基于web的拼音首字母快速查询的设计与实现
2011-01-12李太宁
叶 钰,李太宁
(1.泰州职业技术学院电子信息与工程系;2.泰州市心生软件有限公司,江苏 泰州 225300)
基于web的拼音首字母快速查询的设计与实现
叶 钰1,李太宁2
(1.泰州职业技术学院电子信息与工程系;2.泰州市心生软件有限公司,江苏 泰州 225300)
文章简述了现有的操作系统和应用软件对中文编码支持的情况,对现有的常用拼音首字母快速查询方案进行剖析。提出了新的解决思路,从理论、设计思路、具体操作等多方面对其进行深度讲解,快速提高了通过拼音首字母快速查询到汉字,为拼音首字母的快速查询提供了一种较新的思想和一种可实施的方案。
拼音;通讯录;中文编码;数据库
众所周知,汉字是世界上编码最复杂的语言,在Unicode5.0的99089个字符中,有71226个字符与汉字有关。而如何在这么多汉字中,用键盘上的二十六个英文字母就能快速定位到想要的各种汉字组合,是一项极其复杂的计算。通过开发科研项目《基于web的通讯录管理系统》时就遇到了这一问题!经过课题组成员的反复思考、论证、总结,最后提出了该构想。
1 各种操作系统以及软件对中文支持的现状[1]
随着经济的发展与需要,汉字编码标准也在不断发展。按照发布时间,汉字编码标准顺序大致有GB2312、GBK、GB13000.1、GB18030-2000、GB18030-2005等。windows95中文版支持GB2312的七千多个汉字,从windows98到现在的windows7中文版才开始支持GBK。虽然2001年,Microsoft开发了Windows补丁,用于支持GB18030-2000标准,但是并没有普及到所有Windows系统中,而对于2005年颁布的GB18030-2005标准,微软到现在也没使用在Windows桌面操作系统。对中文支持最好的Windows都如此,其他的诸如Linux等操作系统对中文的支持就更差了。
开发软件中,对中文支持最好的应该算是Microsoft的.Net Framwork开发环境与Oracle的Java Runtime Environment,这两种开发平台都支持GBK以及Unicode4.0。但是目前要想支持GB18030-2000以上国内标准或Unicode4.0以上版本的国际标准,都还需要安装补丁来实现。应用软件中如浏览器,只有IE能够较好的支持GBK标准内的所有汉字,其他浏览器诸如Firefox3、Chrome10等如今市场占有率排在前端的浏览器,都没有很完整的支持GBK以及Unicode4标准内的所有汉字。由此可见,各种操作系统以及各种应用软件,对中文编码标准的支持并不重视。
2 现有常用拼音首字母快速查询方案的局限性[2]
综上所述,现有的通过拼音首字母快速找到汉字的方法有的是基于操作系统,有的是基于开发环境,因此都会有一定的局限性。为解决这一问题,有些软件考虑采用GBK标准为主,因为GBK标准终究是国标,它较多的考虑到了汉字与汉语拼音的对应关系,所有汉字编码都采用拼音排序的方法,从“啊”字开始,以26个英文字母为顺序依次将所有汉字进行编码。这种方法的优点是代码量少,运行所需资源也最少,缺点是遇到多音字的时候无法识别,也无法查找汉字的全拼。
以往的研究往往到此为止,开发人员都认为能够将汉字转换成标准的拼音,就已经能够完美解决根据拼音快速查询汉字的功能了。其实不然,谈到查询,关键在如何检索;谈到检索,无法避免的要提到检索效率:资源占用、速度、重码率、以及代码编写的编码量等。为避免这些问题,有些开发者在待检索数据库中增加一个列,用于存储待检索中文的首字母(如果一张表中有多个列都需要用拼音首字母检索,那么就需要增加多个列)。这种方法的好处是,在实现具体功能的时候非常简单,因为SQL语句对此有很好的支持。例如当用户输入zh,那么对应的SQL语句为:select realname from person where realname _py like'zh%';但这种方法不仅给数据库增加了冗余,同时也不能很好的解决多音字的问题。因此急需要一个新的解决方案,在通过大量测试的情况下设计了如下的方案。
3 新方案的设计和实施
假定目标是用户在浏览器的文本框中输入联系人的拼音首字母,要求从联系人表person中将姓名realname首字母相同的查找出来给用户选择。现设计如下:
3.1 数据库的设计[3]
根据流程图设计数据库realname,其中包含三个表,存放汉字拼音编码的编码表的pinyin表、存放联系人信息的person表、存放系统词库的pinyin_word表。这三张表的简单结构如下:CREATETABLE`pinyin`(


