读器在其工作区域内发送 REQUEST(全“1”序列),标签ID小于或等于阅读器命令的与阅读器进行通信。
第2步,阅读器对应答的标签进行译码,若无碰撞产生则识别标签,使其进入无声状态。
第3步,若有碰撞产生,则对标签进行译码,将产生碰撞的比特位置“1”,未产生碰撞的比特位置“0”,得到新增命令REQUEST(ID,1)。
第4步,阅读器发送REQUEST(ID,1),标签再接收到该命令后,将阅读器的命令ID与自己的序列号进行比较,锁定产生碰撞的比特位,锁定位中比特位最高位为1的标签优先进行作答,并将除锁定位以外的剩下几位回送给阅读器[7]。
第5步,阅读器判断回送的标签序列号是否产生碰撞,若无碰撞产生则识别标签,使其进入无声状态,若有碰撞产生,阅读器对回送的标签序列号继续进行译码,判断产生碰撞的比特位,将发生碰撞的最高比特位置1,高于该碰撞位的不变。低于该碰撞位的舍去,得到新增命令REQUEST(ID)。
第6步,阅读器发送REQUEST(ID),继续判断有无碰撞,每当顺利的识别标签之后,都将采用后退策略,返回上一次产生碰撞的结点,识别结点的另一个分支,直到把锁定碰撞位的最高位为1的标签组全部识别完。
第7步,阅读器在识别完锁定碰撞位最高位为1的标签组之后,发送命令REQUEST(0),识别锁定碰撞位最高位为0的标签组,过程原理同第5步和第6步。直到识别所有标签结束。
下面举例介绍改进算法工作的具体实现过程:
假设阅读器周围存在着四个电子标签T1、T2、T3、T4,并 且 它 们 的 ID分 别 为 11100010、11110011、11100011、10100011。识别标签 T2的具体操作流程如图4所示。

图4 改进的二进制搜索算法的实例操作流程Fig.4 Procedures of the example based on improved binary search algorithm
4 MATLAB 仿真分析
通过matlab仿真比较分析了在不同的情况下,改进的算法相比于二进制搜索算法的优势。
(1)通信次数。二进制搜索算法识别n个标签所需要的寻呼次数为QBS=n· [integ(log2n)+1],integ()表示向上取整函数[8]。而改进的算法的通讯次数Q改=2n-1,如图5所示。
