基于相对熵理论的网络DoS攻击检测算法
2011-03-08李涵秋
李涵秋,马 艳,雷 磊
(1.解放军63778部队,黑龙江 佳木斯 154002;2.解放军63780部队,海南 三亚 572427)
1 引 言
随着近年来Internet的迅速普及,网络己深入到社会生活的方方面面,在经济、文化、教育、军事等各行业和部门中发挥着重大作用。然而,随之而来的网络安全问题也日益受到了人们的关注。在众多的网络攻击手段中,拒绝服务 (Denial of Service,DoS)攻击是一种极具破坏力的攻击方式,它消耗可用系统、带宽资源迫使Web站点停止服务[1]。在现代信息战中,利用DoS攻击手段可以使重要的政府机构甚至军事站点瘫痪。
网络上所承载的信息是人们关心的重点,信息熵作为信息论中所提出的核心概念之一,学术界已经开始关注将其应用于网络攻击检测,并取得了一定的进展。Lakhina等人[2]在信息熵理论基础上对网络数据包的端口和地址的分布特性进行分析,检测异常的网络行为。Rahmani等人[3]利用流的数量与流中包含的数据包的数量之间的分布关系来检测DoS攻击,但时间间隔的选取对检测效果有较大影响。信息熵作为系统有序化程度的一个度量,能检测出DoS攻击对于正常网络流量随机性所产生的影响,然而网络流量的变迁是一个动态连续的过程,只取其中的一点而不去分析其与相邻时间序列之间的关系,对于未能引起流量分布显著变化的DoS攻击也很难检测。本文利用了信息论中另一个重要的理论——相对熵理论,通过分析DoS攻击发生时所造成的网络流量中IP、端口等属性分布特性的变化规律及其对相邻时刻网络流量序列之间的相对熵值的影响,提出了一种基于相对熵的网络DoS攻击检测(Relative Entropy Detection,RED)算法。
2 RED算法检测原理
2.1 相对熵理论
相对熵是指两个随机序列之间距离的度量,从统计学角度出发它是指两个随机序列之间的相似程度[4]。相对熵可定义为
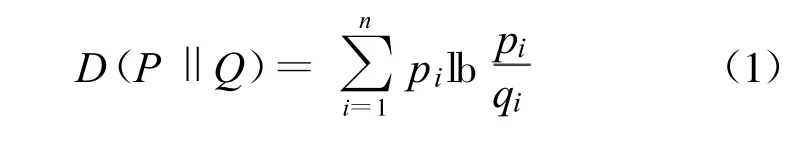
相对熵的重要性质有D(P Q)=0当且仅当P=Q,即P、Q两个分布序列完全相同时它们之间的相对熵值为0。D(P Q)的值越小表示分布序列P和Q越相似,反之则表示其相差越大。
基于相对熵的RED检测算法是建立当前时段Tcur的分布序列作为P,上一个时段Tpre的分布序列作为Q,通过计算 Tcur和 Tpre时段数据之间的相对熵用于DoS的攻击检测。
2.2 检测原理
近年来,对网络业务流量的实际测量和统计分析结果表明,互联网业务流量具有突发性(Bursty)、长相关、自相似性等主要特性。流量在宏观上的流量变化较大,但在微观层面,单位流量具有较为稳定的分布结构[5]。DoS攻击往往破坏网络流量稳定的分布结构,而采用相对熵就能很好地检测出这种变化。
从DoS的攻击手段方面进行分析:正常网络流量的目的IP的分布较均匀,当发生攻击时,被攻击IP的流量会显著增加,导致这个IP在统计中出现较大比例。同样,当DoS对某一特定的服务漏洞进行攻击时,也会引起目的端口属性、协议属性和包大小属性的分布发生较大变化。
从DoS的攻击效果方面进行分析:某一服务器向外提供服务所发送的数据包的源地址都为服务器地址,当DoS攻击造成服务器停止服务的后果时,会对网络流量中的源地址属性和源端口属性的分布造成较大影响。DoS攻击所瘫痪的服务主机越重要,这种分布变化就会越明显。
无论是从DoS的攻击手段还是从攻击效果上来分析,这些都可以通过相对熵值的跳变来检测攻击。
3 RED算法描述
3.1 RED算法步骤
基于相对熵理论的RED算法是一个以时间为循环变量的步进计算过程,每次循环收集Tcur时段的分布序列,并需要上一次循环中所收集的分布序列作为Tpre序列,计算Tpre和Tcur两个序列之间的相对熵值作为 Tcur时段的处理结果,最后将 Tcur时段的分布序列作为下一次循环的Tpre序列进入下一次循环。以计算源IP地址属性的相对熵值为例,算法步骤描述如下:
步骤1:参数初始化。定义 step为时段区间的长度,Tcur时段出现的IP存入ipSourceArrayCur结构中,计算这些IP出现的概率结果存放在 ipSourceProbaArrayCur结构中。
