基于P2P的分布式网络故障监测系统的研究
2011-01-23杨安祺张俊明
唐 军, 杨安祺, 张俊明
(陕西科技大学电气与信息工程学院,陕西西安710021)
0 引 言
随着社会信息化的发展,如何在减少网络监测数据流量和为用户节省带宽的情况下及时的监测故障数据成为一个越来越重要的问题。另一方面,随着网络技术的迅速发展,规模的不断扩大,复杂性的不断增加,网络的异构问题也越显突出,使得对网络故障监测提出了更高的要求。传统的C/S(client/server)模型和单纯的分布式故障监测模型已经无法再适应现有的网络需求[1]。为了更好的适应网络发展,需要一种能快速响应网络故障,解决现有网络监测瓶颈问题,具有更好的扩展性和伸缩性的新型网络故障监测模型。基于P2P的分布式网络故障监测系统就是在这种情况下产生的。目前国外在网络故障监测方面的研究比较成熟,已有一些公司研制开发出综合的网络故障方面的系统,如NAI公司的Sniffer、HP公司的NetMetrix等,这些产品在具有优越性能的同时也具有相当昂贵的价格,国内开发的GNMA综合故障分析系统具备了监测、分析等功能,但是该产品只能对局域网进行故障方面的分析。本文采用P2P技术作为解决传统网络故障监测模型中服务器瓶颈问题的方法,并以开源的Drools作为系统原型中的告警规则分析引擎。
1 JXTA简介
分布式计算发展非常迅速,新技术不断出现,现在出现的P2P技术,让用户可以直接连接到其它用户的计算机,进行文件共享与交换,另外P2P在深度搜索、分布计算、协同工作等方面也大有用途。但现有的P2P系统有一些缺陷,大多数P2P系统用来实现一个单一类型的网络服务(Napster用来音乐文件交换、Gnutella用来普通文件交换),由于不同的网络服务的特性和缺少一个共同的底层基础,每一个供应商都使用不兼容的技术使它的用户同别的P2P通信相隔离。SUN公司推出的JXTA技术通过提供一个简单的普遍的P2P平台来解决这个问题[2],JXTA具体来说是一种标准组件平台,它提供了用于开发分布式服务和应用程序的基本组件。整套技术由一组开放源码的P2P协议组成,这组协议使网络上任何连接着的计算设备的协作变为可能。JXTA支持P2P应用的基本功能来建立一个P2P系统,还将努力证实这些可以成为建立更高层功能的基础构造模块。JXTA架构可以分为3个层面:JXTA核心层、JXTA业务层和JXTA应用层[3]。JXTA使可共同使用的P2P应用程序拥有了许多能力,该技术具有易实施性、标准化和跨平台等传统方式不可比拟的优势。故使用基于P2P的分布式网络监测方式将大大减轻网络通信的负载,当网络拓扑、组织形式或网络管理服务发生变化是,监测网络能随之动态变化,充分满足了分布式网络监测新的需求。
2 系统分析与设计
