基于动态分组的两级检查点算法*
2011-03-16刘国良陈蜀宇徐光侠常光辉
刘国良 陈蜀宇 徐光侠 常光辉
(重庆大学计算机学院,重庆 400044)
检查点设置及回卷恢复技术是实现容错计算、提高系统可靠性的一种有效途径[1-3].其基本思想是:当系统在正常运行时,每隔一段时间把系统状态保存到可靠存储介质(称作检查点)上;当系统出现故障时,系统回卷到检查点状态,把计算损失减少到检查点时刻至故障发生时所做的计算,避免了程序从头开始执行[1,4-5].
目前,检查点算法主要有两种:协调检查点和独立检查点算法[6-9].在独立检查点算法中,进程具有极大的自主性来决定记录检查点的时机,因此在正常计算阶段所需开销较小.然而当故障发生时,容易导致多米诺效应[10-11];进程需要记录多个检查点,导致不必要的空间开销.协调检查点算法要求每次获得的检查点都是全局一致检查点,每个进程只需记录一个检查点,不会发生多米诺效应,但在正常计算阶段仍需要较高的同步开销[12-14].
就包含多个节点的应用而言,节点间交换信息的频率是不一样的,甚至相差很大[4-5],因此需要一种机制来适应这种要求.
文献[1]中采用混合检查点的方式:簇内采用协调检查点算法、簇间采用通信诱导算法,其优点是簇内检查点的获取可以并行进行,缺点是发生故障后,簇间容易导致信息风暴.文献[2-3]中通过发送节点来保证获得一致检查点,但未考虑节点间的通信频率、通信延迟、通信带宽等动态指标,在回卷阶段产生较大开销.
针对分布式应用的特点,文中提出了一种基于动态分组的两级检查点算法,根据节点间通信的频率、通信延迟、通信带宽及分组中节点数等指标来实现动态分组,实现分组的高内聚低耦合.由于组内通信延迟小、节点数不多,因此文中采用协调检查点算法.组间通常是由高延迟、低带宽的网络相互连接,并且组间的通信频率较低,文中提出的系统级检查点算法充分考虑了这个特点;每个分组是否获得检查点,与其它分组无关,各个分组可以独立地、以并行方式获得系统级检查点;通过发送分组来确保分组间不会产生孤儿消息,每次获得的系统级检查点均是全局一致检查点,避免了多米诺效应的发生.
1 系统模型
1.1 系统体系结构
文中提出的检查点算法的应用对象是一些开放的分布式系统,采用与文献[1]中相似的系统体系结构,如图1所示.
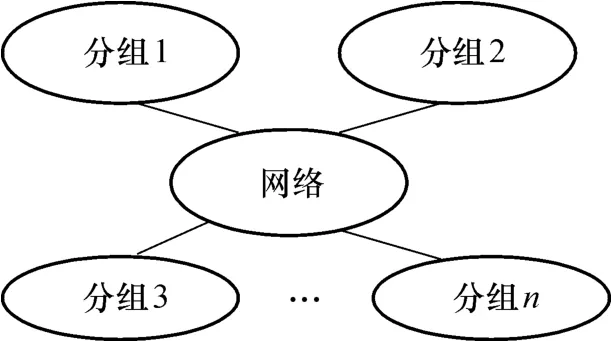
图1 系统体系结构Fig.1 System architecture
系统中多个分组通过网络相互连接,各个分组是动态划分的,划分的依据是节点间的信息交互频率、通信延迟时间等指标(具体根据应用需要确定).每个分组内包含若干个节点,且至少有一个节点.1.
2 算法体系结构
将两级检查点算法应用于系统中,其体系结构如图2所示.
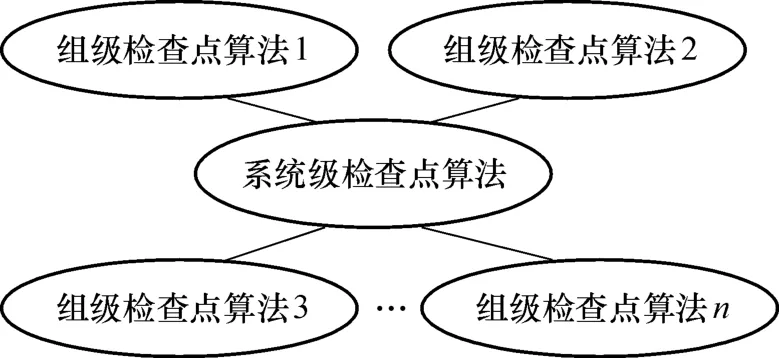
图2 算法体系结构Fig.2 Algorithm architecture
由图 2可知,多个组级检查点算法连接到一个系统级检查点算法上.分组内的节点是通过低延迟、高带宽的网络连接在一起,并且其数量一般来说也不是很多,因此,适合采用协调检查点算法.
