Integrated Network Management System for CSL
2010-09-08
(Network Management Product Department of ZTE Corporation,Chengdu 610041,P.R.China)
With the rapid development of technology,telecom markets have grown in scale.Existing network equipment has become increasingly complex,and newly-introduced services have significantly increased the workload on such equipment.This raises the cost of network management and maintenance.It has therefore become imperative that operators monitor the state of network operation—to improve efficiency of network maintenance,to reduce costs,and to improve Quality of Service(QoS).They can do this by using an Integrated Network Management System(INMS).
INMS is a manager-of-managers on the Operations Support Systems(OSS)platform for fault management.It fulfills the following requirements:
(1)Functional Requirements
·Fault management
·Event acknowledgement/de-acknowledgement
·Severity change/non-change
·Troubleshooting tools
·Alarm notification to workflow system
·User roles
·Journal logging·Alarm notification
·Other alarm management functions,such as alarm synchronization with Element Management Systems(EMS)
(2)Integrational Requirements
·Integration with Remedy Action Request System(ARS)
·Alarm integration
1 CSL’s Demands of INMS
CSL has 25 years’best network operation experience.Its newly-built advanced network is an important asset that relies on scalable operation support systems for management.Efficient operational management is critically important to CSL.Both internal operation service level agreements and external customer-centred service level agreements depend on whether the OSS can effectively consolidate alarms from various network segments and provide meaningful,actionable messages.
Therefore,CSL required the ZTE-designed network to have a single domain Network Management System(NMS)which could manage alarms from the Core Network(CN),Radio Access Network(RAN),Value Added Services(VAS),Microwave,and Repeater.
2 ZTE’s INMS Solution
ZTE’s INMS solution delivers a platform that can aggregate,enrich,correlate,and consolidate information across various networks.Its architecture contains the following three layers:
(1)Alarm Collection Layer
Two probe types are used on this layer:
·A Simple Network Management Protocol(SNMP)Element Management System(EMS)probe that receives SNMP traps and performs SNMP operations(SNMP GET and SET)from EMSs in various network segments.
·An SNMP probe that receives SNMP traps from IP networking devices such as switches and routers.
Both probe types support Peer-to-Peer(P2P)failover functionality.They run simultaneously;one acts as the master probe,sending events to the upper layer ObjectServer(a Netcool module),while the other acts as a slave probe on standby.If the master fails,the slave will be activated.Although the slave receives heartbeats from the master,it does not forward events to the ObjectServer.If the master shuts down,the slave probe stops receiving heartbeats,and any events it receives thereafter are forwarded to the ObjectServer on behalf of the master.When the master is running again,the slave continues to receive events,but no longer sends them to the ObjectServer.
(2)Consolidation Layer
The collected alarms are forwarded to the ObjectServer for consolidation,and there they perform various event processing functions(including de-duplication and kick starting other event processing workflows).Two event workflow types can be identified on this layer:
·Trouble ticketing workflow:event data is forwarded to a Trouble Ticket System,such as Remedy Help Desk,for creating trouble tickets.Remedy Gateway is proposed for the bidirectional exchange of information.
In order to fulfill the requirement on redundancy,a secondary ObjectServer is proposed to synchronize events from the primary ObjectServer.The alarm collection probes can be configured to send alarms to an ObjectServer regardless of which ObjectServer is active.A bidirectional ObjectServer gateway performs the described synchronization.
(3)Presentation Layer
The collected and processed events are grouped,filtered,and presented in operationally meaningful ways.This is done using Webtop presentation tools such as filters,event lists,and maps.The Webtop server is configured to access both primary and secondary ObjectServers.
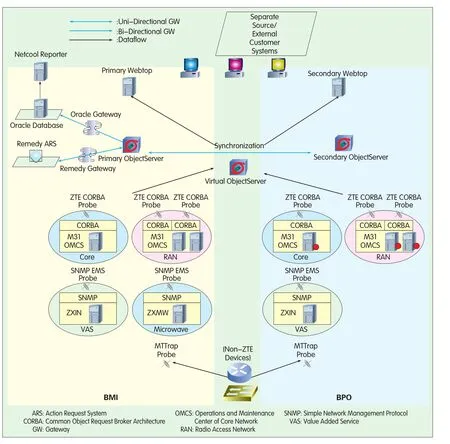
Figure 1.Architecture of ZTE’s INMS.
ZTE’s INMS is built on IBM Netcool platform for offering network availability management.Figure 1 illustrates the overall architecture of ZTE INMS,which is fully redundant above the ObjectServer(or data aggregation collection)level.The core of its design lies in two Netcool ObjectServers,one of which is the primary server residing on the site BMI,the other is the seconday server on the site BPO.Similarly,there are two sets of Netcool probes and two Netcool/Webtop servers which reside on the BMI and BPO respectively.Events flow from the probe boxes into the virtual ObjectServer(or logical ObjectServer),and probes enrich the contents based on rule files.A bidirectional object server gateway keeps the synchronization of events in the two object servers,supporting warm backup.All events are archived in an Oracle database using a high-speed Oracle gateway.The data in the Oracle database can be queried by Netcool/Reporter with historical reporting capabilities.
This solution integrates five types of EMS:core EMS,RAN EMS,VAS EMS,Microwave EMS,and Repeater EMS.Core and RAN EMS alarms are integrated by a ZTE Netcool Common Object Request Broker Architecture(CORBA)probe,and power and environment alarms are transmitted to Netcool/Omnibus through ZTE RAN EMS.ZTE VAS EMS,Microwave EMS,and Repeater EMS alarms are integrated by a ZTE SNMP EMS probe.Other IT equipment is managed by Mttrap probe.These various EMS and IT equipment alarms are handled by relevant probes and transported to Netcool/Omnibus.The automations in Netcool/Omnibus correlate the alarms.