3.2 功能的实现
其中pinyin表中存放的是GBK规范中的两万多个汉字与其拼音对照的数据,包括多音字在内。person表中存放的是联系人信息。pinyin_word表中存放的是系统中需要根据拼音首字母查询中文的所有中文与其拼音的对应表,起到词库的作用。大致实现过程为:每当用户向系统中插入一条联系人信息时,将其对应的拼音查找出来,并插入到pinyin_word表中。如果有多音字存在则生成多条记录。当用户根据拼音首字母查找时,首先到词库表中查找对应的中文,并将查找到的中文传递到用户的联系人表中查询,如果存在,则显示到WEB界面中供用户选择。考虑到效率,当重码较多的时候,比如刚输入第一个字母的时候,并不是将所有的结果都送到用户的联系人表中查找,只是将前n个结果送到联系人表中查找,例如只选取前10个结果生成一条SQL语句:select realname from person where realname='张三'or realname='张四'or...不用担心这种只选取n个结果的方法会影响到用户体验,因为当重码太多的时候,用户界面中并没有足够大的地方显示,另外用户也不会在几十个候选项中敲击几十次键盘选中想要的选项。具体流程图如下图1。
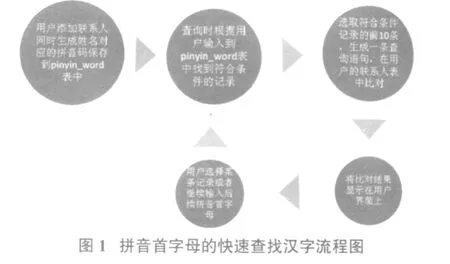
4 结语
新的解决方法与目前市场占有率比较高的搜狗、谷歌拼音输入法所采用的原理相同。汉字的数量与中文词语的数量虽然十分庞大,但是对于某个用户来说,其常用到的字、词数量是一个相对小的集合。当用户在拼音输入法中输入过一次的词,下一次就会自动显示在候选项的前几个,而可能用到的专业词语则采用词库文件的形式存储。词库文件可以放在服务器上,放在云上,这样既能脱离操作系统和开发环境又能快速更新。通过总结与实验,这种方法执行效率是最高的,可移植性是最好的,用户的体验是较完美的。该设想应用在《基于web的通讯录管理系统》的项目中,经过测试,该方案完善的解决了可快速的通过拼音首字母查询中文,为用户提供了更加友好的界面,用户反响良好。
[1]白中英.计算机组成原理[M].北京:科学出版社,2000.
[2]吕浩勇.VFP中汉字拼音首字母的获取及应用[J].计算机与现代化,2005,(12):118-119.
[3]萨师煊,王珊.数据库系统概论[M].北京:高等教育出版社, 2001.
Design and Implementation ofQuick Query Based on the First LetterofWeb
YEYu1,LITai-ning2(1.TaizhouPolytechnicCollege;2.TaizhouThankinSoftware,TaizhouJiangsu,225300,China)
Thispaperbriefly narrates the currentcondition how existing operating system and application software support the Chinese code,and analyzes the existing common fastsearch program w ith the first letter.A new idea is put forward and in-depth explanation in theory,design ideas,the specific operation is given.In thatway speed increase in searching the Chinese character w ith first letter can be realized.This idea has been certified by doing the research project of Taizhou Polytechnic Institute "Web-based ContactsManagementSystem.A new idea and a solution are provided for fastsearch program w ith the first letter.
alphabet;contacts;Chinese code;database
J292.33
B
1671-0142(2011)03-0095-03
叶钰(1977-),女,江苏泰州人,讲师,硕士,研究方向为软件开发,服务器管理.
(责任编辑 施 翔)