网络故障监测系统建立在JXTA标准P2P平台上,通过对被监测设备底层抽样获取的数据进行告警分析后,上报域监测工作站或服务器,从而实现整个分布式网络故障进行监测。系统主要分为3个独立的功能模块:数据抽样模块、告警相关性分析模块以及拓扑发现和故障检测管理模块。各模块独立封装,根据模块特点采用不同编程技术,以实现各个模块之间的高内聚、低耦合。整个系统的核心部分是对底层驱动程序数据包的采样读取,对数据的实时性要求高,数据抽样模块利用NDIS(network driver interface specification)协议[4]提供的接口和Win32的重叠I/O操作以及多线程特性极大的提高了采样数据的实时性,对于采样到的数据的存储采用了直接文件方式,提高了此模块的实时处理能力。告警相关性模块、拓扑发现以及故障检测管理模块采用Eclipse+Java开发,实现与JXTA与开源规则引擎[5]Drools以及JXTA提供的接口之间的无缝连接。单域故障监测业务示意图如图1所示。
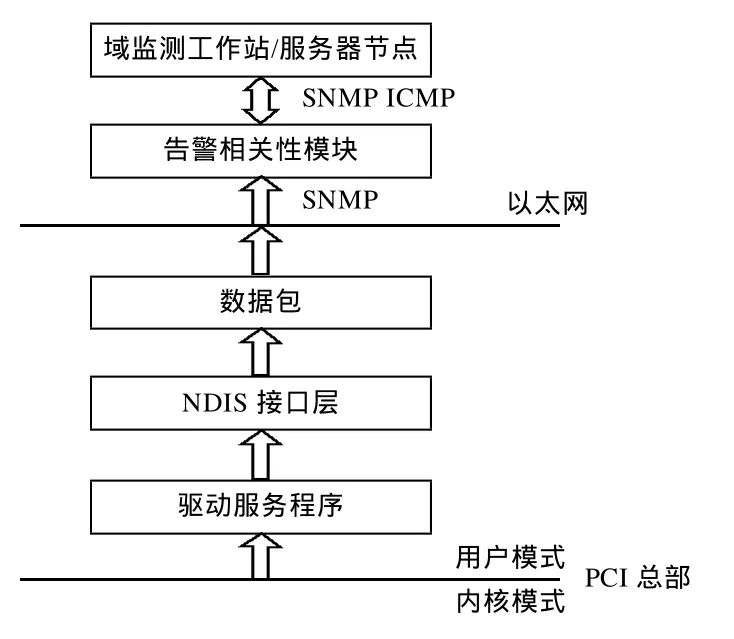
图1 单域故障监测业务流程
2.1 网络故障监测方法
网络故障[6]通常有以下几种可能:物理层中物理设备相互连接失败或者硬件及线路本身的问题;数据链路层的网络设备的接口配置问题;网络层网络协议配置或操作错误;传输层的设备性能或通信拥塞问题。
现有的网络故障监视算法有前摄性算法,交互式监视算法。前摄性监视要求用原始数据来预测未来趋势如可能发生的情况等工作,所以前摄性监视系统需要结合自适应学习系统,此系统学习掌握每个测量变量的正常行为,并检测出测量变量对正常值的偏离,可以推演未知网络故障,同时关联时间和空间的信息,对于可能由于网络故障引起的网络拥塞问题进行预测,并考虑可以施加一定的调度算法,使得管理人员采取一定的措施在网络故障发生前阻止故障的发生。交互式监视算法针对的是硬网络故障,管理者与代理之间采用轮询和事件通知的交互方式获得网络中被管对象变量的状态信息,提供了这些变量结构的定义以及通信机制。但这些变量自身不能检测网络故障,需要进一步处理,以获得对网络故障根源状态的分析。这种算法主要考虑如何合理的选择轮询频率以及轮询步长,从而减少通信资源的消耗。
监测网络故障的过程应该沿着OSI七层模型从物理层开始向上进行,首先检查物理层,然后依次检查数据链路层、网络层和传输层,设法从采集到的故障信息中确定通信失败的故障点和故障原因,并结合历史数据和专家知识库给出相应的排除故障的方法。
2.2 系统功能模块
系统将整个网络划分成若干个故障监测域,每个域中存在1到2个故障信息监测节点,负责本域的故障监测,所有分布在各处的故障监测节点动态的组成P2P故障监测网络,节点间采用P2P消息机制传输监测到的故障信息,协同完成对整个网络的故障监测,并在网络中配置多个特殊的节点,这些节点在P2P监测网络中通过监测节点对整个网络进行监测。故障域的通信模式示意图如图2所示。

图2 P2P故障域通信模式
3 各模块的设计实现
3.1 数据采集模块
