Prefix Subsection Matching Binary Algorithm in Passive RFID System
2011-03-09WANGXinfeng王新锋YUJingyi俞静一ZHANGShaojun张绍军ZHOUYing周颖
WANG Xin-feng(王新锋),YU Jing-yi(俞静一),ZHANG Shao-jun(张绍军),ZHOU Ying(周颖)
(Unit No.63880,Luoyang 471003,Henan,China)
Introduction
Radio frequency identification(RFID)is a rising auto-identification technology in military asset visibility.Binary anti-collision algorithms are the main part in RFID technique which is accepted in the standards of ISO 14443 Type A,ISO 18000-6 Type B,and EPC C 1 G2.Among binary anti-collision algorithms,QT algorithm,proposed by MIT AUTO-ID lab[1],is a famous algorithm because tags supporting the algorithm only need to have logic compare function without occupying any buffer memory.QT algorithm can be applied in cheapest RFID tag and has broad latent application especially in military asset visibility.
However,the deficiency of QT algorithm is that RFID reader always searches the whole space of tag ID,that leads to lower reader searching speed,augments tag average response times and shortens tag lifespan.To improve QT algorithm,Ref.[2]utilizes history read IDs of a given reader to lessen searching space and speed up searching speed of QT algorithm.It can gain improvement when the variety of tag ID prefixes is few.But when variety of tag ID prefixes is frequency,the improvement of the algorithm is poor.Ref.[3]suggestes that the tag ID could be partitioned to several subsections.At the beginning of tag searching,the proposed algorithm tries several known tag ID prefixes,and went on using traditional QT algorithm.But that needs all tags read by a given reader should have a same prefix,which is too rigorous to use the algorithm for a practice application.
The three mentioned algorithms search tag ID by a bit-by-bit way.Taking EPC-96-I[4]as an example,tag ID is partitioned to four subsections(see Fig.1),and the three algorithms have to search the four subsections bit-by-bit.In fact,the numbers of anterior three subsections(EPC version,manufacturer ID and object class)are limited for any giver RFID reader.In this paper we propose a new algorithm.It utilizes the limited subsections to buildup a prefix database,and a given reader can depress searching space by the database to boost searching speed.The new algorithm is named as prefixes subsection matching binary(PSMB)anticollision algorithm.The PSMB algorithm can be described as follows.When a given reader is searching the anterior three subsections,the searched out bits in a special subsection will be compared with corresponding prefixes in prefix database.If the number of matching prefixes is less than a given threshold,the reader will attempt to take the matching prefixes as corresponding subsection of tag ID and continue to identify next subsection.When all the matching prefixes have been attempted,the reader will return to state before attempt phase to ensure that any tag has not been left out.
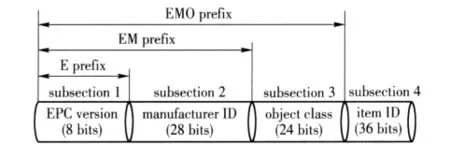
Fig.1 ID subsections of 96 bits EPC tag
1 PSMB Algorithm
1.1 Prefix Database
1.1.1 Three Kinds of Prefix in Prefix Database
Taken EPC-96-I tag ID as an example,the three kinds of prefix are depicted in Fig.1.
1)E prefix:its length is 8 bits and its maximum number is m1;2)EM prefix:it is 36 bits and maximum number is m2;3)EMO prefix:it is 60 bits and maximum number is m3.
1.1.2 Prefix Matching Operation
When a given reader is searching tag ID,a binary string which can be denoted by q is included in reader request command.On receiving the command,a tag compares its anterior L(q)with q.If L(q)< q,the tag will send its ID to the reader as response,otherwise the tag will keep silent.Here L(q)denotes the function to calculate length of binary string q.
To shorten unknown bits number of tag ID and depress searching space,the reader does the following steps to match prefix database after receiving tag IDs.
