基于价值评估的数据迁移策略研究
2011-03-26江菲汤小春张晓赵晓南
江菲,汤小春,张晓,赵晓南
(西北工业大学计算机学院,陕西西安710129)
存储应用的发展和数据量的持续指数级增长以及对数据高速访问的需求,导致存储管理的难度和成本的不断攀升。同时,数据密集性应用要求长时间高性能的存储访问,而且对于性能、容量等的要求又会随着时间发生变化。其中性能是存储管理系统中的一项重要内容,提高存储性能可以有效地降低系统的总体拥有成本(TCO)。
信息生命周期管理ILM(Information Lifecycle Managemet)正是针对这样的目标而提出的一种以数据为中心的存储管理的思想[1]。ILM研究如何自动地针对数据所处的不同使用阶段对其采用不同的管理措施,存储于适当的介质中,使系统的综合性价比达到最优。HSM(Hierarchical Storage Management)是ILM的一种重要的实现方式。分级存储管理是指将不同类别的数据根据其存储系统中定义的需求,分配到不同类型的存储介质上,目的是提高存储效率。
另一方面由于存储设备性能各异,如何充分地利用存储网络中高性能的设备以提高数据访问性能,也成为一个重要的问题。马萨诸塞州立大学的研究者提出了一种在自管理存储系统中自动检测热点的策略,华中科大则是借鉴经济学中的商品价值规律,研究在multi-grid环境下基于文件级的数据价值模型,并提出了文件间相关性概念[2],然而,所有的这些研究都只是过分地关注迁移的速度问题,而忽略了方法的有效性和可行性。
在存储系统管理的过程中,对系统工作情况进行一定时间的监视和分析之后,采取一定的方式进行数据迁移是性能优化必须的步骤之一。通过数据自动迁移,可在保证存储系统在高性价比的条件下,获得更高的并行访问速率和可靠性。本文借鉴在ILM研究中的数据价值评价思想,综合分析了影响数据访问的因素和可能的优化方法,基于规则的、反馈的方法来完成数据迁移的优化,作为数据迁移策略的依据。
1 基于多指标的数据迁移模型
信息生命周期管理的核心是根据对数据价值的准确判定,分配与其价值相对应的性能合适的存储设备。本节讨论在存储管理系统中哪些因素是计算数据价值时必须考虑的,充分挖掘数据的静态特征和访问的动态特征[3],而这个价值的评价结果,将作为数据迁移对象的判断标准。
文件的静态因素:
1)文件的大小S:对于已达PB量级的存储系统来说,全部使用成本较高的高性能磁盘阵列是不可能的,因此对于混合磁盘构建的存储系统,小而且热的文件更适合存储在性能高且容量有限的高性能盘阵中[4]。设置文件大小的参数为Size,单位为MB。那么此因素影响价值为

2)文件的用户数量Ud:若一个文件被访问的用户数量越多,文件的价值就越高,因为如果一个文件被多个用户访问,那么它的改变和它的访问性能就会影响更多的用户。在文件系统中,客户和服务器都需要被标示,除了客户在申请使用文件系统时临时生成的客户标示符,使用过文件d的客户名数量便是C。那么此因素影响价值为

3)文件的内容DC:借鉴文献[5]的方法,内容以文本信息形式保存,通过分词算法可以将文件内容处理成一个词汇集合:WordSeg(C)→{ω1,ω2,…,ωk},词汇集合能够有效地表达数据的语义,每一种存储级别T也可以表示为一个词汇集合T={t1,t2,…,tp},计算文件的内容权重:

其中n和mi分别表示词汇ωi在存储系数和存储级别T出现的次数。
文件的动态因素:
1)文件的最近一次操作的时间Tlength:基于I/O访问的时间局部性特征,一般最新创建的或者最近使用过的文件被访问的概率较大,价值也就较高。而随着被访问过后未使用的时间越长,文件重要性越低,文件被重新访问的概率就越低,就需要逐渐迁移到较低性能的盘阵中,甚至迁移到近线或离线备份设备上。有的通过记录每一次访问或修改的时间集合{t1,t2,…,tn},但是在海量存储系统中,文件数量是巨大的,为每个文件记录时间集合是不现实的,所以根据上述分析,仅仅最近一次操作时间t0即可,如果当前时间为t,则距离上次操作时间长度Tlength=t-t0;那么此因素影响价值为:

2)文件的读写频率,读写操作是文件被使用的直接体现,读写频率高的文件必然具有更高的价值。文件的读写频率用R和W表示,那么此因素影响价值为:
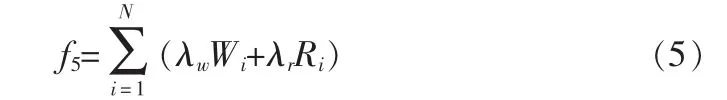
其中λw和λr分别是读补偿系数和写补偿系数,是用来表明存储设备在读写操作上的时间代价的比值。
3)文件之间的关联度FRdb,即某文件以某种规律或特性被读写的一定时间段内,若另外的一个或几个数据块上也呈现出某种显著的读写规律或特性,则认为这些数据块之间存在相关性。计算方法为在每个时间段中标记该期间读写操作的有无,进而在时间区间T上,每个文件可获得一个N维操作标记向量F,若在任意的第i(i=1,2,…,N)个时间段上有读/写操作就将该向量的第i维标记为1,否则标记为。通过对文件d,b各自对应的标记向量Fd,Fb按维做同或运算,当结果向量为全“1”时,则说明需要进一步求解相关系数FRdb,当数据块d在时间区间T上的任意第i(i=1,2,…,N)个时间段内有(或没有)读写操作时,在数据块上b也有(或也没有)读写操作时,则视为数据块d与b相关。其中Qd和Qb表示在N个时间区间T上的总I/O频率,di和qbi表示在第i(i=1,2,…,N)个时间段上有读/写频率,那么此因素影响价值为:

为每个数据属性设置权值wi,于是文件的价值评估为:

现设定初始阀值为Foptimun(0),从迁移任务队列中读取迁移任务请求,计数器k=1,假设当k=s时,迁移要求完成,将迁移队列的最后一个迁移数据的评估价值记录F1(s),则下一次的预测价值评估最佳阀值为Foptimun(1)=α Foptimun(0)+(1-α)F0(s),其中α为预测影响因子,它可以采用自适应的方法调整,思路如下:如果Foptimun(i)与Foptimun(i-1)的差的绝对值增大,α减小,反之增大;数据迁移过程如下伪代码所示:
对每一个数据i:
计算F(i),令δi=F(i)-F(0)
所有δi<0的数据放入集合S;
所有δi>0的磁盘放入集合T;
将集合S中的数据进行迁移;
while(是否满足迁移要求)
满足要求:反馈调整下一次阀值
return
不满足要求:continue
2 迁移算法性能及其分析
本节通过一个实例来验证和分析该价值评价模型的有效性。算法中的系统调节参数α影响着控制迁移模块的效率和稳定性。因此对于要求严格的系统,α的值可以设定大一些,如0.8左右,反之要求宽松的系统,α的值可以小一些,如0.6左右。wi代表了各个数据特性的权值,在实际使用中可以根据系统的平稳性和性能等要求来确定各个因素权值。
实验数据为某存储系统中的数据。每个数据都是预先由系统管理员设定了存储级别,因此这些预定的分级信息将作为实验结果的参照。实验的评价为迁移算法的准确率以及与传统基于频率数据迁移进行对比。迁移准确率表示迁移数据的命中率。实验首先对数据的文件元数据进行迁移计算,结果如表1所示。

表1 对数据进行迁移的结果Tab.1 Result of data migration
综上所述,由于考虑了更多的数据特性,引入了动态阈值,通过自适应的控制方法,使多次迁移后得到的阈值可以使系统更稳定,避免反复迁移等系统震荡现象。比起现行传统策略,这种迁移策略在不影响分级效果的情况下更加高效。
3 结论
数据迁移技术对于存储网络的负载均衡、系统扩展、灾难恢复等提供了一个新的解决方法,特别是对于性能优化有着深远的影响[6]。如何决定数据迁移的对象,保证迁移前后数据访问的透明性,减少数据迁移对在线业务的影响是这项技术所要研究的主要问题[7]。本文通过总结影响数据价值的若干因素,研究了评定数据价值的模型,并在此基础上提出了基于价值评估的数据迁移算法。应用信息反馈控制机制来实现动态调整迁移阀值,保证存储应用要求的性能。能够较好地提高系统性能,降低构建系统的成本。如何在实际应用中调整,使之能够适应复杂环境的需求,将是笔者下一步工作所要解决的主要问题。
[1]赵晓南,李战怀,曾雷杰,等.分级存储管理技术研究[J].计算机研究与发展,2010,7.
ZHAO Xiao-nan,LI Zhan-huai,ZENG Lei-jie,et al.Research on hierarchical storage management technology[J].Journal of Computer Research and Development,2010,7.
[2]ZHAO Xiao-nan,LI Zhan-huai,ZENG Lei-jie.A Hierarchical storage strategy based on block-level data valuation[C]//In the proceeding of the 4th Internatimal conference on Networked Computing and Advanced Information Management,2008:36-41.
[3]舒继武.分级存储与管理[J].中国教育网络,2007(7):70-72.
SHU Ji-wu.Hierarchical storage and management[J].China Education Network,2007(7):70-72.
[4]吕帅,刘光明,徐凯,等.海量信息分级存储数据迁移策略研究[J].计算机工程与科学,2009,31(A1):163-167.
LV Shuai,LIU Guang-ming,XU Kai,et al.Research on the data migration strategy of hierarchical mass storage system[J].Computer Engineering&Science,2009,31(A1):163-167.
[5]周敬利,聂雪军,秦磊华.一种基于内容感知的自动分级存储模型[J].计算机科学,2010(7):4-6.
ZHOU Jing-li,NIE Xue-jun,QIN Lei-hua.Auto-tiered storage model based on content aware[J].Computer Science,2010(7):4-6.
[6]冯泳,张延园.数据迁移在SAN中性能优化的研究和应用[J].计算机工程,2005(4):43-45.
FENG Yong,ZHANG Yan-yuan.Research and application of data migration in storage area network performance optimization[J].Computer Engineering,2005(4):43-45.
[7]王迪,舒继武,薛巍,等.基于块级别的SAN系统自适应分级存储[J].高技术通讯,2007,17(2):111-115.
WANG Di,SHU Ji-wu,XUE Wei,et al.SAN system autotiered storage based on block-level[J].High Technology Letters,2007,17(2):111-115.
