基于数据挖掘的学习成绩与图书借阅关系研究①
2010-12-26刘琳
刘 琳
(华北科技学院图书馆,北京 东燕郊 101601)
基于数据挖掘的学习成绩与图书借阅关系研究①
刘 琳②
(华北科技学院图书馆,北京 东燕郊 101601)
利用数据挖掘技术,以本校基础部学生的图书借阅信息和学习成绩信息为研究对象,进行了数据预处理,运用关联规则算法挖掘了学生学习成绩和借阅图书的关系,进行分析并得出结论,认为学习成绩与借阅有关书籍的关系为正相关关系,可为管理部门对学生的评价和培养提供参考。
数据挖掘 ;关联规则 ;成绩信息;借阅信息
0 引言
随着计算机技术特别是数据库技术的迅速发展,高校图书借阅系统和成绩管理系统每年都存储了大量学生借阅和学生成绩的详细信息。图书馆的读者成千上万,他们专业不同,阅读兴趣和爱好也各不相同,如何了解各个专业学生的借阅习惯,借阅习惯与学习成绩间是否有一定关联等,均日益成为学校教学管理层必须认真思考的一个重要课题。了解并掌握了这些信息,管理人员就可以有针对性分类做学生的思想工作,从而激化学生学习兴趣和引导他们培养良好的借阅习惯,从而更好地发挥图书馆的信息资源作用。
高校学生学习主要以自学为主,学生可以根据自己的爱好或专业的需求在图书馆查阅相关的书籍。在一定程度上学生的借阅行为能够反映出其兴趣爱好,将学生的借书记录和学生成绩结合起来进行分析,用数据说话,可以探索学生成绩与借阅行为的内在联系。
本文以我校基础部 05级、06级学生的图书借阅信息和学习成绩为对象,对学生成绩和借书信息进行预处理,运用数据挖掘技术中的关联规则算法挖掘学生成绩和借阅图书的关系,进行分析并得出结论,从而把握学生的借书情况与成绩之间的影响关系,这有助于教学管理的进一步改革。对学校图书信息进行数据挖掘文献已不少[1~4],但目前未发现结合学生的学习进行数据挖掘方面的报道。
1 数据准备
数据挖掘就是从海量数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程,简单的说,数据挖掘就是从大量数据中提取或“挖掘”知识。数据预处理是数据挖掘成败的关键。
1.1 原始数据收集
本文收集的成绩数据是华北科技学院基础部05级和 06级的学生成绩。图 1所示是初始学生成绩表:
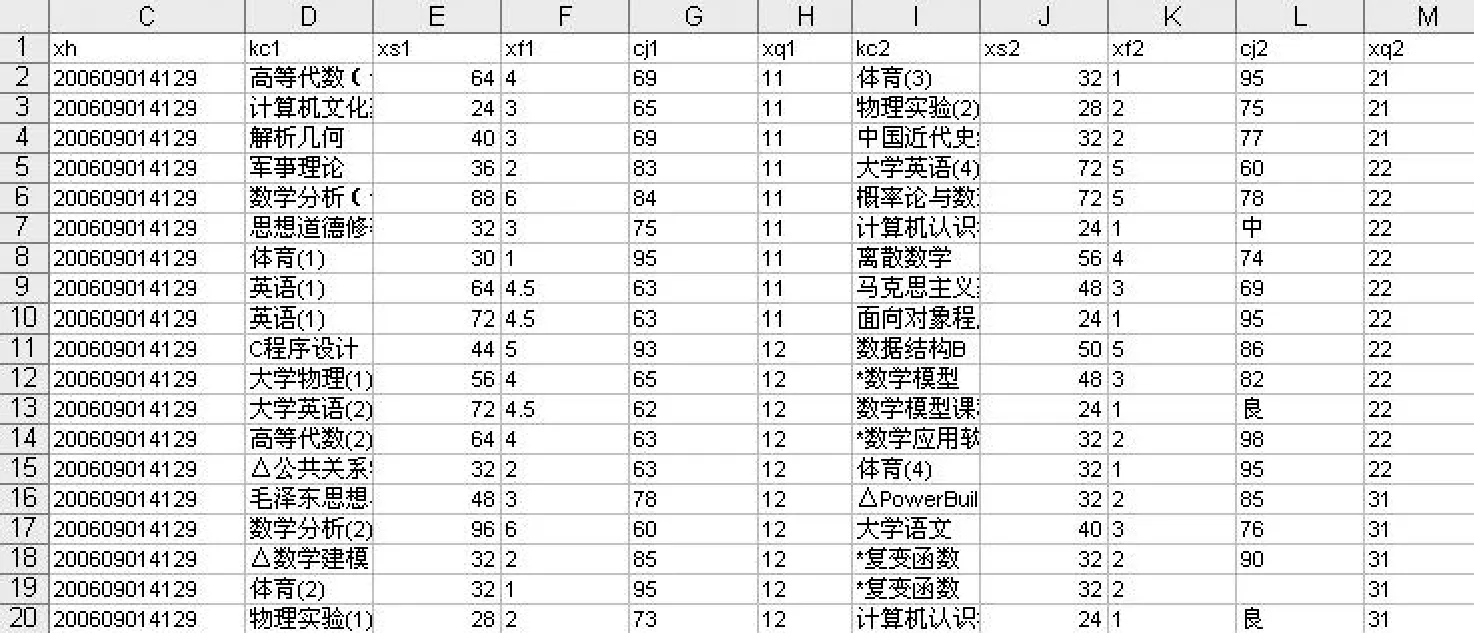
图 1 初始学生成绩表片段
借阅图书数据是华北科技学院图书借阅的历史数据,包含图书馆书目库,流通日志和读者库三个大库,各表属性很多。图 2显示的是流通日志库中的部分属性。
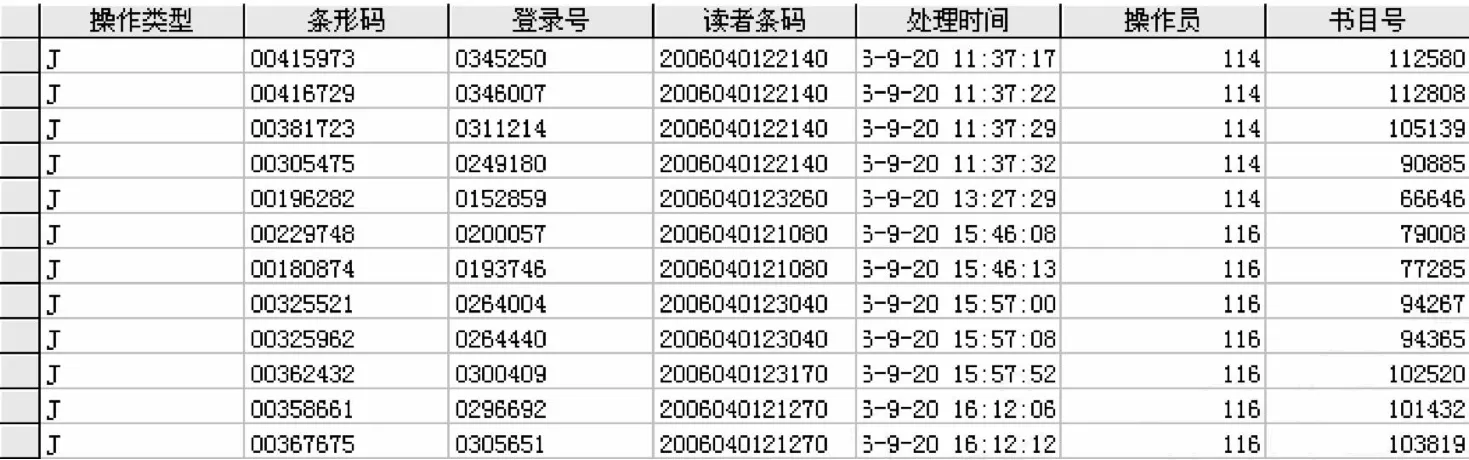
图 2 图书馆流通日志
1.2 数据预处理