组间一般是通过高延迟、低带宽的网络连接在一起,不适合采用协调检查点算法.另外,对于大规模分布式应用而言,其分组数数以千计,并且各个分组中节点的负载、操作系统的调度策略等均可能对检查点同步产生不可避免的影响,为此文中提出了系统级检查点算法.
2 检查点算法
2.1 动态分组策略
分组策略的选择需要综合考虑节点间消息交互的频率、网络带宽、延迟及节点数等指标,使信息交互和检查点算法的时空开销间达到效能最大化.假设这几个指标的阈值分别为 θf、θb、θd和θn.若两个节点间的通信频率大于θf、通信带宽大于θb、延迟小于θd且分组G中节点数小于θn,则将这两个节点划分到一个分组G中.若分组 G中节点数大于 θn,则这两个节点归为一个新的分组.
当然,具体分组策略是和应用本身相关的,这里只是举了一个例子,节点间消息交互的频率、网络带宽、延迟及节点数等指标之间的组合策略有很多种,需要根据实际需要进行决策.
2.2 组级检查点算法
每个分组内该采用哪种检查点算法,与分组策略有关.由于分组中的节点是通过高性能网络(低延迟、高带宽)连接,并且节点较少,因此采用协调检查点算法能够获得很好的效果.
假设分组中节点数为 m,采用文献[15]中的协调检查点算法,则需要 2m个控制消息,时间复杂度为O(m).
2.3 系统级检查点算法
当多个分组中的进程参与一个分布式应用时,需要调用系统级检查点算法.定义一个分布式并行应用程序为P,P={G1,G2,…,Gn},n是该并行应用程序中包含的分组数.把启动算法的分组称为启动分组,其它分组称为应用分组.启动分组中的某个进程按照一定的规则启动算法.任何分组都可能成为启动分组,这种设计更符合分布式应用特征.
为了叙述的一致性,文中给出如下符号定义:
F为发送消息标志,表示在一个检查点后是否已发送了消息,值为 1表示相应分组已将应用消息发送到其它分组,值为 0表示未发送消息;Fi表示分组Gi(i=1,2,…,n)的发送消息标志.
CN为检查点序号,每执行一次系统级检查点算法,其值加1;CNi表示分组Gi(i=1,2,…,n)的检查点序号.
St为一致分组状态,是分组级的全局一致状态,即分组中各个进程状态的集合;Sti表示分组Gi(i=1,2,…,n)的一致分组状态.
SN为发送消息序号,用来唯一标识分组所发送的消息,每发送一条消息,其值加1;SNi表示分组Gi(i=1,2,…,n)发送的消息序号.
Ci,x为分组Gi(i=1,2,…,n)的第x个检查点.
MC为控制消息,启动系统级检查点算法时使用.
M表示分组间发送的应用消息;Mi表示分组Gi发送的应用消息.
算法中用于协调分组行为的各种消息称为控制消息,分组之间为实现计算目标而进行通信的消息称为应用消息.
2.3.1 相关定理
定理1 对给定的任意分组Gi(i=1,2,…,n),在任意时刻T′,如果发送消息标志满足Fi=0,则在T′时刻,Gi已发送的所有消息都不是孤儿消息.
证明 根据文中算法,假设Ci,x为分组Gi的任意检查点,则 T′时刻要么在获得检查点Ci,x-1和 Ci,x时刻之间,要么与获得检查点 Ci,x时刻重叠,要么在获得检查点Ci,x和 Ci,x+1时刻之间,如图3所示.

图3 T′时刻的位置示意图Fig.3 Schematic diagram of position of time T′
(1)假设T′时刻位于获得检查点Ci,x-1和Ci,x时刻之间,若发送标志 Fi=0,则根据算法可知,在获得检查点Ci,x-1时刻到 T′时刻这段时间内,分组Gi没有发送任何消息,因而不存在孤儿消息.
