基于遗传神经网络的相似重复记录检测方法研究*
2011-01-15郭乐江胡亚慧
肖 蕾 郭乐江 胡亚慧 程 敏
(空军雷达学院 武汉 430019)
基于遗传神经网络的相似重复记录检测方法研究*
肖 蕾 郭乐江 胡亚慧 程 敏
(空军雷达学院 武汉 430019)
设计实现了一个相似重复记录检测系统,该系统包括预处理模块、聚类模块、字段匹配模块和记录匹配模块,支持聚类算法和字段匹配算法的定制扩充。并通过实验对比了几种著名的算法,实验结果表明该系统提高了相似重复记录检测的精确度。
遗传神经网络;相似重复记录检测系统;聚类算法;字段匹配算法
Class NumberTN958
1 引言
相似重复记录清洗技术的核心是重复记录检测,即如何判定两条记录是不是重复记录。在判定记录是否是重复的过程中,绝大多数的重复记录检测算法都采用了“等值理论”,引入了相似度的概念,用记录相似度对记录之间的等值程度进行量化,根据相似度的大小判定记录是否等值。所以重复记录检测的核心是准确的计算两条记录的相似度。在数据仓库或数据库中,记录都是由多个字段值组成,因此,计算记录的相似度的基础是记录各个字段的相似度。我们发现不同的字段相似度计算方法往往对特定的类型的字符特别有效,并不能对所有类型的字段值都有很好的效果,例如:Jaro-Winkler算法对拼写错误类型的字段有很好的检测效果。
基于以上分析,提出了一种基于遗传神经网络的相似重复记录检测系统。首先,该系统由用户选择字段匹配算法计算记录对应的字段值的相似值;其次,在字段相似度基础上使用遗传神经网络模型计算记录对的相似度;最后,根据记录的相似度值进行判定。
2 EADDS的整体结构和特点
2.1 EADDS的整体结构[1~2]
相似重复记录检测系统EADDS的工作流程图如图1所示。
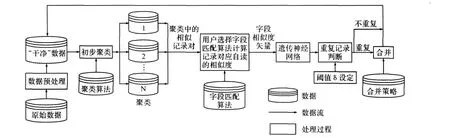
图1 EADDS的工作流程图
图1描述了EADDS的工作流程图,原始数据经过数据准备、初步聚类、重复记录检测、重复记录判定处理后,最后检测出原始数据集中所有的重复记录。下面分别介绍4个模块。
1)数据准备模块
为了保证清洗的效率和精度,在进行重复记录清洗之前要对原始的数据进行预处理。EADDS的数据准备模块,通过对原始数据进行解析、转换、标准化,解决了原始数据中的各种问题,如异构数据源中属性定义不同、字段空缺值处理、数据格式等。数据准备模块的功能就是使数据以统一的格式存入到数据库中。
2)聚类模块
通常,在重复记录检测时要对数据集进行初步聚类,目的是降低检测的时间复杂度。在EADDS中,我们集成了当前的各种聚类算法,包括邻近排序法(SNM)[3~4],多趟排序法(MPN)[3~4],优先权队列算法[5]等。在进行重复记录的检测时,EADDS允许用户对所有的聚类算法进行选择,利用所选择的聚类算法对数据集进行初步聚类。EADDS也允许用户对聚类模块进行扩展,即将新的聚类算法引入系统中,以供用户进行选用。
3)字段相似度计算模块
该模块主要是计算两条记录对应的字段的相似度值。针对不同的字段一般只对特定类型的字段有效的特性,EADDS集成了多种有效的字段相似度计算方法,对于不同的字段允许用户选择相应的字段相似度计算方法,计算相应的相似度值。EADDS也允许用户对该模块进行扩展,即将新的字段相似度计算方法引入系统中,以供用户进行选用。
4)基于遗传神经网络的相似重复记录检测模块
该模块主要是在字段相似度值的基础上计算两个记录对的相似度的值。该模块以字段相似度矢量作为输入,输出为两个记录对的相似度值。基于遗传神经网络的相似重复记录检测的模型如下:系统分为训练阶段和检测阶段,如图2所示。
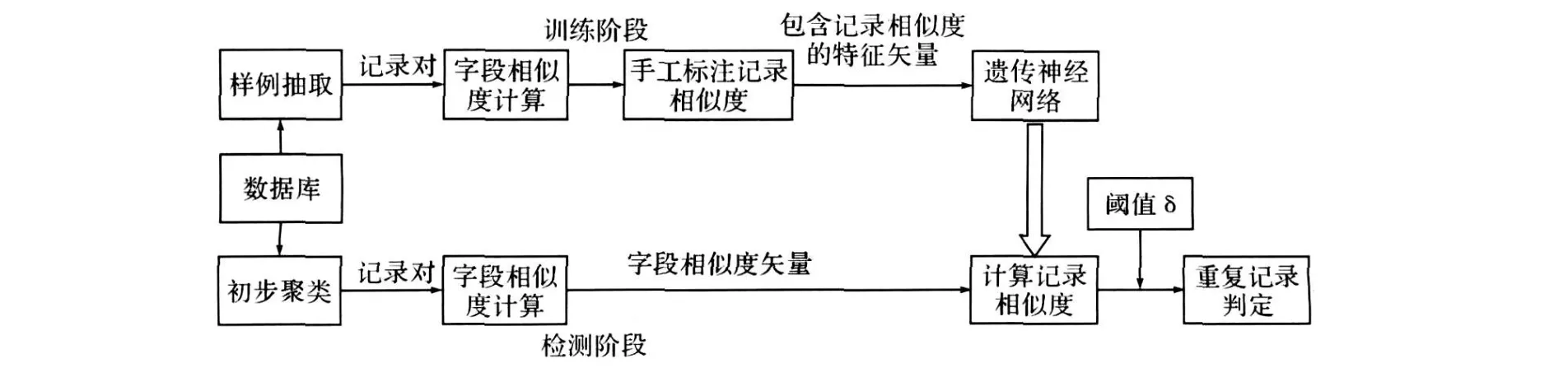
图2 基于遗传神经网络的检测模型
在训练阶段,首先,从数据集中抽取若干个记录对作为训练样例,在抽取的记录对中尽可能的包含各种字符串类型的记录对;其次,计算出两个记录对应字段的相似度,并手工标注记录对的相似值;最后,将包含记录相似度的特征矢量作为输入,训练神经网络。
在检测阶段,计算出记录对对应字段的相似度,得到记录对的相似度矢量,再利用训练好的遗传神经网络计算记录的相似度;最后,选择合适的阈值δ,确定是否是重复记录。
2.2 EADDS的特点
1)可扩展性
EADDS允许对数据数据准备模块、聚类模块、字段相似度计算模块进行扩展,使各种新技术可以应用到系统框架中,从而可以提高各个模块的性能,最终提高重复记录检测的整体性能。
