基于高斯混合模型的生物医学领域双语句子对齐
2010-07-18陈相林鸿飞杨志豪
陈相,林鸿飞,杨志豪
(大连理工大学信息检索研究室,辽宁大连116024)
本文使用高斯混合模型作为分类工具,它通过高斯成分描述独立的输出特征和高斯混合模型拟合概率密度函数来实现分类功能。
假设λc为给定的一个类模型,则该类特征向量X的观察概率为:
1 引言
双语语料库是包含有两种不同语言之间对照翻译的信息,在数据驱动的机器翻译、计算机辅助翻译以及跨语言信息检索等领域中具有很高的研究和使用价值。在双语语料库的双语对齐上,根据对齐的粒度,可以将对齐分为段落级、句子级、短语级和单词级。而高精度的句子级别的双语语料库可以改进自然语言处理系统整体性能。在句子级别的双语语料库的基础上,可以进行进一步开展其他比较深入的研究,比如短语级和单词级的双语对齐和双语术语提取。对于大规模的双语语料库,手工对齐是很不现实的,人们一直在研究使用计算机自动的句子对齐技术。
在各种句子对齐技术中,基于长度的方法是最早出现的。基于长度的方法又称为基于统计的方法,其基本思想是长句子的译文也是长句子,短句子的译文也是短句子,它们的长度满足一定的比例关系。句子的长度可以以句子的字符长度度量[1],也可以以句子的单词个数度量[2],这些方法在英法双语的Canadian Hansards语料达到了很好的对齐效果。但是在具有噪音的语料上[3],对齐的正确率很不理想,将此方法用于无噪音的英汉 Hong Kong Hansards语料,也只达到了 86.4%的准确率[4]。张艳[5]使用长度扩展的方法进行句子对齐,得到了不错的结果。将同源词信息和基于长度的方法相结合,对于提高对齐精度有一定的帮助。但是由于汉语和英语不属于同一语系,所以词汇信息的局限性很大。另外一种方法是基于词典的方法[6]。然而由于自然语言翻译的灵活性和双语词典的有限性,词典义项对真实文本的覆盖率很低,仅用双语词典进行机械匹配来对齐无法达到满意的效果[7]。而且基于词典的方法计算相当复杂,需要大量的平行文本和语言资源。将基于词典的方法与基于长度的方法相结合,可以在一定程度上提高准确率。Wu[4]将基于长度的方法和基于词典的方法相结合,用于翻译严格规范、没有任何噪音信息的Hong Kong H ansards语料,将单纯运用基于长度的方法的准确率从86.4%提高到92.1%。M ohamed[8]将句子对齐问题看作一个对齐模式的分类问题,并且考虑了英语和阿拉伯语对译符号间句子的长度信息,降低了对齐的错误率。以上这些方法在同语系的两种语言、翻译规范、没有噪音的语料上获得了不错的对齐结果。但是在翻译规则不严格、风格不统一、噪音信息大的面向生物医学领域的摘要语料中,这些方法无法反映领域特征,对齐效果也明显下降。同时,由于生物医学领域双语资源较难获得,在较少的训练语料上以上方法很难达到预期的对齐效果。
迁移学习就是一种利用已获得的知识促进新的学习的一种思想。它作为机器学习领域的一个重要课题,近年来许多研究者做了大量的工作[9-11]。特别是在分类任务中,当标注好的训练数据严重不足或者训练数据和测试数据分布不一致时,可以利用迁移学习来对模型或者参数进行训练。DaumeIII和Marcu[12]曾利用一个特殊的高斯模型对域迁移学习问题进行了研究。而Wu和Dietterich[13]在进行图像分类任务时提出了一个基于迁移学习思想的图像分类算法,其训练数据包括少量的标记数据和大量的低质量的辅助数据,取得了较好的结果。
本文采用分类的思想对生物医学文献英汉句子进行对齐,首先将句子对齐模式分成八个类别,即为(1∶0)、(0∶1)、(1∶1)、(1∶2)、(2∶1)、(2∶2)、(3∶1)、(1∶3),它们基本覆盖了对齐的各种情况。利用高斯混合模型对三个句对组成的双语文本块进行分类,分类过程中,系统将不属于以上八个分类的情况认为是对齐错误。由于无法获得大量生物医学领域双语训练语料,在进行模型参数训练时,我们引入迁移学习思想,将规范并且无噪音的《新概念英语》双语文本与生物医学双语语料相结合对句子的长度特征进行训练,获得了较好的对齐正确率。
2 分类思想处理句子对齐任务
本文首先对于句子对齐的模式进行分类,对于句子对齐,根据对齐模式有(1∶0)表示一个汉语句子无法找到互译的英语句子;(0∶1)表示一个英语句子无法找到互译的汉语句子;以此类推,其他匹配模式还有(1∶1)、(1∶2)、(2∶1)、(2∶2)、(3∶1)、(1∶3)。除以上八种以外的对齐模式极少,所以这八种模式基本覆盖了句子对齐的各种情况,在对齐过程中如果出现其他对齐模式,系统认为是对齐错误。根据以上分析,我们可以把句子对齐看作一个分类问题,在句子对齐过程中共有八个对齐模式分类。
对于双语句子文本,最重要的特征就是句子的长度。Gale和Church使用此方法对加拿大英法双语的Canadian H ansards语料达到了很好的对齐效果。这种方法的思想基础就是长句子的译文是长句子、短句子的译文也是短句子。句子的长度特征是所有句子对齐技术首要考虑的双语句子特征。
另外一个非常重要的双语文本特征就是锚信息。锚信息可以分为狭隘义上的锚信息和广义上的锚信息。狭义锚信息主要是指标点、数字、特殊符号以及变量的单位。比如,无论是英语文本还是汉语文本,互译的文本中表示比例关系都使用“%”,中文句子的结束标志是“。”,对应的英文句子的结束标志为“.”。如图1所示。