数据挖掘的处理对象是大量的日常业务数据,目的是为了从这些数据中抽取一些有价值的知识或信息。原始业务数据是知识和信息提取的源泉,对于数据挖掘十分重要,然而,实际系统中的数据一般都具有不完全性、冗余性和模糊性,很少能直接满足数据挖掘算法的要求。数据预处理是数据挖掘的重要一环,而且必不可少。要使挖掘内核更有效地挖掘出知识,就必须为它提供干净、准确、简洁的数据。
在学生成绩表中,首先去掉不必要的字段,如学时、学分等,为了统一成绩科目,我们只选取必修课的成绩。另外,计算数学类、计算机类、英语类的平均成绩,并把其按照成绩的高低分成相应A、B、C、D四个等级。
再对图书借阅情况进行处理,在针对读者与图书之间的关系、图书与图书之间的关系进行了认真分析之后,删除了部分属性,使得对象之间关系更紧凑,联系更紧密。
计算每一类图书的平均借阅量,低于平均借阅量一半的借书等级为 C,一半到稍微高于平均借阅量的等级为 B,剩下的借阅等级为 A。最后将学生成绩表与借阅类型表合并成一个表,得到我们接下来进行数据挖掘所用的表,如图 3所示:

图 3 学习成绩与图书借阅数学预处理后的表
2 学习成绩与图书借阅信息数据挖掘与分析
建立了表之后就开始数据挖掘工作[5],首先在 SQL ServerManagement Studio中建立学生成绩图书数据库,然后打开 SQL ServerBusiness Intelligence Development Stduio,点文件菜单,选择新建项目,再选商业智能项目中的 Analysis Services项目。在数据源上单击右键,选择新建数据源。选择新建,找到所要挖掘的数据库,然后单击完成。
建好了数据源和数据源视图,然后开始数据挖掘。在挖掘结构选项单击右键选择新建挖掘结构。在跳出的使用何种方法定义挖掘结构对话框,选择从现有的关系数据库或数据仓库。单击下一步,弹出您要使用哪种数据挖掘技术,选择Miscrosoft关联规则。单击下一步,在可用数据源中选择 05.06成绩图书数据源。点击下一步,得到指定表类型对话框。
2.1 数学成绩与借阅数理科学和化学类书关系
分析
以数学成绩作为输入列,借阅数理科学和化学为预测列,得到图 4的关联规则。

图 4 数学成绩与借阅数理类图书之间的关联规则
数学成绩 =D的同学中,借阅数理科学和化学 =C的概率为 0.875,重要性为 0.227
数学成绩 =B的同学中,借阅数理科学和化学 =C的概率为 0.657,重要性为 0.169
数学成绩 =A的同学中,借阅数理科学和化学 =A的概率为 0.553,重要性为 0.597,
从规则中可以看出,概率与重要性不是正比关系,重要性表示概率的提升度,描述了数学成绩对借阅数理科学和化学书影响力的大小,即从某类成绩发现他借阅某类书的兴趣度,如上图,数学成绩 =A的借阅数理科学和化学 =A的重要性较高,即在数学成绩 =A的前提下,借阅数理科学和化学 =A的概率就会增高,数学成绩 =A对数借阅理科学和化学 =A的影响较大。