Firstly,according to the length of binary string q in reader's command,the reader selects different kinds of prefix.If 0<L(q)<8,that means the reader is searching EPC version subsection,and E prefix will be selected;if 8<L(q)<36,that means the reader is searching manufacturer ID subsection,and EM prefix will be selected;if 36<L(q)<60,that means the reader is searching object class subsection,and EMO prefix will be selected.Secondly,the reader sums up number of matched prefixes.
For example,a given reader is searching with q=1 001 and collision occurred.Because 0<L(q)<8,so the reader matches all E prefix in prefix database with q,and all E prefix in prefix database can be listed in Tab.1.

Tab.1 E prefix of the example
It can be seen from Tab.1 that the matched E prefixes are PE1and PE4,so the matched prefixes number is two,that is v=2.If the given threshold vmaxis four,and v< vmax,then PE1,PE4,q‖0 and q‖1 will be put in the front of searching queue Q;Otherwise if v>vmax,then only q‖0 and q‖1 will be put in Q.Here“‖”denotes the operation of combining two binary strings.The intent of putting q‖0 and q‖1 into Q is to ensure that,after attempt of matched prefixes,the reader can return to the state before attempt phase and any tag could not be left out.
1.1.3 Update of Prefix Database
Whenever a tag ID is searched out,its three prefixes are used to maintain prefix database employing LRU(least recently used)algorithm[5].Any prefix has an inquired field to recorder the timeslice t from latest accessed time to now.When a given reader identified a tag ID qtag,the reader does the following three steps to update the prefix database.
1)Update of E prefix.If f1,8(qtag)equals to one of E prefix Ei,i.e.f1,8(qtag)=PEi,(i∈[1,m1]),then timeslice of the prefix Eiwill be set to zero(i.e.tEi=0).Otherwise if f1,8(qtag)is not equal to any E prefix and number of E prefix is maximum m1,then the prefix which has maximum timeslice will be replaced by f1,8(qtag)and set tEi=0;if number of E prefix is not m1,then f1,8(qtag)will be inserted to prefix database and its timeslice will be set to zero.Here fm,n(q)is a function to select a binary string from mth bit to nth bit from q.
2)Update of EM prefix.If f1,36(qtag)equals to one of EM prefix EMi,then let tEMi=0,where i∈[1,m2].Otherwise if f1,36(qtag)is not equal to any EM prefix and number of EM prefix is maximum m2,then the prefix which has maximum timeslice will be replaced by f1,36(qtag)and timeslice of the prefix will be set to zero;if number of EM prefix is not m2,then f1,36(qtag)will be inserted to prefix database and its timeslice will be set to zero.
3)Update of EMO prefix.If f1,60(qtag)=PEMOi,then let tEMOi=0,where i∈[1,m3].Otherwise if number of EMO prefix is m3,then the prefix which has maximum timeslice will be replaced by f1,60(qtag)and timeslice of the prefix f1,60(qtag)will be set to zero;if number of EMO prefix is not m3,then f1,60(qtag)will be inserted to prefix database and its timeslice will be set to zero.
In the example in section 1.1.2,if a given reader identified a tag ID qtagusing PE1and f1,8(qtag)=10011100,then tE1would be set to zero.Otherwise if f1,8(qtag)=10011110,then PE5will be replaced by f1,8(qtag)because tE5is maximum in all E prefixes.Update of EM and EMO prefix is similar to E prefix.
1.2 Process of PSMB Algorithm
Let Ω = ∪ki=0{0,1}ibe the set of binary strings with length k.The state of a given reader can be expressed by Q and prefix database,where Q is a sequence of strings in Ω.At the beginning of a searching phase,let Q= < ε > ,where ε is the empty string.All un-dormancy tags respond with their tag ID when reader searches with ε string.Suppose at one moment Q=<q1,q2,……,ql>,qi∈Ω and q1< q2< … < ql,then the PSMB algorithm searches tags as following steps.The search flow-chart is shown in Fig.2.
Step 1Select the first binary string q1from Q,and let q=q1,then the reader searches with parameter q.On receiving the query command,every active tag compares q with f1,L(q)(ID),if f1,L(q)(ID)=q,then the tag will send its ID to the reader as response.
Step 2According to the number of tag response,the reader does one of the following operation.