To streamline problem management and notification processes,a Remedy gateway creates trouble tickets,and an object server automatically pages administrative personnel.
Based on CSL’s requirements,ZTE’s solution provides the following major functions:
·ZTE EMS alarm integration:ZTE EMS alarms are managed through CORBA and SNMP interfaces.
·IT device alarm integration:SNMP trap enabled IT equipment is managed through MTTrap interfaces.
·Reports:reports for CSL are created using NetNumenTMNetcool/Reporter.
·Webtop logical view:webtop monitoring views are delivered to CSL using Netcool/Weptop.
·HelpDesk integration:the Remedy gateway is used to transport Netcool/Omnibus alarms to CSL Remedy ARS helpdesk.
·Netcool/Omnibus Failover function:Netcool/Omnibus Failover is built through the Netcool/Bi-Gateway.·Migration of five existing subsystems to the new INMS platform.
3 NetNumenTMNetcool Portfolio
The NetNumenTMNetcool portfolio performs real-time management and allows complex enterprise environments to be visible.The main components are:
(1)Netcool/Webtop
Netcool/Webtop combines Netcool’s real-time fault management and service assurance capabilities with the convenience of the Internet.Authorized users can access the IT systems and services in real time,and through any browser.
Netcool/Webtop delivers graphical maps,tables,and event lists in HTML and Java to the remote operator.Netcool users can manage alerts through flexible interfaces and advanced management capabilities.The Netcool/Webtop application extends Netcool/Omnibus capabilities by adding a new set of graphical views and flexible management functions.
(2)Netcool/Omnibus
Netcool/Omnibus was specifically designed for IT service providers such as telecom operators,banks,entertainment service providers,Internet service providers,cable TV operators,and corporate enterprises.
Netcool/ObjectServer is the core component of the Netcool/Omnibus application.It is a high-speed memory-resident database that collects fault information from the network infrastructure and allows operators to see relationships between faults and the availability of network-based business services.
Netcool/Omnibus acquires fault data and status data from a variety of network devices and management environments including servers,mainframes,NT systems,UNIX applications,circuit switches,voice switches,IP routers,SNMP devices,and network management applications and frameworks.The fundamental collectors of data are lightweight code supersets called NetNumenTMNetcool Probes&Monitor.These collect fault messages from throughout the network and forward them to Netcool/ObjectServer for filtering.
Besides capturing host names and IP addresses,Netcool/Omnibus can easily accommodate other meaningful attributes in order to enrich network events and faults.This allows events to be managed not only from a network perspective but also from a business and operational perspective.
Netcool/Omnibus can be deployed quickly to achieve rapid return on investment.Its distributed architecture allows network operators to customize real-time views of whole enterprise-wide services.Based on an open client-server architecture,the Netcool suite runs with UNIX,Windows NT,and Web browsers.

In the Netcool/Omnibus application,both SNMP and non-SNMP management systems become strategic management elements.Netcool/Omnibus is commonly used as the core management desktop since it consolidates data from network management consoles,transmission infrastructure,telephony devices,data networks,Local Area Networks(LANs),Wide Area Networks(WANs),and applications.
Netcool/Omnibus consists of the following elements:
·ObjectServer:an in-memory database optimized for collecting events and designing filters and views.It provides the core processing functions for the Netcool suite.
·Probes:passive supersets of code that collect event data from more than 300 management data sources.Collected data is filtered,stored,viewed,and manipulated in the ObjectServer.
·Desktops:a suite of graphical operator tools running under X Windows,Windows NT,or Java,which provide the front end for customizing filters and service views.
·Console:the object-based screen interface that shows the status of enterprise-wide services.It uses color-coded histograms or"lava lamps"which represent a summary of event severity within each service.
·EventLists:spreadsheet-like interfaces into NetMumenTMNetcool/ObjectServer event data that show events color-coded according to severity.This allows access to useful information for troubleshooting each event.
·FilterBuilder:a desktop interface based on Boolean correlation tools that allows operators to associate collected event data with the availability of business services.
·ViewBuilder:point-and-click desktop equipment that allows operators to design personalized views of events and services,supporting customization of service views and EventLists.
·Gateways:bidirectional interfaces that allow ZTE Netcool/ObjectServer data to be shared with other ObjectServers,Relational Database Management System(RDBMS)archives(such as Oracle,Sybase,Informix),or trouble-ticketing applications(such as Remedy AR SystemTM,Peregrine Service CenterTM,Clarify ClearSupportTM,and ODBC).
4 Conclusions
ZTE’s NetNumenTMINMS provides a solid,modular,distributed architecture,and an open development environment.It fulfills the required off-the-shelf integrated network management.It can be easily integrated with multiple third-party systems.ZTE’s INMS is designed according to the principle of‘bottom to top’.It is characterized by its high user-orientation,telecom-level and multi-platforms.It can manage multiple network elements quickly,flexibly,conveniently,and economically according to actual needs.This provides operators with various social and economic benefits.Moreover,it has flexible scalability,which enables smooth upgrade and minimal impact on the existing system when expanding system capacity or adding new network devices.
In the CSL project,ZTE’s INMS aggregates alarms from different domains and provides unified visualization and presentation for operators.With centralized management of topology,faults and reports,INMS can monitor the running status of overall networks in real-time and on a single console.In this way,CAPEX and OPEX can be reduced.