(2)假设T′时刻与获得检查点Ci,x时刻重叠,若发送标志Fi=0,则根据算法可知,在 T′时刻首先获得检查点Ci,x,再将标志Fi置0.即记录了分组Gi在获得检查点 Ci,x-1和 Ci,x期间发送的所有消息,因而不存在孤儿消息.
(3)假设T′时刻位于获得检查点Ci,x和Ci,x+1时刻之间,若发送标志 Fi=0,则根据算法可知,在获得检查点Ci,x时刻到T′时刻这段时间内,分组Gi没有发送任何消息,因而不存在孤儿消息.
综上所述,定理得证.
定理2 假如分组Gk(k=1,2,……,n)向分组Gi发送应用消息〈Mk,CNk,SNk〉,且分组Gk的检查点序号CNk与Gi的检查点序号CNi满足CNk>CNi,则Gk发送的应用消息Mk不会变成孤儿消息.
证明 当分组Gi收到应用消息〈Mk,CNk,SNk〉后,比较检查点序号CNk与CNi,若CNk>CNi,表明算法的第x次执行已经开始了,Ci会很快收到启动分组的控制消息〈MC,CNk〉.分组Gi并不等待控制消息〈MC,CNk〉,而是根据自身的发送标志Fi来判断是否获得检查点,然后处理收到的应用消息 Mk,意味着接收的应用消息 Mk没有被接收分组 Gi记录,根据孤儿消息定义知道,应用消息 Mk不会变成孤儿消息.证毕.
定理3 假如分组Gk向分组Gi发送应用消息〈Mk,CNk,SNk〉,且分组Gk的检查点序号CNk与分组Gi的检查点序号CNi满足CNk=CNi=x,则分组Gk发送的应用消息Mk不会变成孤儿消息.
证明略.
定理4 假如分组Gk向分组Gi发送应用消息〈Mk,CNk,SNk〉,且分组Gk的检查点序号CNk与分组Gi的检查点序号CNi满足CNk<CNi,则分组Gk发送的应用消息Mk不会变成孤儿消息.
证明略.
2.3.2 算法描述
系统级检查点算法是一个单阶段非阻塞算法,即算法允许分组直接获得永久检查点,不需要获得临时检查点,因而相比传统的两阶段提交算法,大大提高了执行速度.另外,系统级检查点算法能够保证每次获得的检查点都是系统级全局一致检查点,因而大大减少了获得的检查点数量.系统级检查点算法的描述如下:


证明 对启动分组Gk(k=1,2,…,n)而言有2种情况:如果其发送消息标志Fk=1,即满足if条件,那么该分组首先获得检查点,然后把标志 Fk置为 0,因此,只要检查点获得成功,标志 Fk必为 0,根据定理1可知,分组Gk已发送的所有消息都不是孤儿消息.如果不满足if条件,即进入else段代码,此时,发送标志Fk必为0,根据定理 1,分组 Gk已发送的所有消息都不是孤儿消息.
对应用分组Gi(i=1,2,…,n)而言有3种情况.
(1)假如应用分组Gi(i=1,2,…,n)收到启动分组Gk(k=1,2,…,n)发送的控制消息〈MC,CNk〉,则满足第一个if条件,有:①假如其发送消息标志Fi=1,即满足 if条件,那么该分组首先获得检查点,然后把标志 Fi置为 0,因此,只要检查点获得成功,标志Fi必为 0,根据定理 1,分组Gi已发送的所有消息都不是孤儿消息.②假如不满足if条件,即进入else段代码,此时,发送标志 Fi必为0,根据定理1,分组Gi已发送的所有消息都不是孤儿消息.
(2)假如应用分组Gi(i=1,2,…,n)没有收到启动分组Gk(k=1,2,…,n)发送的控制消息〈MC, CNk〉,但收到了其它分组Gj(j=1,2,…,n)(包括分组Gk)发送的应用消息〈Mj,CNj,SNj〉,即满足else if条件,有两种情况:①如果CNi<CNj,则进入if语句,根据定理 2,进程 Pj发送的任何应用消息〈Mj, CNj,SNj〉均不会变成孤儿消息,即应用分组Gi在接收控制消息〈MC,CNk〉之前接收的任何分组的任意应用消息〈Mj,CNj,SNj〉均不会变成孤儿消息.②如果CNi≥CNj,则进入else语句,必满足定理3、定理4,分组Gj发送的任何应用消息〈Mj,CNj,SNj〉均不会变成孤儿消息.