数据采集模块是用来对被监测设备上的故障信息进行采集和基本的过滤,并负责将过滤后的数据发往所在的域服务器上,由它进行更高一级的告警相关性分析。NDIS协议为传输层提供标准的网络接口,所有的传输层驱动程序都需要调用NDIS接口访问网络,NDIS把网络驱动程序从网络硬件中抽象出来,制定了网络驱动层与层之间的规范。采用NDIS可以方便高效的获得被监测设备的数据。获取被检测设备的故障信息通常的可靠方法是不断的对被检测对象周期性的轮询,这样将导致网络流量特别是监测工作站和监测服务器端的流量增大,有可能造成以监测端为节点的链路拥塞,因此,数据的采样算法十分重要,目前比较常用抽样方法是周期抽样、随机附加抽样和泊松抽样。泊松抽样的时间间隔符合泊松分布,能够实现对测量结果的无偏估计、测量结果不可预测、不会产生同步现象,限定一个最大间隔值的泊松抽样,可以避免产生较长的抽样间隔,加速抽样过程的收敛,并结合C语言实现关键算法以实时的获取被测设备的数据。由于泊松抽样具有很多好处,所以被系统数据抽样算法采用泊松分布[7]。Poisson分布的概率函数如公式(1)所示
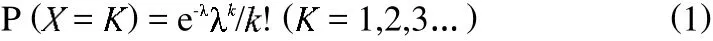
公式(1)中表示单位时间(单位人群、单位空间内,单位容积)内,某罕见事件发生次数的概率分布式中 =n为Poisson分布的总体均数,总体中没单位中的平均阳性数,X为单位时间或单位空间内某事件的发生数(阳性数),e为自然对数的底,约等于2.71828。
通过简单的设置4种基本过滤条件:帧属性条件、网络地址条件、数据模式条件和协议类型条件,实时地分析采样的协议包,将满足条件的帧传输到所在域的故障服务器上。被监测设备与域监测节点之间采用简单网络管理协议SNMP进行通信[8],SNMP建立在无连接方式的UDP和IP协议之上,省去了应答信息,执行起来非常高效。SNMP规定了5种协议数据单元PDU,用来在管理进程和代理之间的交换,只有两种基本的管理功能:“读”操作,用get报文来检测各被管对象的状况;“写”操作:用set报文来控制各被管对象的状况。每个被检测设备都作为一个MIB库中的对象,针对故障信息的严重程度分别采用实时传输和定时轮询两种传输方式。
3.2 告警相关性模块
3.2.1 网络告警信息分析
网络告警信息包含大量的不确定性信息,同时告警信息的不完备以及数据传播的动力特性都加大了故障监测的难度,需要对告警信息进行相关性分析,优化网络故障监测。告警相关性分析模块位于故障监测节点上,目的是将有关联性的多个告警信息通过过滤识别等技术整合成为一条具有更多告警信息量的告警记录,以准确快速地识别故障的根源并减少通信所占的带宽。由于网络设备的多样化,需要对采集来的信息进行统一的格式化处理,用来屏蔽网络设备告警信息的差异。以下为统一后的告警信息类代码:

3.2.2 告警事件类型及处理方式
告警事件的相关性及处理方法通常分为3类:
(1)相同事件:来自同一告警源的相同故障描述的持续的告警信息。对于这种情况,只显示一条故障信息和
改变告警频度;
(2)相反事件:两个来自同一告警源的信息,故障告警和故障恢复告警。对于这种情况,自动将告警事件清
除,并存入已清除的历史告警日志中;
(3)同源事件:来自同一告警源但类型不同的多个告警信息。对于这种情况,通过分析告警信息对其进行根
源性的识别,挑选出一条根源性的告警记录,其它同源信息标记为抑制信息;