图1 锚信息
上例中符号匹配情况如表1所示。

表1 锚信息匹配表
在真实语料中,存在某些符号或者标点在互译的句子中无法找到匹配的符号。我们将锚信息对齐模式分为以下三类[17]:
(1∶1):一个汉语句子中的符号与互译的英语句子中的一个符号对应;
(1∶0):一个汉语句子中的符号在互译的英语句子中无法找到对应的符号;
(0∶1):一个英语句子中的符号在互译的汉语句子中无法找到对应的符号。
广义锚信息除以上符号类锚信息以外,还包括双语摘要的结构化信息。在生物医学文献的双语摘要中,经常出现这样的结构化摘要段落,如图2所示。

图2 结构锚信息
如上例中,“目的”固定翻译成“objective”或者“aim” ;“方法”固定翻译为“method” ;“结果”固定翻译为“result”;“结论”固定翻译为“conclusion”。这些摘要结构用语自然地将摘要段落分为更小的对齐片段,有效提高了对齐准确率,并且避免了错误蔓延。
但是,并不是所有的句子都包含有锚信息。所以,如果只使用锚信息作为双语句子的特征,召回率将会非常低。比较好的方法是将锚信息与其他句子特征相结合。
设汉语句子中锚信息序列CPi=Cp1,Cp2,…,Cpi和英文句子中的锚信息序列EPj=Ep1,Ep2,…,Epj相匹配的概率为P(CPi,EP j)。从所有的可能互译的句子对中,找到概率最大的锚信息序列对:

其中,“PA”表示锚信息对齐。假设每个句对的锚信息对齐概率相互独立,则有:

这里,P(Cpk,Epk)为Cpk和Epk对齐模式的概率,可以利用下式来计算:

同时,考虑到英语和汉语句子结构的不同,如果将锚信息顺序对齐,将会产生大量的错误。所以我们考虑了每个锚信息之间文本的长度,则有:

其中,δk为汉语锚信息Cpk和Cpk-1之间文本长度与英语锚信息Epk和Epk-1之间文本长度的一个函数。根据Gale和Church的理论有:

其中,le和lc是待对齐的英语和汉语文本的长度。参数c是汉语句子和英语句子长度的统计比例,从训练语料统计获得。
定义双语文本锚信息匹配相似度为:

其中,c为双语文本匹配的锚信息的个数;m为汉语文本中锚信息的个数;n为英语文本中锚信息的个数。
在对齐过程中,每次分析由三个汉语句子和三个英语句子构成的双语文本块。这样每次得到互译的双语句子后,按照滑动窗口的形式继续分析接下来的三个句子构成的文本块。双语文本块的特征向量如下所示:

其中,L(*)表示句子*的长度,以字符为单位计算;γ(c,e)表示句子c和句子e的锚信息匹配相似度。
3 高斯混合模型
3.1 模型概述
本文使用高斯混合模型作为分类工具,它通过高斯成分描述独立的输出特征和高斯混合模型拟合概率密度函数来实现分类功能。
假设λc为给定的一个类模型,则该类特征向量X的观察概率为:


其中,n是特征向量X的维度,∑为协方差对角阵。
3.2 参数估计
高斯混合模型训练是一个有监督的训练过程。对于给定的训练集,高斯混合模型训练的“好坏”需要一个评价标准,本文采用的是最大似然准则。在最大似然准则下,使用最大期望(Exception Maximum,EM)估计算法估计模型参数。
最大似然估计(M aximum Likelihood,M L)是一种评价模型“好坏”的标准。本质上,最大似然就是要求模型描述的分布能够最大限度逼近训练数据集的分布。