从图可以看出,改进的二进制算法在阅读器的寻呼次数上明显低于二进制搜索算法,而且随着n值的增大,改进的二进制算法优势越明显。
(2)传输时延。传输时延就是阅读器从开始发送数据到数据全部发送完毕所需要的时间[9],二进制搜索算法和改进的二进制算法的传输时延分别为:
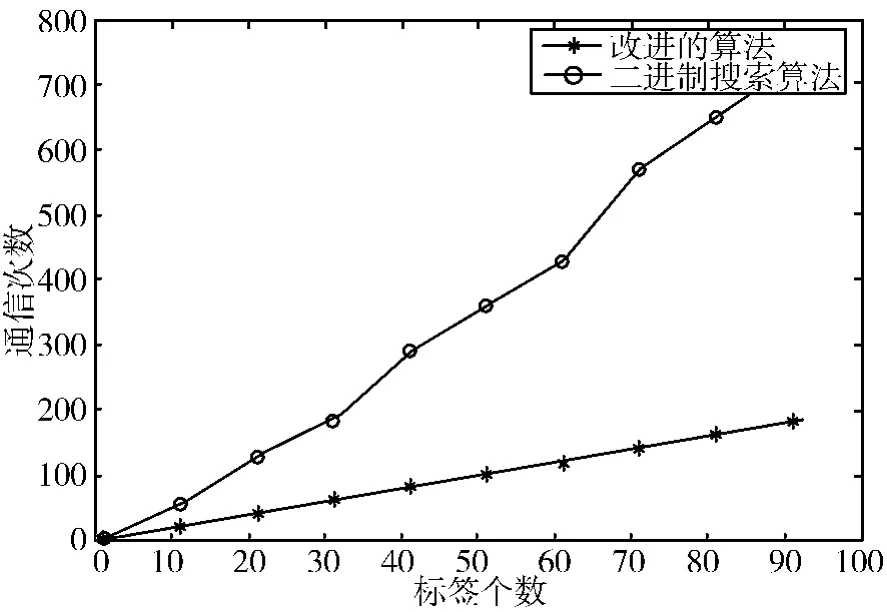
图5 改进的算法与二进制搜索算法的通信次数比较Fig.5 Comparison on the communication frequency of improved algorithm and binary search algorithm
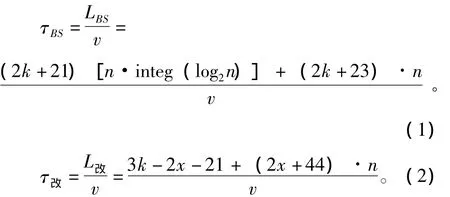
其中x的取值范围为 [integ(log2n),k]。
假设标签ID的长度k的取值为64 bit,传输速率为100K bit/s,,产生碰撞的比特位数x取k时,得到算发法的传输时延随标签个数n的变化关系如图6所示。
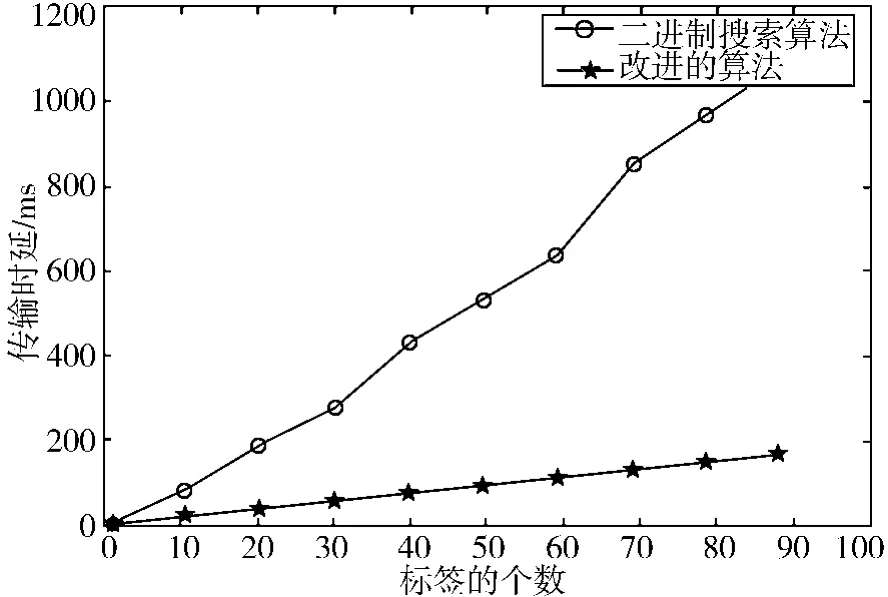
图6 改进的算法与二进制搜索算法的传输时延比较Fig.6 Comparison on the transmission delay of improved algorithm and binary search algorithm
从图6中可以看到即使x取最大值k,改进的二进制算法的传输时延都要小于二进制搜索算法。
(3)吞吐量。吞吐量代表有效传输的实际总效率[10],二进制搜索算法和改进的算法的吞吐量分别为:
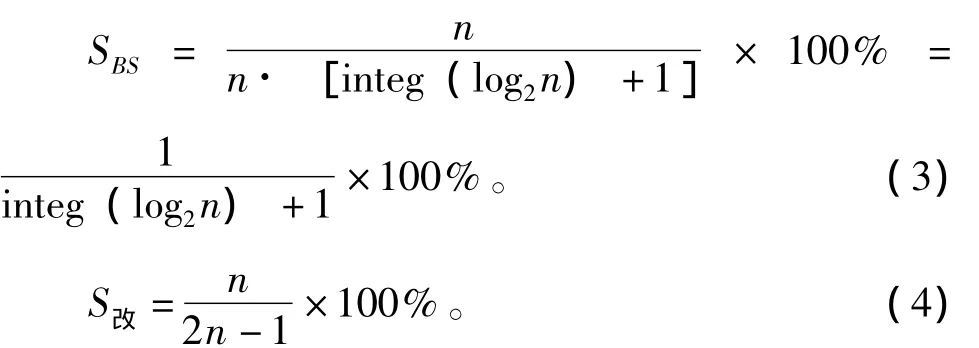
改进的算法和二进制搜索算法在吞吐量上的比较,从图中可以看出在吞吐量上改进的算法的明显优于二进制搜索算法,随着n的增大,改进的二进制算法吞吐量趋近于50%如图7所示。
5 结论
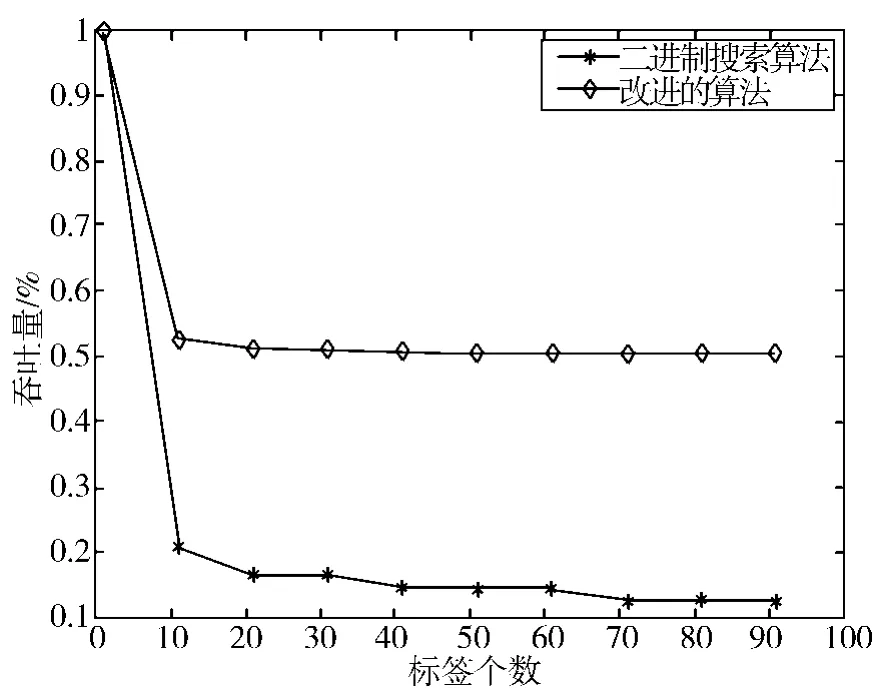
图7 改进的算法与二进制搜索算法的吞吐量的比较Fig.7 Comparison on the transaction capacity of improved algorithm and binary search algorithm