对于以上3种情况,根据网络拓扑关系库,从中按照相关规则的规定,选出最具根源性的告警记录(如果不存在的话,依照规则生成一条告警),其它的事件标记为抑制告警信息。
3.2.3 告警相关性模块分析
告警相关性分析模块由以下3个子模块组成:
(1)规则提取模块:通过对历史告警信息的分析和故障知识库的学习来获取和创建规则,并将新的规则添加到规则集中。
(2)规则管理模块:通过ADD、DEL、MODIFY等操作维护告警相关性模块。
(3)告警相关性分析引擎:通过规则引擎算法对大量告警信息进行相关性分析,给出根源告警信息,能大量的减少冗余告警事件,降低告警信息的网络带宽占有率并提高故障定位准确率。
每个故障监测系统都不能保证它能提供完备的故障处理策略,因此需要引入高效的利于对多变的业务规则进行修改和管理的规则引擎技术。
Drools[9]是基于Java的优秀开源规则引擎,封装了Rete算法,Drools的规则提取方法有两种:基于网络专家系统知识和通过数据挖掘技术发现告警序列中的关联规则。其中专家系统通过模拟人的推理方式,使用试探性的方法进行那个推理,而规则引擎则采用目前效率最高的一个 Forward-Chaining推理算法——Rete。本系统采用关联规则挖掘方法获取告警相关性规则,将挖掘结果辅以专家知识加以分析,最终确定相关性规则集。
3.3 拓扑发现和网络故障监测管理模块简介
拓扑发现模块利用SNMP、ARP、ICMP实现对本域的IP网络的三层拓扑发现,这3种协议具有负载低、速度快和准确性高的优点,适合中型网络的拓扑发现。实现方法是从默认的路由器开始,进行指定拓扑搜索深度的广度优先搜索,利用SNMP路由表发现路由器之间的连接关系,根据接口表找到相连路由器的互联接口,用互联接口所在的子网描述路由器间的连接关系,同时利用MIB的地址表得到与路由器直接相连的子网地址及子网掩码。用路由器接口IP地址中的最小值标识路由器,同时利用MIB中的ipAddrTable表进行多IP的同一路由器的判定。拓扑发现由主拓扑发现和子拓扑发现两部分组成:
(1)主拓扑发现:通过计算取出冗余的路由器相关拓扑信息,形成已访问的路由器链表,并通过分析已访问路由器链表,按照拓扑数据库定义的格式形成子网链表和节点链表。
(2)子拓扑发现:遍历已访问路由器链表,从获得的ARP表中取得与路由器直连的网络设备的IP地址;遍历子网链表,通过将获得的IP地址与已经取得的子网地址进行模式匹配来确定该IP对应的主机是否为相应子网的成员,如果是,则将得到的主机节点信息写入拓扑数据库。
网络故障检测管理模块将告警相关性分析模块传输上来的数据进行解码,并与库中的数据进行匹配,快速的进行故障的定位,并提出相关的修复建议,采用关联数据挖掘的方式已进行实时的响应。
4 实验结果与分析
在模型的性能发面,将基于传统的故障监测模型与本文所提出的基于P2P的分布式网络故障监测模型进行了简单的对比试验,试验结果如图3和图4所示。
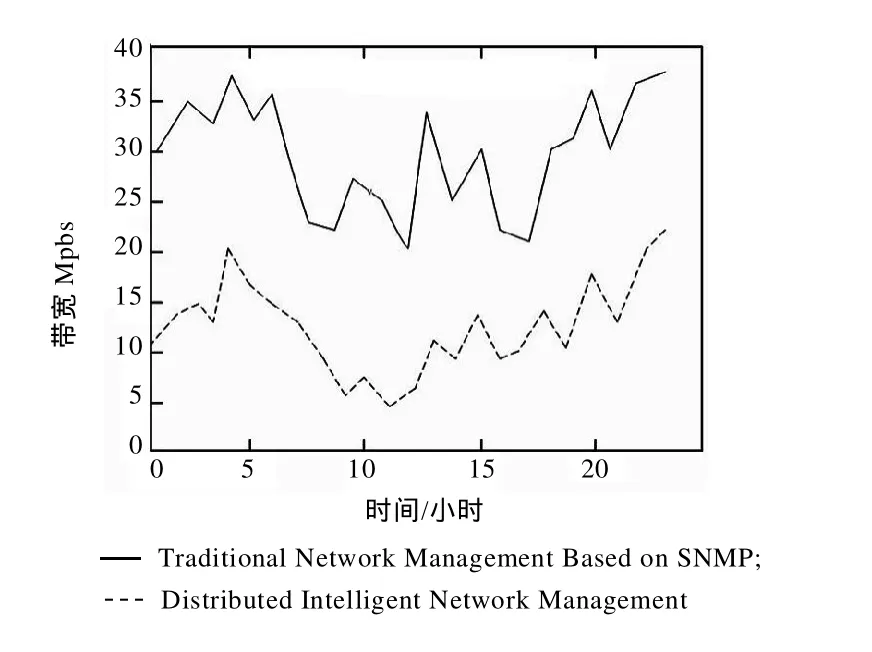
图3 带宽占有率/时间结果