即最优模型参数能够使得训练集与模型匹配似然度达到最大。
我们为每一个对齐模式构造一个独立的模型,对每一个类进行最大似然估计:
对每一个独立的类模型λi(i=1,2,…,8)和特征向量X={x1,x2,…,xn},最大的正确率(也就是最小错误率)贝叶斯准则是:

利用以上准则,每一个特征向量序列xi就会是以上八个类中的一个。
4 实验和分析
手工从1979年到2006年中图分类号为R318的生物医学文献中筛选出200篇具有双语摘要的期刊论文的摘要,进行人工对齐后获得1 262个句对作为训练语料TC。
由于无法获得大量生物医学双语训练语料,因此对于各种语言现象和对齐情况覆盖度也是有一定限制的,因此对句子的长度特征的效果存在一定的影响。所以在对句子的长度特征进行训练的时候,利用迁移学习的思想,将《新概念英语》双语语料TC1(3 120个双语句对)和1262个生物医学领域双语语料相结合对句子的长度特征进行协同训练。TC1仅用来训练句子的长度特征。我们对 TC、TC1分别进行长度特征的训练,将得到的两组结果以经验比得到最后的结果。
从1979年到2006年中图分类号为R318的生物医学文献中筛选出180篇具有双语摘要的期刊的摘要共1 086个句对作为测试语料。测试语料对齐模式统计结果如表2所示。

表2 测试语料对齐模式和对齐模式概率
本文设计了四个实验:实验Baseline使用Gale和Church的基于长度的句子对齐方法,该方法是句子对齐的一个最基本的方法;实验T1考虑了长度特征和锚特征的高斯混合模型。Baseline和 T1都只是使用TC的1 262个生物医学领域的双语句对作为训练语料。实验T2使用Baseline的方法,但是引入迁移学习思想对TC的长度特征进行了迁移学习;实验T3使用T1的方法,但是引入了迁移学习的思想,利用《新概念英语》语料TC1作为辅助训练语料与生物医学语料TC相结合对句子的长度特征进行训练。
实验Baseline采用基本的基于长度的对齐概率模型,只考虑了句子的长度信息。这种方法在同源的英法加拿大的议会会议录(Canadian Hansards)获得了很好的对齐效果,但是由于英语和汉语不是同源语言,由于语法和表达习惯的巨大差异,基于句子长度的对齐方法在对齐过程中存在严重的错误蔓延,所以正确率很低。实验结果如表3所示。

表 3 Baseline实验结果
Baseline采用方法没有利用生物医学文献双语语料的段落特征和锚信息等特征,并且由于训练语料不够大,对齐效果比较差。针对训练语料的不足,在对句子长度特征进行训练时,我们引入迁移学习的思想,将生物医学文献双语语料与《新概念英语》双语语料相结合,对句子的长度特征进行训练,由于训练语料增加,对齐效果得到一些提高,如表4所示。

表4 T2实验结果
T2的实验由于训练语料的增加,对齐的正确率得到提高,说明《新概念英语》对生物医学文献双语句子对齐长度特征的训练有一定的帮助。
实验T1采用本文介绍的方法,利用分类思想进行句子对齐。在对齐过程中,考虑了句子长度信息和锚信息,利用高斯混合模型对双语文本块进行分类。实验结果得到很大的改进。实验结果如表5所示。