步骤2:取一条数据记录,若所有数据记录已取完则跳转到步骤10。判断该条数据记录是否在当前Tcur时段内,如在则跳转到步骤3,如不在则跳转到步骤4。
步骤3:从该条数据记录中提取出IP源数据,存入ipSourceArrayCur结构中并更新该IP源地址对应的计数变量。跳转到步骤2。
步骤4:表示Tcur时段内的所有数据已经统计完毕。通过ipSourceArrayCur结构分别计算其中每个源IP地址出现的概率并将计算结果存入ipSourceProbaArrayCur结构中。
步骤5:取 Tpre时段即上一次循环中所产生的ipSourceArrayPre结构和ipSourceProbaArrayPre结构。
步骤6:将Tpre和Tcur时段是数据合并。由ip-SourceArrayPre和 ipSourceArrayCur构 成 merge-SourceArray结构,由 ipSourceProbaArrayPre和 ipSourceProbaArrayCur构成mergeSourceProbaArray结构。
步骤7:通过mergeSourceProbaArray结构计算Tcur时段的相对熵值,并将结果输出。
步骤8:将变量 Tcur、ipSourceArrayCur结构、ip-SourceProbaArrayCur结构分别赋给变量 Tpre、ip-SourceArrayPre结构和ipSourceProbaArrayPre结构。
步骤9:将 Tcur以 step步进,ipSourceArrayCur和ipSourceProbaArrayCur结构清零。跳转到步骤2。
步骤10:算法结束。
该RED算法虽然计算相对熵时需要Tpre和Tcur两个时段的数据,但并不需要每次计算过程都分别运算Tpre和Tcur的相关数据,每次循环只需要填充Tcur的数据即可。当前循环的Tcur数据作为下一循环的Tpre数据使用,很有效地避免了数据的重复计算。
3.2 RED算法说明
RED算法中 Tcur时段的数据相当于P分布序列,Tpre时段的数据相当于Q分布序列。将Tcur时段和Tpre时段的数据进行合并时就会出现两种情况:对于在 Tcur时段出现而Tpre时段没有出现的元素其对应的,此时定义,对于随着时间的推移而消失的IP等元素,通过下降的幅度来影响相对熵值;对于在Tpre时段出现而Tcur时段没有出现的元素定义其对应的,,此时定义,对于本时段突然出现的IP等元素赋予较高的权值,通过出现的频率与权值的乘积来影响相对熵值。
4 实验与讨论
实验使用了MIT实验室在美国国防先进技术研究计划署(DARPA)和美国空军研究所共同资助下所公布的DARPA99数据集,该数据集已经作为研究领域所认可并广泛使用的评测标准。
为了分析RED算法与信息熵检测算法相对比所具有的优势,选取了含有较多种DoS攻击的Apr-5-outside.dump数据包计算IP地址属性结果,如图1所示。

图1 IP属性的信息熵值与相对熵值对比图Fig.1 Comparison between relative entropy and information entropy value of IP property
图1中分别使用了RED算法和信息熵算法对目的IP地址和源IP地址属性进行了计算。ipSrcBE和ipDesBE分别表示源IP地址和目的IP地址的信息熵值,ipSrcRE和ipDesRE分别表示源IP地址和目的IP地址的相对熵值;标记A表示在19092 s爆发,持续了120 s的Smurf攻击;标记B表示在43227 s爆发,持续了900 s的Udpstorm攻击。通过这两个攻击实例具体分析RED算法与信息熵检测算法的共性与区别。
信息熵算法和RED算法都可以检测Smurf攻击。Smurf攻击爆发时大量主机同时向受害主机发送ICMP报文。信息熵算法中ipSrcBE值明显增大是因为该时段内的源地址数目急剧增多分布发散使系统处于无序状态。ipDesBE值明显降低是因为该时段目的IP地址数目相对集中。RED算法中ipSrc-CE值明显增大是因为与前一时段相比出现了大量新的源IP地址且各地址的概率分布都发生了较大变化。ipDesCE值也明显增大是因为与前一时段相比,原有的大量目的IP地址消失,同时受害主机的IP地址出现概率明显增加,从而也使网络流量的分布结构发生较大变化。