在实际的情况下,RFID系统一般都使用较长的ID码进行数据的传输,二进制搜索算法在每一次识别标签之后都要从头开始查询,耗费大量的算法执行时间。通过matlab仿真对比分析,改进的二进制算法不仅节省了数据传输的时间,减少了通讯次数,而且在传输的效率上也明显高于二进制搜索算法。
[1]康 东,石喜勤,李勇鹏.射频识别核心技术与典型应用开发案例[M].北京:人民邮政出版社,2008.
[2]李兴鹤,胡咏梅,王华莲,等.基于动态二进制的二叉树搜索结构 RFID 反碰撞算法[J].山东科学,2006,19(2):51-55.
[3] Wang T P.Enhanced binary search with cut-through operation for anti- Collision in RFID systems[J].IEEE Communications Letters,2006,10(4):236 -238.
[4]吴伟陵,牛 凯.移动通信原理[M].北京:电子工业出版社,2005.
[5]傅祖芸.信息论—基础理论与应用[M].北京:电子工业出版社,2001.
[6]王 雪,钱志鸿,胡正超,等.基于二叉树的RFID防碰撞算法的研究[J].通信学报,2010,31(6):48 -57.
[7] Shih D H,Sun P L,Yen D.Taxonomy and survey of RFID anticollision protocols[J].Computer Communications,2006,29(11):2150-2166.
[8]单承赣,余春梅,王聪聪.改进的二进制查询树的RFID标签防碰撞算法[J].合肥工业大学学报,2008,31(11),1801 -1804.
[9] Choi J H.Query tree-based reservation for efficient RFID tag anticollision[J].IEEE Communications Letters,2007,11(1):85 -87.
[10]李 瑾.无线射频识别(RFID)防碰撞算法的研究和仿真[D].北京:北京交通大学,2007.
