基于PageRank值的文本相似度改进模型
2010-08-07熊才权田浩
熊才权 田浩
湖北工业大学计算机学院 湖北 430068
0 引言
在Google模式中,PageRank值的计算和向量空间模型的计算是相互独立的,在向量空间模型的计算中也没有考虑到 PageRank值本身所包含的信息含义。本文在计算文本相似度时结合 PageRank值所包含的信息提出在计算文本相似度时先以 PageRank值的大小作为特征选择的条件,然后在VSM模型中考虑类别信息以提高检索的质量。
1 基于PageRank值的VSM改进模型
对文本进行分类是一个比较复杂的问题,文本自动分类是信息检索与数据挖掘领域的研究热点与核心技术,而基于机器学习的文本分类技术的相关研究已经取得较大进展。本文首先简单的把具有相同 PageRank值的网页归为同一类,然后在计算相似度的过程中考虑这种分类的影响,并区分不同类别间的信息差异,最终得到更为有效的检索结果。如果把具有相同 PageRank值的网页归为同一类,就可以把所有网页文本根据其重要性简单划分为11种类别。在下载系统中对网络爬虫添加部分代码使其根据 PageRank值的大小对网页分类存储可以简单实现这种初步的分类。
1.1 词频的统计方法
在文本分类中词频一般是基于自然语言的,经过文本分类后得到的词条可以认为是计算机可识别的机器语言,在真实生活中使用频率高的词条可能在机器语言中使用率并不高。在考虑文本分类的同时为了保证相似度计算的一致性,可以对机器语言的文本频率进行统计以在文本相似度计算中使用。
词条频率的统计过程如下:
(1)对所有分类后的页面提取特征词;
(2)统计各个类别Ci的文本总数Mi和包含词条t的文档数mi;
(3)计算词条t在各个类别的各个文本中的词频,公式如下:
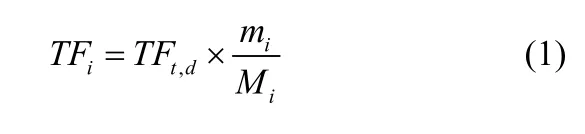
在词条频率的统计过程中首先需要提取特征词,特征词的提取与用户可能的检索词是相关的。例如“搜索引擎”、“天安门”等都可能是用户潜在的检索词,所以必须做为特征词进行统计。本文提供了包含 1370个检索内容的检索库,所有检索库中的词都作为特征词进行统计。然而,在搜索引擎中进行的每一次检索都对词条进行一次频率统计是不现实的,即使根据本文所提供的检索库所得到的最终统计结果也是不全面的。但是,由 PageRank算法可知,网页的连接是基于词条的,所以词条频率的变化与 PageRank值的传递具有一致性,在 PageRank值更新的时期内,基于网络的词条频率可认为保持不变。可以在计算 PageRank值的同时进行词条频率的统计计算,也可以改进 PageRank算法,利用PageRank算法计算出词条频率。
1.2 改进的IDF方法
一个词条如果在一个类别的文档中频率较高,则说明该词条能够很好的代表这个类别的文本特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别其它类文档。例如,计算机类的文本中“CPU”会出现在许多文档中,“CPU”应该选来作为计算机类文本的特征词以区别其它类文档。
根据上述原理提出改进的IDF方法如下:
设总的文档数为 N,包含词条t的文档数为 n,其中某一类Ci中包含词条t的文档数为mi,除Ci类外,包含词条t的文档数为k,则t在Ci类中的IDFi值为:
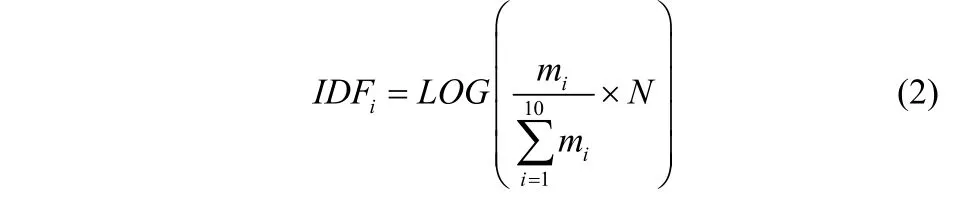