2.2 计算机成绩与借阅计算机类图书关系分析
以计算机成绩作为输入列,借阅工业技术为预测列,得到如下图 5的规则:
计算机成绩 =D的同学中,借阅工业技术 =C的概率为 1.000,重要性为 0.205

图 5 计算机成绩与借阅计算机图书之间的关联规则
计算机成绩 =C的同学中,借阅工业技术 =C的概率为 0.490,重要性 0.114
计算机成绩 =B的同学中,借阅工业技术 =C的概率为 0.463,重要性 0.066
计算机成绩 =A的同学中,借阅工业技术 =B的概率为 0.394,重要性 0.139
从规则中可以看到计算机成绩 =A的同学中,借阅工业技术 =A的占 39.4%,借阅工业技术 =B的占 36.4%,借阅工业技术 =C只占24.2%;而计算机成绩 =D的同学中,借阅工业技术 =C的概率为 1,可见计算机成绩不及格的同学基本上借阅计算机类书都很少。从中可以得出计算机成绩好的同学大部分借阅工业技术的书比较多,计算机成绩差的同学借阅工业技术的书相对来说就较少。
2.3 数学成绩、计算机成绩与借阅文学类书关系
分析
以数学成绩与计算机成绩作为输入列,借阅文学类为预测列,得到如下图 6规则:

图 6 数学成绩、计算机成绩与借阅文学书之间的关联规则
数学成绩 =C,计算机成绩 =B的人中,借阅文学 =C的概率为 0.889,重要性为 0.265
数学成绩 =C,计算机成绩 =C的人中,借阅文学 =A的概率为 0.458,重要性为 0.181
数学成绩 =A,计算机成绩 =B的人中,借阅文学 =A的概率为 0.429,重要性为 0.134
从规则中可以看到数学成绩 =C,计算机成绩 =B,借阅文学 =C的重要性最高,此类同学数学成绩与计算机成绩都一般,借阅文学类的书也一般;数学与计算机成绩 =C,借阅文学 =A的重要性次高,这类同学数学与计算机成绩一般,但对文学的兴趣较高,因此借阅文学的数量较高;计算机成绩 =B与数学成绩 =A,借阅文学 =A,这类同学不仅数学与计算机成绩好,对文学类也是比较感兴趣,借阅文学书也多。
我们还进行了其他方面的数据挖掘,结果不一一列举了。
3 结语
本文先对学生成绩和借阅图书的数据进行了预处理,把成绩按分数高低分为 A、B、C、D四个等级,把借阅每一类的图书量也分成 A、B、C三个等级。然后将二者合并成一个新的数据库,对该数据库进行了学习成绩和借阅书籍进行了挖掘,挖掘出了学习成绩与借阅相关书籍的关系,我们发现学生专业成绩和图书的借阅习惯存在着一定的联系,通常情况下借书比较多的学生能反映出其在学习上比较认真,借阅专业书较多的学生往往专业成绩会比较理想,如果对自己的专业感兴趣那么通常情况下借此类专业书就较多,而且发现学习成绩较好的学生学习兴趣很大,各种书籍都借阅,而学生成绩不理想的学生则学习兴趣较少,无论哪方面的书籍都借的很少。