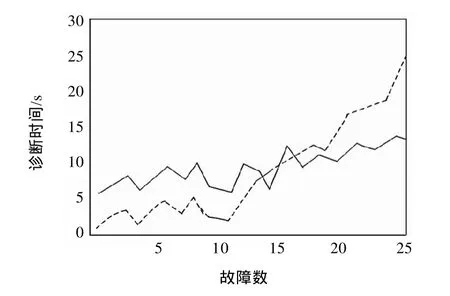
图4 故障数/时间结果
通过试验发现,传统的故障监测系统容易造成监测端数据链路阻塞,降低了有效带宽,在网络规模不大的情况下,基于P2P的分布式网络故障监测模型和传统的故障监测模型相比,在规模越小的情况下,P2P模型的分布式故障监测模型有需要消耗在对等点发现的额外带宽比传统监测模型的不需要在方面消耗带宽来比较,在性能上优势不明显。从故障的监测响应时间上看,由于P2P故障监测模型消耗对等点发现的时间,所以此模型的优势不明显,当故障数目增加时,基于P2P分布式网络故障监测模型的优势也就明显了。
在故障监测方面,由于采用了Drools相关性分析引擎和柏松采样收敛算法,在监测故障方面同传统式故障监测模型在正确监测、误判和漏检的性能对比如表1所示。
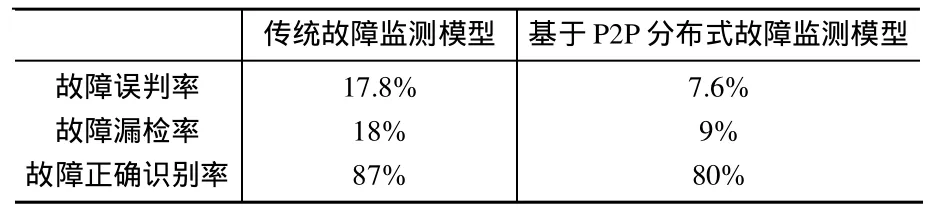
表1 传统模型与P2P模型性能对比表
试验表明,本文提出的基于P2P的分布式故障监测模型的可行性,基于此模型设计实现的系统能提高网络故障监测方面性能,有助于增加故障监测系统故障诊断的有效性,在大型网络环境中,能提高故障监测系统的实时性。
5 结束语
本文提出了新型的基于P2P的分布式网络故障监测方法,将P2P体制引入故障监测当中,给出了系统的模块划分和实现手段。通过系统简单原型的实现,证明了该方法的可实施性,通过实验数据与传统的故障监测系统进行比较,证实了新系统较传统集中式监测系统具有更好的实时性,传统系统中的带宽瓶颈问题得到了较好的解决。当然,P2P网络故障监测系统是非常复杂的,还有许多问题需要进一步的研究,比如移动环境下P2P覆盖网络与物理网络匹配问题以及抽样算法以及规则引擎算法等问题。
[1] 郭健,吴伟明,张爱霞.面向业务的NGN综合网管系统的研究[J].数据通信,2005(3):9-12.
[2] 姜兆华,杨斌.基于JXTA和P2P的资源发布系统研究[J].计算机与信息技术,2008(z1):60-62.
[3] 务实.JXTA技术应用与发展[EB/OL].http://www.builder.com.cn/2003/1009/98421.shtml/,2003-10-09.
[4] 杨智君,田地,周斌.基于NDIS中间层驱动程序的网络监测器[J].吉林大学学报(工学版),2006,36(2):224-226.
[5] 缴明洋,谭庆平.Java规则引擎技术研究[J].计算机与信息技术,2006(3):41-43.
[6] 张新,常义林,沈中,等.分层多管理者网络故障监控策略[J].西安电子科技大学学报,2005,32(6):873-876.
[7] 王恒,刘振宇.一种基于访问约束的数据同步技术[J].微计算机应用,2007,28(12):2-3.
[8] 鲁建邦.网络服务性能监测方案的探讨[J].计算机应用,2004,24(9):1-2.
[9] 马秀丽,王红霞,张凌云.Drools在网络故障管理系统中的应用[J].计算机工程与设计,2009,30(8):1-3.
