基于扩展隐层BP网络的信息可视化聚类的研究
2010-08-23郭绍翠
杨 旭,郭绍翠
YANG Xu1, GUO Shao-cui2
(1. 烟台职业学院 信息工程系,烟台 264670;2. 烟台职业学院 开放教育学院,烟台 264670)
0 引言
信息可视化(Information Visualization)是当前计算机科学的一个重要研究方向,它是利用计算机对抽象信息进行直观地表示,以利于快速检索信息和增强认知能力。信息可视化最早出现在1989年美国计算机学会组织的重要国际会议“用户界面软件与技术(UIST)”[1]的报告中,重点研究如何把抽象信息交互地、可视地表示出来。信息可视化的定义为:对抽象信息使用计算机支持的、交互的、可视化的表示形式以增强认知能力。信息可视化技术将为人们发现规律、增强认知、辅助决策、解释现象提供强有力的工具。
20世纪80年代以来,随着计算机技术、存储技术和网络技术的发展,人们可以掌握的信息类型越来越多,信息结构越来越复杂、信息更新越来越快,信息规模也越来越大,给人们获取信息、理解信息、掌握信息带来沉重负担。因此,对于当前的可视化技术,海量多维信息与有限的屏幕空间已成为主要矛盾。
为了解决这一问题,当前的可视化技术如平行坐标系(parallel coordinates)[2]等主要采用聚类的方法,通过预先对数据进行重新组织,以减少需要绘制的图形标记。常用的聚类算法一般都是基于欧氏距离的,以k-means算法及其变形为主,通过计算数据之间的“距离” ,将相近或者相似的数据归为一类,并以统一的图形表示。这种算法对处理数据量不大的简单数据时较为有效,在应对复杂的海量信息时就显得有些差强人意。
为了加快可视化的聚类过程,本文将扩展BP网络用于复杂信息的聚类中,代替传统的基于欧氏距离的聚类算法。该方法利用多维信息和其聚类结果构造相应的BP网络模型,用已知聚类结果的多维信息作为样本对算法进行验证。实验结果表明,该方法简单高效,可以较为准确和快速的对数据进行分类。
1 扩展隐层BP网络模型及其工作原理
扩展隐层的BP网络模型及其训练算法[3]是对传统三层BP网络模型的改进与扩展,其目的是在不改变神经网络表达能力的基础上,提高网络的训练精度与预测能力,同时增加网络的灵活性,对外提供一个接口,方便与其它训练算法相结合,发挥多种算法的优势。
1.1 扩展隐层的BP网络
Funahashi于1989年证明了这样的一个定理:若输入层和输出层采用线性激活函数,隐层采用Sigmoid激活函数,则三层结构的BP网络能够以任意精度逼近任何有理函数。因此,在实际的应用中,一般采用三层结构的BP网络,其输入层和输出层采用线性激活函数,隐层采用S(Sigmoid)型激活函数。
扩展BP网络模型是对原传统三层网络结构一种扩展,其构造方法是在三层BP网络的基础上扩展一个新的隐层,称其为辅助隐层。该隐层在原隐层之后添加,隐节点数与原隐层节点数相同,相当于对原隐层的一种复制。辅助隐层的激活函数采用线性函数,出于训练效率的考虑忽略辅助隐层的阈值。扩展后的BP网络的模型如图1所示。

图1 扩展隐层的BP网络模型
1.2 扩展隐层BP网络工作原理
扩展隐层的BP网络训练算法如下:
1)对原始三层结构的BP网络进行训练,确定权值,阈值等网络参数。
2)动态扩展一个隐层,构造扩展隐层的BP网络。利用蚁群算法对新增权值进行训练,并确定其最终取值[4,5]。
设新增加了m个权值Pi,(1≤i≤m),Pi有N个随机值,形成集合Ipi,h为蚂蚁数目,Djk(Ipi)表示集合Ipi(1≤i≤m)中第j个元素Pj(Ipi)的信息量,Q(k)表示信息增量。则新增权值的具体训练步骤如下:
1)初始化,令t和循环次数初始值Nc为零。设置最大循环次数Ncmax,令每个集合中每个元素的信息量Dj(Ipi)=C,且ΔDj(Ipi)=0,将全部蚂蚁置于蚁巢。
2)启动所有蚂蚁,针对Ipi,蚂蚁k(k=1,2…h)根据下式计算状态转移概率:
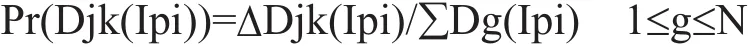
3)重复(2),直到蚁群全部到达食物源。
4)令t=t+m,Nc=Nc+1,利用蚂蚁选择的权值计算神经网络的输出值和差值,记录当前最优解。根据以下公式更新各元素的信息量:

5)如果蚂蚁收敛到一条路径或Nc≥Ncmax,则算法结束,否则转2)。
上述公式中,Q(k)表示信息强度是随时间变化的,Q(k)=α*Q(k-1), 0<α<1在开始应设置较小值,然后逐渐增大,这样可以保证蚁群算法在开始时有更多机会搜索其它路径,防止早熟;逐步增加Q值,拉开各元素间的信息量差异,加快搜索速度,同时设置最大值Qmax,防止Q的取值无限增大。挥发系数ρ(t)也是一个可变量,ρ(t)=β*ρ(t-1), 1<β,开始将其设置一个较小值,随着训练频数的增加,ρ(t)值也相应变大,进一步拉开各元素之间的差异,加快训练速度,与Q值一样,也应为其设置一个上限值[6,7]。这两个变量一个体现原始信息的重要性,一个体现蚂蚁积累信息的重要性。
2 基于扩展BP网络的信息聚类
扩展BP网络需要与实际的应用相结合,根据具体情况构造相应的网络模型。按照上一章节中的算法,首先根据聚类特征构造扩展BP网络模型,然后选取部分具有代表性的海量信息生成样本,用训练样本对该模型进行训练,使之具备聚类能力,最后用该模型对海量信息进行聚类。基于BP网络的聚类与传统的基于欧氏距离的聚类算法相比,具有明显的区别和优势。传统算法是一种反复迭代的过程,它根据数据之间的“距离”,将相似或者相近的数据归为一类,这种算法对于简单小型数据集比较有效。然而,可视化技术为了提示信息背后隐藏的关系、规律和模式,要处理的往往是那些复杂的大型数据集。传统的在对这些数据反复迭代过程中,会消耗大量的时间,影响可视化技术的效率。而本文的方法,是对海量信息中的少量具有代表性的信息进行学习,具备分类能力后再对剩余信息分类,避免了复杂的迭代过程,节省了大量的时间。数据集越大,其高效性越明显。
2.1 构造BP网络模型
可视化的聚类过程中,一般都是用户先确定聚类粒度,然后根据需要确定最终的数据集要被分成多少类。影响最终结果的因素就是多维信息本身,假设数据集包含N维信息,则这N维信息都是影响分类结果的主要因素。即N维信息为BP网络的输入,单条信息所属类别为最终的输出。由此可以构造相应的BP网络模型,见图2所示。

图2 用于可视聚类的BP模型
2.2 生成训练样本
训练样本是影响BP网络分类能力的重要因素,选取的合理性直接影响了BP网络最终的预测能力。训练样本是数据集的一部分,必须具有高度的概括性,能够代表所有数据的特征。因此,合理选取训练样本是一件比较困难的事情,训练样本选取过多,不会影响网络的分类能力,但是影响训练效率;样本选取过少,则会使网络无法学习数据集的所有特征,影响最终的分类能力。
本文采取随机选取的方法确定训练样本,即在数据集中随机选择全部数据的1/7~1/5作为训练样本。这部分数据的分类情况事先是不知道的,需要加以确定。为了方便实验,我们采用传统的k-means方法对其分类。当然,聚类算法并不局限于k-means,可以用其它适合于可视化技术的聚类方法代替。
k-means 算法的主要思想如下:首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数。 k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。使用k-means算法对随机选取的数据进行分类,我们最终可以得到用于训练扩展BP网络的样本。另外,需要保存当前的分类结果,这些分类信息是后续工作的基础。
2.3 训练
本文采用扩展BP网络模型对可视化数据进行聚类。按照前面的介绍,其训练过程大体分为两个步骤,即初次训练和再次训练,其本质是两种训练算法的交叉使用,发挥每种算法的优势。
第一步是用传统的训练算法对三层结构的BP网络进行训练[8,9]。设定训练步数,目标精度,训练函数(trainrp),激活函数等训练参数,对BP网络进行初次训练。第二步是在三层结构的基础上,扩展一个新的隐层,并使用线性激活函数,用蚁群算法对新增权值进行训练,确定具体值。这一过程需要事先设定最大循环数,蚂蚁数,初始信息量,信息增量,权值范围,挥发系统等参数,然后按照2.2章节中的算法对扩展BP网络进行训练。经过两种算法的交叉训练后,扩展BP网络已经较好的学习了多维数据集中的潜在关系和规律,具备了对整个数据集分类的能力。