显然,IDFi随mi增大而增大,随k增大而减小。如果在某一类Ci中包含词条t的文档数量大,而在其它类中包含词条t的文档数量小的话,则t能够代表Ci类的文本的特征,具有很好的类别区分能力。
1.3 改进的VSM模型
综上所述,在对搜索引擎中文本相似度计算的方法和过程进行改进后提出“基于PageRank值的VSM改进模型”,其文本相似度的计算过程如下:
(1)对所有下载的页面根据PageRank值的大小进行分类,并统计特征词条在各个类别中的词频TFi;
(2)由改进的IDF方法计算词条在各个类别中的IDFi;
(3)计算该特征项t在文本d中的重要程度Wt,d;
(4)计算文本d和查询式q的相似度sim(q,d);其公式如下:
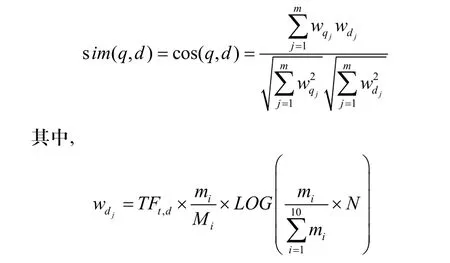
(5)根据相似度的大小生成相似度排序列表。其中,具有相同相似度的页面PageRank值大的排在前面。
为了验证改进后的效果,需对原模型和改进后的模型所生成的结果进行比较。假设:由原模型(VSM)得到的排序为:{A1,A2,……,An};由改进后的模型(BPVSM)得到的排序为:{B1,B2,……,Bn}。
定义1:相关:若检索结果页面Ai或Bi中包含检索信息则Ai或Bi相关,否则Ai或Bi不相关。
定义2:异点:在两次排序中若Ai≠Bi则Ai和Bi为异点。
定义 3:优异点:在两次排序中∃Ai≠Bi,若 Ai相关而Bi不相关则Ai为优异点,若Bi相关而Ai不相关则Bi为优异点;在两次排序中∃Ai=Bj,若i>j则Ai为优异点,若i<j则Bj为优异点。
2 实验结果及分析
网络上的数据是极其巨大的,对所有网络数据进行完备的实验分析是困难的。整个互连网是由一个个网络构成的,其中任意一个网络都可以认为是一个较小的互连网。例如:分别对中国教育网和对中国电信网进行实验所得到的结果几乎没有区别。所以,适当缩小实验范围不会影响最终的实验结果。在本实验中,限制网络蜘蛛的爬取范围是在中国教育网内(即网址后部分为.edu.cn)。但是即使仅对中国教育网进行全面的分析计算也是一个巨大的工程,为了证明改进后的算法对检索结果的影响可进行验证性实验,其过程如下:
首先,精选检索内容,生成包含了 1370个检索条目的检索内容库,然后分别在Google中检索,并用网络蜘蛛爬取检索结果页面。
其次,根据改进后的模型对检索结果进行再排序。由于在搜索引擎中一个页面显示 10个结果,而用户一般难以容忍翻看到 10以后的结果,所以尽量避免对后面的结果页面进行分析计算。在实验中,只对结果页面的前1/3进行了分析计算(检索结果少于 300则全部进行分析计算),最终只显示前10个页面的排序。
最后,分别统计两次排序前十个页中所包含的相关页面的数目,比较两次排序的相关性;分别统计两次排序的优异点,比较两次排序的优异性;并用 MATLAB对统计结果进行模拟得到仿真图。
在实验中,检索内容库主要分为复杂检索和简单检索,复杂检索为可以确定具体结果的检索,例如检索内容为“毛泽东 开国典礼 语录”为复杂检索,而“毛泽东 语录”为简单检索。同时考虑到部分新词如“绿领”并未被词典收录,检索内容库具有 37条包含新词的检索如“绿领 含义”。检索内容库概要见表1。

表1 检索内容库
经过对实验数据统计分析发现改进后的模型在提高检索的准确率上比原模型更加有效,在对包含新词的检索中贡献更加明显。最终统计结果见表2。
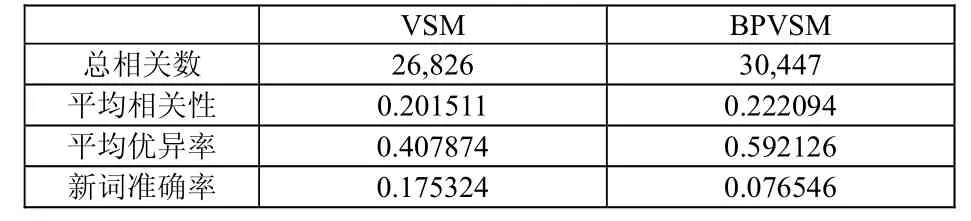
表2 两次排序的效率比较