可见,培养学生的学习兴趣是学生充分利用图书馆资源的前提。如何培养、保持和提高学生的学习兴趣主要是任课教师的责任,这与教师的个人魅力和修养有关,也与学生的个人志向爱好有关,当然如果我们图书馆在购买图书资料时多进行读者需求调查,特别是重视对学业有一定困难的学生的调查,如果每个班都发放图书资料采购建议表,也会对提高学生的学习兴趣起到积极的作用的。
[1]朱根义 .国内图书馆数据挖掘研究[J].现代情报,2009(1):128-130
[2]王伟,等 .基于数据挖掘的图书馆读者行为分析[J].现代图书情报技术,2006(1):51-54
[3]朱立红 .高校图书馆的数据挖掘技术应用于用户研究[J].图书馆杂志,2008(6):39-42
[4]张金镯 .基于数据挖掘的图书馆活跃读者研究[J].现代图书情报技术,2008(7):96-99
[5]谢邦昌 .商务智能与数据挖掘 Microsoft SQL Server应用 (第一版)[M].北京:机械工业出版社,2008
Research on the Relationship between Grades and Borrowing Books Based on Data Mining
LIU Lin
(Library ofNorth China Institute of Science and Technology,Yanjiao Beijing-East 101601)
Using data mining technology,with the libiary circulation informatin and grades informations of the students of department of basic,by using association rule algorithm,the paper explores the relationships for the data preprocessing,and analyse to draw a conclusion for the purpose of providing a useful reference for the management.
data mining;association rules;grade information;circulation infor matin
TP311
A
1672-7169(2010)04-0117-04
2010-08-27。项目基金“基于数据仓库技术的我院学生图书借阅与学习成绩信息综合分析”阶段性研究成果。
刘琳 (1971- ),女,大学毕业,图书馆馆员,研究方向为信息技术。