扩展BP网络的训练过程看似复杂,涉及两种算法,两次训练,训练过程也要多次迭代。但与传统的k-means等聚类算法相比,还是具有一定的优势:
1)传统的算法思想简单,但计算复杂,需要对数据集的所有数据进行迭代操作,当数据复杂,维数多,数据量较大时,聚类时间明显变长,效率严重下降。而基于扩展BP网络的聚类算法则仅对数据集的部分样本进行训练,虽然也有迭代过程,但由于训练样本数据量小,网络结构相对简单,整体的训练时间并不长,效率较高。
2)传统算法的优势在于小型数据集,在处理规模较小的信息时,优势明显。而本文的聚类算法则适用于大型的数据集,通过对部分样本进行学习就可以具备分类能力,可以直接计算后续样本的所属分类,避免了繁琐的迭代过程。
当然,本文算法也有自身的不足之处,就是训练样本不好选取。K-means直接对全部数据分类,错分问题不严重。而基于BP网络的聚类算法如果训练样本选取不当,则无法学习数据集的全部特征,无法正确分类,容易产生错分现象。
2.4 对数据集分类
扩展BP网络经过训练后会具备分类能力,可以直接用于可视化数据集的分类。随着信息技术的发展,人们收集信息的能力越来越强,手中掌握的信息量也越来越大,迫切需要有效的信息处理方法。本文使用的扩展BP网络可以有效的解决这一问题,快速对海量复杂数据集进行分类。
但是,在分类过程中,由于BP网络本身具有一些有确定因素,预测结果有可能产生一些异常值,比如,分类结果不在给定范围之内。虽然这种情况较少,但也会给实际的分类带来不利影响。有两种方法可以解决这一问题,一种是改进BP网络本身,使其具有一定的纠错能力,当输出异常时及时纠正。另外一种是利用传统聚类方法对这些异常信息直接分类。
本文采用了第二种方法,因为这种方法相对于第一种算法更为准确,只是会牺牲少许时间。此种方法的工作原理是:在用k-means算法对数据集的部分数据分类,产生训练样本的时候,我们已经保存相应的分类信息。可以以此为基础,利用k-means算法直接对少量异常信息重新分类,由此去除异常现象。
3 实验
本文设计了一组实验,检验扩展BP网络在可视化数据分类中的可行性。很多学者在研究可视化技术时,为了方便实验,专门整理了一组数据作为公用测试集。本文选取了其中一组数据集UVW,用该数据集检验本文算法的正确性,该数据集共有6维信息,149769条数据,这6维信息分别是X,Y,Z,U,V,W。鉴于篇幅所限,仅列举部分示例数据,见表1。为了方便与传统算法对比,本文同时使用k-means算法与扩展BP网络两种方法对该数据集分类,并用数据对比了实验结果。
首先,用k-means算法对这149769条数据直接分类,保存分类结果,记录消耗时间,以方便对比。在此过程中产生的聚类结果可以作为后续BP网络的检验样本。

表1 多维信息训练样本(部分)
接下来,根据UVW数据集的特点,构造相应的扩展BP网络模型。该数据集共有6维,其相应的网络模型如图,有6个输入节点,分别对应每维数据,隐层节点根据经验设置为5,输出节点为1,代表最终分类结果。选取数据集中20000条数据,使用k-means算法对这些数据分类生成训练样本。用传统的训练算法对三层BP网络进行训练,实验环境和参数设置如下:本次实验的硬件环境为:CPU:P42.0,内存:1G,软件环境为Matlab 6.5。Matlab的参数设置为:隐层传递函数采用tansig ,输出层传递函数采用purelin ,训练函数采用trainrp,训练步数为1000,目标精度为0.001。训练完成后训练精度达到0.00074420。
在此基础上,扩展一个隐层,用蚁群算法对该BP网络进行二次训练,确定新增权值,提高训练精度。蚁群算法的参数设置如下:Q(0)=40,Qmax=80,N=20, ρ(0)=0.15,h=50,ρma x=0.50,Pi∈[-0.5,0.5], Ncmax=100,Dj(Ipi)=40,1≤i≤u, 1≤j≤20。以上参数,Q,Qmax,N,h,Ncmax,Dj(Ipi)是根据问题规模随机选取的,选取依据是训练时间不能过长;在蚁群算法中,参数ρmax一般建议取0.5。BP网络经过初次训练,与最优解的差距已经缩小,过渡矩阵与单位阵较为接近,因此, 的取值范围可以限定在一个较小的范围内,本文取Pi∈[-0.5,0.5];利用上述参数对扩展BP网络模型进行训练,训练结束后,对数据集中的所有检验样本进行分类,并保存分类结果,统计时间。最后,对于产生的那些异常数据,即分类结果超出给定范围的数据,本文使用传统算法重新定位其所属类别,消除异常。