对 1370次排序的相关性进行模拟,发现两条相关性曲线相互交织在一起,其中BPVSM的大部分略高于VSM;见图 1(纵坐标表示相关页面的数目,横坐标表示按照相关页面的数目的大小排列的1370次统计)。

图1 相关性统计图
对相关数(其范围为0-100)进行逆向统计的模拟,发现两条曲线在11%和20%左右有较大的起伏;BPVSM在11%和20%有两次波峰,而VSM仅在20%有一次波峰。见图2(横坐标为页面相关数,纵坐标表示具有某个相关数的统计次数)。

图2 相关性逆向统计图
对1370次排序的优异点统计进行模拟,发现VSM曲线有少量的奇异点落在BPVSM曲线的上方,忽略少量的奇异点后可认为BPVSM曲线在VSM曲线的上方。见图 3(纵坐标表示优异点数目,横坐标为按照优异点数目排序的 1370次统计)。

图3 优异点统计图
综上所述,实验结果表明:
(1)两种模型检索结果的查准率比较接近,但改进后的模型查准率更高;
(2)两次排序的查准率在7%-35%之间,在11%和20%左右达到最大概率;
(3)改进后的模型可以明显提高对新词的查准率;
(4)改进后的模型对前 100个网页的可信度提高了约1.45174倍。
3 结束语
相似度的计算与排序是搜索引擎的一个重要部分,提高相似度的计算与排序的效率和质量对提高整个搜索引擎的质量具有重大的意义。本文基于搜索引擎的文本检索部分提出了基于 PageRank值的文本相似度改进模型,通过模拟实验表明改进后的模型可以提高检索的准确率,在对新词的检索中更加明显。
基于 PageRank值统计词频,词频的统计必须保持与PageRank值的更新同步,这必然会增加整个搜索引擎的工作量;其次,改进后的模型依然存在奇异点(即完全不相关的页面却获得了很高的相似度),若在改进后的模型中考虑消去产生奇异点的原因可以提高模型的稳定性。
[1] PAGE.L,BRIN.S.The anatomy of a large scalehyper textual Web search engine [J].Computer Networks and ISDN Systems.1998.
[2] PAGE.L,BRIN.S,MOTWAN.R.WINOGRAD.T. The PageRank citation Ranking:Bringing Order to the Web[J]. Stanford Digital Library Technologies Project.1998.
[3] MATTEW.R,PEDRO.D.The intelligent surfer: Probabilistic combination of link and content information in PageRank[J].Neural Information Processing Systems.2002.
[4] SALTON G,WONG A,YANG C.A Vector SpaceModel for Automatic Indexing[J]. Comm-unications of ACM.1975.
[5] YANG Y.An Evaluation of Statistical Approaches to Text Categorization[J].Information Retrieval.1999.
[6] 梁斌.走进搜索引擎[M].北京:电子工业出版社.2007.
[7] 苏金树,张博锋,徐昕.基于机器学习的文本分类技术研究进展软件学报[J].2006.