2)可交互性
EADDS通过各个模块与用户进行交互。在运行过程中,要求用户对聚类算法、字段相似度计算方法、阈值的选取进行选择,并通过日志存储处理过的历史记录,用户可根据日志对各个模块中运行的算法以及阈值进行调整。
3)组件模块的可重用性
EADDS的各个模块各自完成特定任务,相互独立,因此相互之间耦合度较低,可以实现重用。基于该系统框架可以开发出不同领域的重复记录检测系统。
3 评价标准
在重复记录清洗领域,研究人员一般采用召回率(Recall)和精确率(Precision)作为相似重复记录检测的评价标准。
召回率,也称为命中率,定义为正确检测出的重复记录数(True Positives)与所有的重复记录(Real Duplicates)的比值,如式(1)所示:
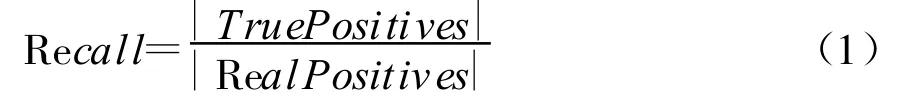
准确率是指正确检测出的重复记录数(True Positives)占所有检测出的重复记录(Detected Duplicates)中所占百分比,如式(2)所示:
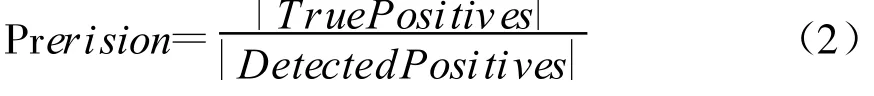
性能好的检测方法应具有较高的召回率和准确率。由定义分析可知,召回率和准确率与阈值δ有关,当δ值增加时,在检测出的重复记录中应该含有更多的检测正确的重复记录,即准确率提高了,但是由于检测正确的重复记录数少了,所以召回率降低了;反之,当δ值减小时,准确率降低,召回率提高。
为了更加直观的对清洗算法进行评价,在召回率和准确率的基础上又定义了一个新的评价标准—最大F1值。F1的定义如式(3)所示:

其中,R表示召回率,P表示准确率。
F1值是召回率和准确率的函数,平均值反应了检测方法的性能。F1值越大,检测算法性能越好。
4 仿真对比实验
为了验证本文提出方法的性能,将实验结果与TF-IDF与Marlin两种著名的相似重复记录检测方法进行了比较。TF-IDF方法首先将记录所有的字段值连接为一个字符串,然后利用TF-IDF方法计算字符串的相似度,进而进行重复记录的判定;Marlin是一种基于编辑距离的方法,提出了一种可学习的带放射间隔的字符串编辑距离,具有良好的整体性能。
采用的实验数据是由Febrl[5]系统中的数据生成程序生成的数据。测试数据生成器生成的数据包括姓名(surname,given name),地址(address,suburb,street number),出生日期(date or birth),电话号码(phone number),邮政编码(postcode),社会保险号(social security number)和年龄(age)等字段,其中原始数据信息来源于美国的电话手册中。实验数据集中共有7200条记录,其中包含650条相互重复的记录。
EADDS中,选择优先队列作为初步聚类算法,字段匹配算法的选则为,字段 given_name、surname采用 Jaro,字段 street_number采用Levenshtein,字段 address_1、suburb采用 TF-IDF,字段date_of_birth、soc_sec_id采用Smith-Waterman。EADDS的实际测试输出如图3所示。
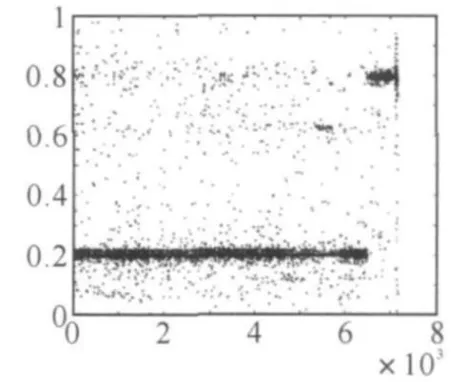
图3 EADDS测试输出
从测试输出图上可以看出,大部分输出比较接近0.2和0.8。若我们把阈值定为0.5,即相似度小于0.5的为非重复记录,相似度大于0.5的为重复记录。在7200条测试记录中,EADDS检测出有672条重复记录,在检测出的重复记录中,有631条记录为真正的重复,错误检测为重复记录的记录为41条,所以,精确率为0.93,召回率为0.97。
在实验数据集上分别对 TF-IDF和Marlin进行实验。首先确定精确率的值,然后再确定三种方法相应的召回率,如图4所示。
从实验结果图上可以看出,对于不同的准确率值,EADDS的召回率值要比其他两种方法高,这说明在进行相似重复记录检测时,在用户指定的精确度的情况下,EADDS比其他的方法能够更多的检测出数据集中的相似重复记录。同样,对于不同的召回率值,EADDS的准确率值也比其他两种方法高,这也说明检测时,在用户指定的召回率的情况下,EADDS比其他的方法能够更加精确的检测出重复记录。
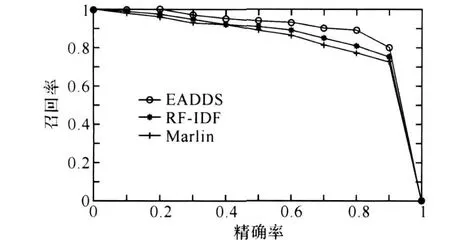
图4 测试结果图