More than one tags reply,which means that a collision occurres and the reader can not get any useful knowledge from the responses.If the binary string q is an attempt prefix,then let Q= <q‖0,q‖1,q2,…,ql>and the reader will go back to step 1.Otherwise the reader does the prefixes matching operation and probably finds matched prefixes w1,…,wv,where w1< w2… <wv.If v≤λ,then the reader will let Q= <w1,w2,…,wv,q‖0,q‖1,q2,…,ql> and go back to step 1,if v> λ,the reader will let Q= < q‖0,q‖1,q2,…,ql> and go back to step 1.Here λ is the given threshold used to decide whether matched prefixes w1,…,wvshould be put into Q.
One tag responds,which means that the reader identifies the replied tag ID and sets the tag to dormancy state.Then the reader deletes the binary string corresponding to q from Q and updates prefix database according to the identified tag ID.If Q= <ε>,let δ=0 and goes to step 3,otherwise the reader goes back to step 1.
None tag responds,which means that no tag replies to the query.The reader deletes the binary string corresponding to q from Q,and if Q= <ε >,let δ=0 and goes to step 3,otherwise the reader goes back to step 1.
Step 3The reader sets δ=0 and queries with q=ε.If there exists response,the reader will go back to step 2.Otherwise,the reader lets δ= δ+1 and queries with q= ε until δ≥μ.
1.3 Reliability of PSMB Algorithm
Reliability is an important factor for an anti-collision algorithm in RFID system.Failure to identify any tag will lead to cause economic loss and depress user's belief in RFID technology.To raise reliability of PSM algorithm,a reader queries with q= ε at least μ times in the end of a searching phase.If we assume that probability of failed response of tag is p and the tags'failures are statistically independent events,then the probability of a tag failed to reply is less than Pμ.
In a searching phase,if there are n tags to be identified,then the probability of m tags failed to reply synchronously is Pn,mand

Then reliability can be controlled by adjustment of parameter μ.
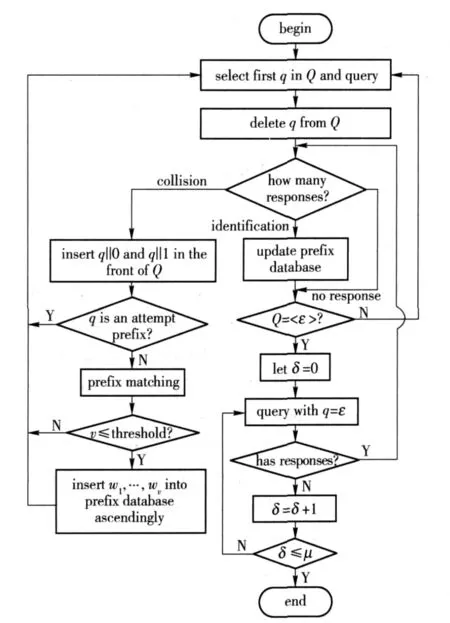
Fig.2 Process of PSMB algorithm
2 Simulations and Result Analysis
2.1 Simulation Assumption
Tag ID is 96 bits in EPC-96-I form as shown in Fig.1.We suppose that tags for a given reader have 5 EPC version,500 manufacturer ID and 5 000 object class,that is m1=5,m2=500,m3=5 000.This assumption is similar to actual environment.For example,a reader installed in entry of a depository,it is enough to have 5 EPC versions,500 tag manufacturer IDs and 5 000 goods class.
Prefix matching threshold λ is set to 4,and tag number changes from 2 to 100.
Additionally,because number of tags with a same EMO prefix affects performance of tab supporting QT and PSM algorithms,we take the tag numbers of 2,4,8 and 16,respectively.
2.2 Result Analysis
Simulation results are analyzed in three aspects:average searching times,tag average response times and system throughput rate.
Average searching time,which is used to scale reader's searching delay,is reader's total searching time divided by tag number.Tag average response time,which affects tag power and lifespan greatly,is tag's total response time divided by tag number.System throughput rate is ratio of successful searching times to total searching times.