(3)如果既不满足情况(1)也不满足情况(2),则程序进入最后一个else语句,即分组Gi正常执行,不会获得检查点,当然也没有孤儿消息.
综上所述,对任意的分组Gi(i=1,2,…,n),在检查点处,均没有孤儿消息存在,所以,通过该算法获得的检查点集一定是系统级全局一致检查点.证毕.
2.3.3 启动周期
算法启动周期T的选择需要综合考虑,如果太短,就会导致算法频繁启动,增加额外负载;如果太长,系统发生故障后,会导致丢失的计算量较大.另外,启动周期的选择还需要有利于回卷恢复算法的实现.设系统中任意两个分组Gi和Gj间传送消息需要的时间为ti,j(i≠j),两个分组间传送消息需要的最大时间为tmax={ti,j,i≠j},则文中算法启动周期T取略大于tmax.选择该启动周期是为了尽量减少记录中途消息的数量(处理中途消息的常用方法是消息日志方法).由于T>tmax,所以一个分组Gi只需要在它的最近检查点 Ci,x保存检查点间隔(Ci,x-1,Ci,x)内所发送的消息,如图 4所示.图 4中,考虑两个分组Gi和Gj,由于T>tmax,对分组Gi来说,在检查点间隔(Ci,x-2,Ci,x-1)内发送的任意消息M都会在分组Gj的最近检查点Cj,x获得之前到达分组Gj.现假设分组Gi发生故障,两个分组在恢复算法的作用下回卷到它们的最近检查点{Ci,x,Cj,x}并重新计算,由于消息M在分组Gj的检查点Cj,x之前已经被接收,即 M不会变成中途消息,所以不需要进行重传.因此在发送分组Gi的最近检查点Ci,x处就不需要保存日志信息.相反,图 4中的消息 M1及M2均可能变成中途消息,因此需要在发送分组 Gi的最近检查点Ci,x处保存日志信息,在恢复时进行重传,防止中途消息丢失.

图4 中途消息Fig.4 In-transitmessage
2.3.4 时间复杂度
在以往的同步算法中,通常利用“消息驱赶”的方式获得全局一致状态.这种方式实现简单,不足之处在于数量级为O(n2)的清空消息CLS_MSG将给系统带来很大的通信量.当n较大时,这种同步控制消息量以平方的量级增长,在时间和空间上都是不能接受的.
在本文算法中,只有启动分组通过控制消息MC与应用分组进行交互,如果分组数为 n,则只需要n-1个控制消息,远低于已有算法;其它应用分组只是根据自己的发送标识F判断是否获得检查点,不需要其它分组的任何额外消息.因此文中算法的时间复杂度为O(n),远低于传统算法的时间复杂度O(n2),有效地提高了系统的效率和扩展性.
3 性能评估
为了评估文中算法的性能,采用文中算法与文献[1,15-16]中算法进行比较,主要考察算法是否阻塞及同步控制消息的费用.
设csend为从一个进程发送一条消息到另一个进程的费用,cbroad为从一个进程广播一条消息到所有进程的费用,Nmin为需要获得检查点的进程数,r为系统中的进程数,q为分组数,y为分组中节点数.几种算法的性能比较结果如表1所示.

表1 几种算法的性能比较Table 1 Comparison of performance of several algorithms
从表 1中可知,文献[1,15]中算法是阻塞算法,因此只有当进程获得了永久检查点后才能进行正常计算.在控制消息费用方面,文献[16]中采用的是两阶段提交方式,首先一个进程发送2个控制消息来获得临时检查点,系统负载为2Nmincsend,在第二阶段临时检查点转变为永久检查点,消息负载为min(Nmincsend,cbroad),因此总费用为2Nmincsend+ min(Nmincsend,cbroad).文中算法是组级算法加系统级算法,组级算法采用文献[15]中算法,消息费用为(y/r)(2cbroad+rcsend);系统级采用文中提出的单阶段算法,直接获得永久检查点,只需要广播一条请求消息,费用为(q/r)cbroad,因此总费用为
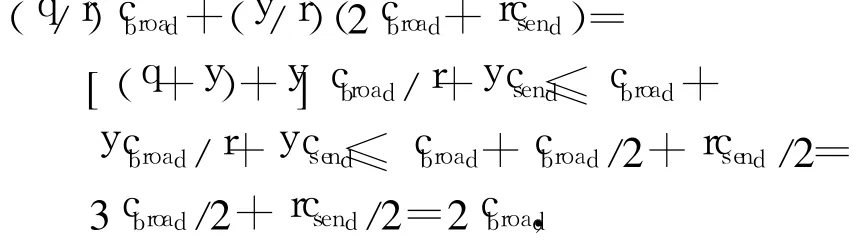
其中cbroad=rcsend.系统至少包含两个分组,一般情况下q+y≤r,算法在最坏情况下,控制消息费用为2cbroad.