信息熵算法无法检测UdpStorm攻击而RED算法可以。UdpStorm攻击是通过伪造的UDP数据包使多个受害主机之间不停的相互发送数据从而造成网络的拥挤消耗有效带宽。该时段内各主机之间在进行通信,源IP地址和目的IP地址都未出现明显的集中或发散的现象,信息熵值不会产生较大的变化,从图1中标记B处的ipSrcBE和ipDesBE值未发生变化也验证了这一点。RED算法可以检测Udp-Storm攻击是因为虽然IP地址并未发生较多变化而每个IP地址的出现概率都发生较大的变化使相对熵值明显增大。选取攻击前一时刻与攻击发生时刻源IP地址的相对熵值进行对比,结果如表1所示。

表1 相对熵值与信息熵值对比表Table 1 Comparison between relative entropy and information entropy
从表1中可以看出,在攻击发生时刻与攻击还未发生的前一时刻相比,IP数量没有明显变化,并且也没有发生涌现出较多新IP地址的情况,所以信息熵值比较稳定,无法检测出UdpStorm攻击。Udp-Storm攻击造成网络的拥挤和减慢使各主机之间的通信无法正常进行,导致各地址的概率分布均发生了较大变化,从而导致了相对熵值的明显增大。
分析RED算法与信息熵算法的本质区别在于信息熵只关心宏观上IP地址的分布情况而相对熵不仅考虑宏观的分布变化并且还考量其中各个元素的变化情况。
为了进一步验证 RED算法的有效性,将DARPA99数据集中所列出的17种DoS攻击组合为170次攻击数据,并随机插入到第一周和第三周的正常的网络流量数据中。RED算法和信息熵算法的检测结果对比如表2所示。
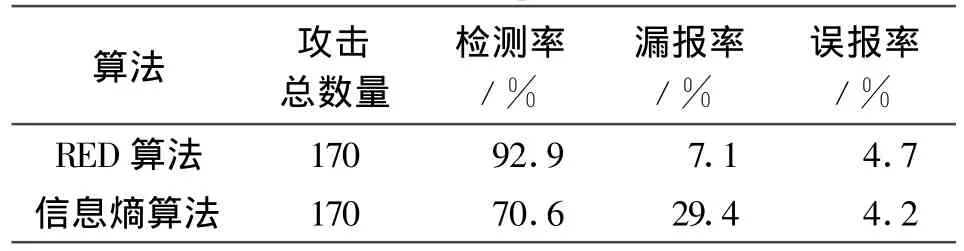
表2 RED算法和信息熵算法检测结果对比Table 2 Comparison between the results of RED and the information entropy detection
由表2可知,基于相对熵的RED算法相比信息熵检测算法对于DoS攻击具有更高的检测率,但RED算法将一些正常网络状态的转变误判为攻击导致了一定的误报率。
5 结 论
本文针对DoS网络攻击行为提出了一种基于相对熵理论的RED检测算法。相比传统信息熵检测法,RED算法不仅考虑宏观的分布变化而且从微观角度考量其中各个元素的变化情况,实验结果表明攻击检测率有了较大提升。未来研究的方向是如何在RED算法基础上更好地区分正常突发性流量和攻击流量,从而有效降低误报率。
[1]Loukas G,Oke G.Protection Against Denial of Service Attacks:A Survey[J].Computer Journal,2010,53(7):1020-1037.
[2]Lakhina A,Crovella M,Diot C.Mining anomalies using traffic feature distributions[J].Computer Communication Review,2005,35(4):217-228.
[3]Rahmani H,Sahli N,Kammoun F.Joint entropy analysis model for DDoS attack detection[C]//Proceedings of the Fifth International Conference on Information Assurance and Security.Xi′an:IEEE,2009:267-271.
[4]ThomasM,Joy A.Elements of Information Theory[M].New York:John Wiley&Sons Inc.,2006:19-22.
[5]石江涛,王永纲,戴雪龙,等.自相似网络业务流量的研究与实现[J].通信学报,2005,26(6):112-120.SHI Jiang-tao,WANG Yong-gang,DAI Xue-long,et al.On study andimplementation of self-similar network traffic[J].Journal on Communications,2005,26(6):112-120.(in Chinese)