两种聚类方法的最终结果如表2所示,本文从实验数据数量,消耗时间,出现异常(分类结果超出给定范围),错分数据(分类不正确),和错分率几个方面作了对比。从实验结果中可知,基于扩展隐层BP网络的聚类算法相对于传统算法具有省时高效的特点,特别适用于大规模数据集,数据集越大,效果越明显。但由于BP网络本身具有一些不确定因素,导致该方法存在异常数据和错分现象,但相对于庞大的数据量,错分率还是相对较低的。由于可视化技术本身目的是为了揭示规律,观察整体趋势,并不关心单条数据,因此,本文提出的基于扩展BP网络的可视化聚类算法是高效的,可行的。

表2 实验对比结果
4 结论
实验证明,本文介绍的基于扩展BP网络的可视化信息聚类方法是完全可行的。这种方法适合于大型的可视化数据多维数据集。相对于传统的聚类文献,它的效率更高,尤其是对海量信息的聚类,通过对少量数据的学习,就具备了分类能力,节省了大量时间。同时,本文也考虑到了异常的存在,用传统k-means算法消除了该现象。本文算法也存在需要改进的地方,如样本选取问题,本文采用了随机选取的办法,但该方法不能保证所选数据可以覆盖数据集的所有分类特征,这也是本文要进一步研究的工作。
[1]Robertson G,Card SK,Mackinlay JD.The cognitive coprocessor architecture for interactive user interfaces.Proceedings of UIST'89,ACM Symposium on User Interface Software and Technology 1989,10-18.
[2]A.Inselberg and B. Dimsdale. Parallel coordinates:A tool for visualizing multidimensional geometry.Proc.of Visualization'90, pages 361-78,1990.
[3]刘新平,唐磊,金有海.扩展隐层的误差反传训练算法研究[J].计算机集成制造系统,2008,14(11):2284-2288.
[4]洪炳熔,金飞虎,高庆吉,基于蚁群算法的多层前馈神经网络[J].哈尔滨工业大学学报,2003,35(7):323-825.
[5]Colorni A,Dorigo M,Maniezzo V,et al. Distributed optimization by ant colonies[A].Proceedings of ECAL91(European Conference on Artificial Life)[C].Paris,France:1991:134-142.
[6]陆崚,沈洁,秦玲.蚁群算法求解连续空间优化问题的一种方法[J].软件学报,2002,13(12):2314-2323.
[7]黄翰,郝志峰,吴春国,秦勇.蚁群算法的收敛速度分析[J].计算机学报,2007,30(8):1344-1353.
[8]C.Zhang,W.Wu,X.H.Chen,Y.Xiong.Convergence of BP algorithm for product unit neural networks with exponential weights[J].Neurocomputing.2008,12,72:513-520.
[9]W.Wu,H.M.Shao,D.Qu,Strong convergence for gradient methods for BP networks training,in:Proceedings of the International Conference on Neural Networks and Brains,2005:332-334.