当进程数较多时,算法是否适用主要归结为进程数与控制消息数的关系,即进程数较多时,算法的负载应该比较低.文献[1]和文献[15]中算法具有相同的负载,假设平均获得的检查点进程数为总进程数的 80%,则文中算法在最坏情况下的负载为2cbroad.采用文中算法与文献[1,16]中算法进行比较,进程数与控制消息数的关系如图5所示.
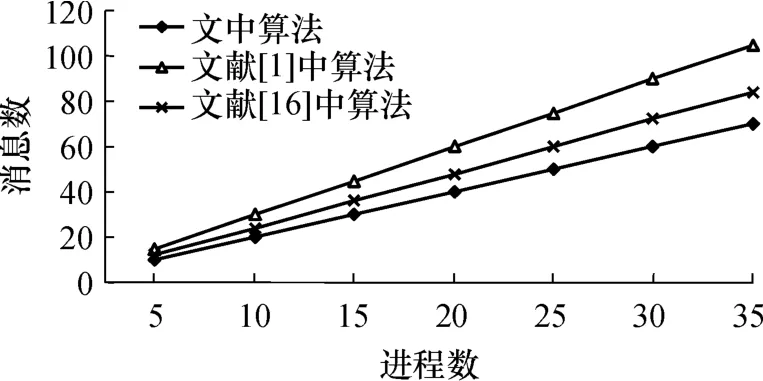
图5 几种算法的进程数与控制消息数的关系Fig.5 Process numbers ofseveral algorithms versus numbers of controlmessages
从图 5中可以看出,随着进程数的增加,3种算法需要的协调控制消息均是按线性规律增长.设系统中进程数为 r,则文献[1]中算法需要 3r条控制消息,文献[16]中算法大约需要 2.4r条控制消息,文中检查点算法所需控制消息少于文献[1,16]中算法,在最坏情况下,仅需2r条控制消息.
为了验证文中算法的有效性,采用多个节点进行测试,每个节点CPU采用Intel赛扬450、CPU频率2.2GHz、二级缓存512kB、主板芯片组IntelG41+ ICH7、内存2GB.所有节点经由1Mb/s网络连接(网卡采用Intel8139,交换机采用H3CS5120,在端口作速率匹配),操作系统为Windows XP.在不包含组级协调检查点算法的条件下,系统级单阶段检查点算法的执行时间与进程数的关系如图6所示.

图6 系统级检查点算法的执行时间与进程数的关系Fig.6 Execution time of system-level checkpoint algorithm versus number of processes
从图 6中可以看出,系统级检查点算法的执行时间开销基本上为毫秒级,与并行程序的运行时间相比是微不足道的.
设每个分组中有 10个进程,每个节点对应一个进程,组内进程间带宽为10Mb/s(节点经由100Mb/s快速以太网连接,网卡采用Intel 8139,交换机采用H3CS5120,在端口作速率匹配),组间带宽为1Mb/s (网卡采用Intel 8139,交换机采用H 3CS5120,在端口作速率匹配),操作系统为Windows XP,组级采用文献[15]中协调检查点算法,系统级采用单阶段检查点算法,两级检查点算法的执行时间与进程数的关系如图7所示.
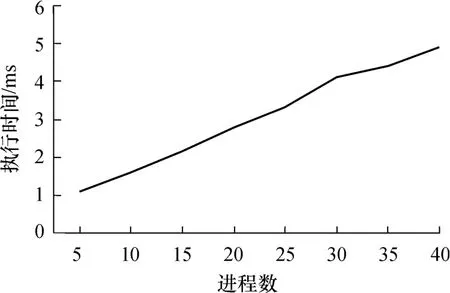
图7 两级检查点算法的执行时间与进程数的关系Fig.7 Execution time of two-level checkpoint algorithm versus number of processes
从图 7中可以看出,两级检查点算法的执行时间开销基本上为毫秒级,随着并行进程规模的扩大,检查点的时间开销基本上呈线性增长,能够适应大规模的分布式并行应用.