表1 相似重复记录检测的最大 F1值
表1显示了在数据集上进行实验所得到最大的F1值的平均值。因为F1的值表示了一种检测算法的整体性能,因此从表中可以看出,EADDS比TF-IDF和Marlin具有更高的整体性能,具有良好的检测效果。
5 结语
设计并实现了一个基于遗传神经网络的相似重复记录检测系统EADDS。该系统是一个可扩展的检测系统,支持聚类算法和字段匹配算法的定制扩充,具有较好的通用性。实验对比了EADDS与现有相似重复记录检测方法的性能,证明了EADDS的有效性。
[1]Hernandez M,Stolfo S.The merge/purge problem for large databases[J].ACM SIGMOD Record,1995,24(2):127~138
[2]Monge A,Elkan C.An efficient domain-independent algorithm for detecting approximately duplicate database records[C]//Proceedings of the ACM-SIGMOD Workshop on Research Issues on Knowledge Discorvery and Data Mining,Tucson,AZ,1997
[3]Hernandez M A,Stolfo S J.Real-world data is dirty:data cleansing and the merge/purge problem[J].Data Mining and Knowledge Discovery,1998,2(1):9~37
[4]周芝芬.基于数据仓库的数据清洗方法研究[D].上海:东华大学硕士学位论文,2004
[5]A.Monge,C.Elkan.An effieient domain independent algorithm for detecting approximately duplicate database reeords[J]//proeeedings of the SIGMOD workshop on Data Mining and Knowledge Diseovery,Tueson,Arizona,1997:211~217
Study on Approximately Duplicate Record Detection Method Based on Genetic Neural Network
Xiao Lei Guo Lejiang Hu Yahui Cheng Min
(Air Force Radar Academy,Wuhan 430019)
An extensible duplicates detecting system is designed and implemented.This system includes data preparation module,clustering module,field matching module and record matching module.The working principle and implementation mechanism in process of the four modules are given respectively in this dissertation.In our experiments,we compare the performance of our method with some famous approximately duplicate records detecting algorithms.The experiment results show that the system improved the precision.
genetic neural network,approximately duplicates detecting system,clustering algorithm,field matching algorithm
TN958
2010年8月10日,
2010年9月17日
肖蕾,女,助理实验师,研究方向:计算机网络。郭乐江,男,博士,讲师,研究方向:计算机网络。胡亚慧,女,硕士,讲师,研究方向:计算机结构。程敏,女,助教,研究方向:计算机网络。