2.2.1 Average Searching Times
Performances of QT and PSMB algorithms are shown in Fig.3.

Fig.3 Average searching times
As shown in Fig.3,when number of tags with a same EMO prefix is 2,average searching time of QT algorithm is larger than 30,and PSMB is about 10.When the number is 4,average searching time of QT algorithm is about 30,and PSMB is lower than 10 in most times.When the number is 8,average searching time of QT algorithm is about 20 and sometime is more than 40,and PSMB is between 5 and 8.When the number is 16,average searching time of QT algorithm is from 30 to 10,and PSMB is from 10 to 4.
2.2.2 Tag Average Response Times
Performances of QT and PSMB algorithms are shown in Fig.4.
As shown in Fig.4,in order to be searched by reader,the tag supporting QT algorithm must respond about 60 times.In these responses,only one response is effectively received,and most power and lifespan is wasted.But PSMB algorithm can only respond about 13 times when number of tags with a same EMO prefix is 2,and the response time is between 14 and 17 when the numbers is 4,8 and 16.

Fig.4 Tag average response times
2.2.3 System Throughout Rate
As shown in Fig.5,when number of tags with a same EMO prefix is 2,system throughput rate of QT algorithm is only about 3%.System throughput rate rises with the increase of tab number,when the number is 16 and the percent is 8%.System throughput rate of PSMB algorithm is much more higher than QT algorithm,which is 10%when the number is 2 and 20%when the number is 16.

Fig.5 System throughput rate
In Fig.5(c)and(d),system throughput rate rises like a staircase.The reason is that when the increment of tag number reaches to 8 in Fig.5(c)or 16 in(d),a new tag type is added and the two algorithms have to search the new space added by the new tag type,so successful searching times fall and the percentage falls too.While tag number rises sequentially,successful searching time rises and then percentage of successful searching times rise.In fact,the staircases still can be seen from Fig.5(a)and(b),but they are unobvious.
3 Conclusions
PSMB anti-collision algorithm is proposed.Simulation results show that identification delay of PSMB algorithm is about 1/3 of QT algorithm,tag average response time is about 1/4 of QT algorithm,and system throughput rate is treble the rate of QT algorithm.More simulation results show that the advantage of PSMB algorithm falls slightly with the increase of prefix type number,but the benefit is still obvious.
Furthermore,because the operations of prefixes matching and updating prefix database are performed by RFID reader,PSMB algorithm can be actualized just by updating reader's software.Also,the tags complying with PSMB algorithm can be cheapest because they only need logical comparison and one bit of state register.
[1]Law C,Lee K,Siu K Y.Efficient memory less protocol for tag identification[C]∥ Proceedings of the 4th International Workshop on Discrete Algorithms and Methods for Mobile Computing and Communications,Boston:ACM Press,2000:75 -84.
[2]Myung J.An adaptive memory less tag anti-collision protocol for RFID networks[D].Seoul:Korea University,2004.
[3]Sahoo A,Iyer S,Bhandari N.Improving RFID system to read tags efficiently[R].India:Institute of Technology Bombay,2006-06-209,2006.
[4]ISO.CD 18000—6,3N311—2002 information technology automatic identification and data capture techniquesradio frequency identification for item management-part 6:parameters for air interface communications at 860 MHz to 960 MHz[S].New York:ISO,2002.
[5]Wong W A,Baer J L.Modified LRU policies for improving second-level cache behavior[C]∥ Proceedings of Sixth International Symposium on High-Performance Computer Architecture,2000:49-60.
杂志排行

Defence Technology的其它文章
- Study on CAD Data Interface to Geometry Description System
- Modeling and Simulation for Complex Repairable System with Built-in Test Equipment
- A New Synthesis Method for Sum and Difference Beam Pattern with Low Sidelobe
- An Evaluation Approach for Operational Effectiveness of Anti-radiation Weapon
- An Orthogonal Wavelet Transform Fractionally Spaced Blind Equalization Algorithm Based on the Optimization of Genetic Algorithm
- Research on Performance of U Separator in Sand and Dust Test System