4 结语
文中提出了一种基于动态分组的两级检查点算法:组级采用协调检查点算法,系统级采用单阶段检查点算法.该算法能动态适应应用自身的要求,提高了资源的整体效能,并通过发送分组来确保分组间不会产生孤儿消息,实现了由传统的两阶段提交算法到单阶段算法的转变,大大提高算法的执行速度,最后通过实验验证了文中算法的有效性,该算法能够适应大规模的分布式并行应用.今后将在更大规模系统环境下对文中算法进行实验,验证算法的有效性,同时考虑将检查点算法与操作系统的调度算法结合起来,以提高系统的容错能力.
[1] Monnet S,Morin C,Badrinath R.Hybrid checkpointing for parallel applications in cluster federations[C]∥Proceedings of IEEE International Symposium on Cluster Computing and the Grid.Washington D C:IEEE,2004:773-782.
[2] Gupta B,Rahim i S,Ahmad R.A new roll-forward checkpointing/recovery mechanism for cluster federation[J]. International Journal of Computer Science and Network Security,2006,6(11):292-298.
[3] Gupta B,Rahimi Shahram,Yang Yixin.A novel roll-back mechanism for performance enhancement of asynchronous checkpointing and recovery[J].Informatica:Slovenia, 2007,31(1):1-13.
[4] Elnozahy EN,Alvisi Lorenzo,Wang Yi-min,et al.A survey of rollback-recovery protocols in message-passing systems[J].ACM Computing Surveys,2002,34(3):375-408.
[5] Bowen N S,Pradhan D K.Processor-and memory-based checkpoint and rollback recovery[J].Computer,1993,26 (2):22-31.
[6] Bosilca George,Delmas Remi,Dongarra Jack,et al.Algorithm-based fault tolerance app lied to high performance computing[J].Journalof Parallel Distributed Computer, 2009,69(4):410-416.
[7] Sm ith Jim,Watson Paul.Applying low-overhead rollbackrecovery to wide area distributed query processing[R]. Newcastle:School of Computing Science,University of Newcastle upon Tyne,2004.
[8] Gupta Sunil K,Chauhan R K,Kumar Parveen.Backward error recovery protocols in distributed mobile systems:a survey[J].Journal of Theoretical and Applied In formation Technology,2008,30(4):225-240.
[9] Rusu Claudia,Grecu Cristian,Anghel Lorena.Blocking and non-b locking checkpointing and rollback recovery for networks-on-chip[C]∥Proceedings of the 2nd Workshop on Dependable and Secure Nanocomputing.Anchorage:IEEE, 2008:1-6.
[10] Manivannan D.Checkpointing and rollback recovery in distributed systems:existing solutions,open issues and p roposed solutions[C]∥Proceedings of the 12th WSEAS International Con ference on Systems.Herak lion: ACM,2008:22-24.
[11] de Camargo Raphael Y,Goldchleger Andrei,Kon Fabio, et al.Checkpointing-based rollback recovery for parallel app lications on the InteGrade grid iddleware[C]∥Proceedings of the 2nd Workshop on Middleware for Grid Computing.Toronto:ACM,2004:35-40.
[12] Janakiraman G,Tamir Y.Coordinated checkpointing-rollback error recovery for distributed shared memorymu lticomputers[C]∥Proceedings of the 13th Symposium on Reliable Distributed Systems.Dana Point:IEEE,1994: 42-51.
[13] Gupta Bidyut,RahimiShahram,Liu Ziping.Design ofhigh performance distributed snapshot recovery algorithms for ring networks[J].Journalof Computing and In formation Technology,2008,16(1):23-28.
[14] Chandy K Mani,Lamport Leslie.Distributed snapshots: determ ining global states of distributed systems[J]. ACM Transactions on Computer Systems,1985,3(1): 63-75.
[15] Wang D S,Shao M L.A cooperative checkpointing algorithm with message complexity O(n)[J].Journal of Software,2003,14(1):43-48.
[16] Cao G,Singhal M.Mutable checkpoints:a new checkpointing approach for mobile computing systems[J]. IEEE Transactions on Parallel and Distributed Systems, 2001,12(2):157-172.