表5 T1实验结果
本文基于高斯混合模型的句子对齐方法考虑了生物医学文献中大量的锚信息,对齐过程中对以三个句子为单位的双语句块进行对齐,对齐的正确率得到了很大的提高。其中(1∶1)对齐模式的对齐正确率得到很大的提高。其他对齐模式的对齐正确率也得到较大的改进。该方法的缺陷是仍无法识别对齐模式为(1∶0)和(0∶1)的双语句对。通过对对齐错误的例子进行分析,错误比较集中。这是由于段落内对齐的错误蔓延造成的。比如,如果对齐过程中一个双语句块分类错误,那么该段落中这个句块以后的句子对齐的错误率就比较高。
实验T3的方法同样采用分类思想进行句子对齐,不同的是在对句子的长度特征进行训练过程中,本文引入迁移学习的思想,使用TC1和TC对句子长度特征和部分符号特征进行协同训练,由于语料规模增加,模型的参数更合理,实验结果有所提升。T3的实验结果如表6所示。
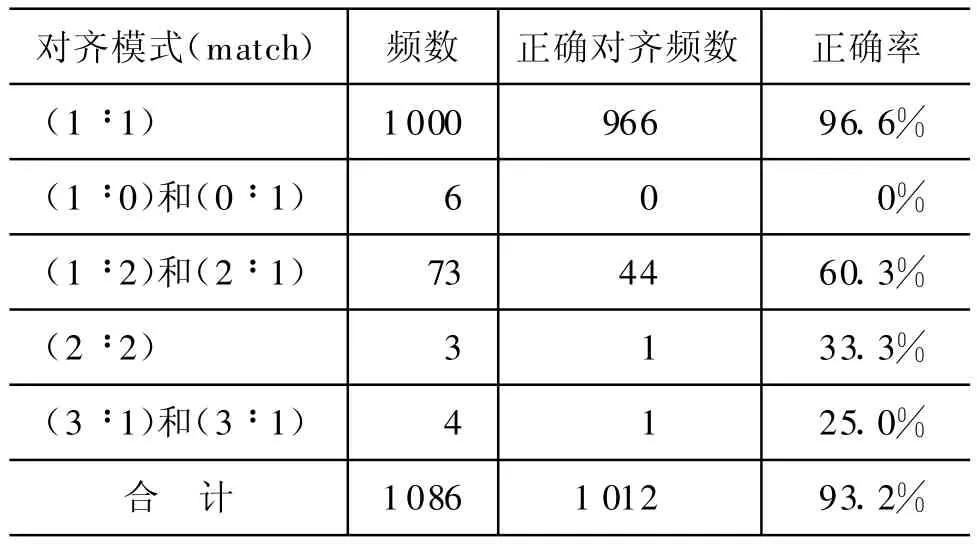
表6 T3实验结果
然而,由于在TC1语料上只进行了句子长度的特征训练和少量的锚信息特征(标点符号)的训练,所以增加TC1训练语料以后正确率提高有限。
5 结论与展望
本文利用高斯混合分类模型进行句子对齐,并且在模型训练过程中,利用了迁移学习的方法将新概念英语双语资源引入生物医学领域双语摘要句子对齐中,在更大规模的训练语料上进行模型的训练。对齐过程中,我们对三个句子组成的双语文本块进行分类,达到对齐的目的。
下一步工作主要是从双语摘要中提取出关键字对信息作为一部小型的一对一双语字典,并与本文的方法相结合。同时设法提高识别双语段落中对齐模式为(1:0)和(0:1)的句对的正确率。然后在本文工作的基础上进行生物医学领域双语术语词典的自动抽取,用于生物医学跨语言信息检索的翻译查询。
[1] Gale W.F.,Church K.W..A p rogram for alignment sentences in bilingual corpora[J].Computational Linguistics,1993,19(1):75-102.
[2] Brow n P.F.,Lai J.C.,Mercer R.L..A ligning sentences in parallel corpora[C]//Proceedings of the 29thAnnualMeeting of the Association for Computational Linguistics,Berkeley,CA,USA,1991:169-176.
[3] Thomas C.,Kevin C.A ligning parallel bilingual corpora statistically with punctuation criteria[J].Computational Linguistics and Chinese Language Processing,2005,10(1):95-122.
[4] Wu D.A ligning a parallel English-Chinese corpus statistically w ith lexical criteria[C]//Proceedings of the 32thAnnual Conference of the Association for Computational Linguistics.Las Cruces,NM,USA,1994:80-87.
[5] 张艳,柏冈秀纪.基于长度的扩展方法的汉英句子对齐[J].中文信息学报,2005,19(5):31-36.
[6] Chen S.F..A ligning sentences in bilingual corporausing lexical information[C]//Proceedings of the 31thAnnual Con ference o f the Association for Com putational Linguistics,Co lumbus,USA,1993:9-16.
[7] 吕学强,吴宏林,姚天顺.无双语词典的英汉词对齐[J].计算机学报,2004,27(8):1036-1045.
[8] M ohamed Abdel Fattah,David B.Bracew ell,Fu ji Ren.el al..Sentence alignment using P-NNT and GMM[J].Computer Speech and Language,2007,21(4):594-608.
[9] J.Pan,J.Kw ok,Q.Yang.Adap tive localization in a dynam ic Wifienvironment through mutil-view learning[C]//Proceedings of the 22nd conference on artificial intelligence(AAAI-07),Vancouve,Canada,2007:1108-1113.
[10] R.Raina,A Ng and D.Koller.Constructing informative p riors using transfer learning[C]//Proceedings of the 23thInternational Conference on Machine Learning(ICM L2006),Pittsburgh,USA,2006:713-720.
[11] W.Dai,Q.Yang,G.R.Xue and Y.Yu.Boosting for transfer learning[C]//Proceedings of the 24thInternationa l Con ference on Machine Learning,Corvallis,OR,USA,2007:193-200.
[12] H al DaumeIII,Daniel M arcu.Domain adap tation for statistical classifiers[J].Journal of A rtificial Intelligence Research,2006,26(1):101-126.
[13] Pengcheng W u,Thomas G Dietterich.Imp roving SVM accuracy by training on auxiliary data sources[C]//Proceedings o f the 21st Internationa l Con ference of Machine Learning(ICML2004),Banff,A lberta,Canada,2004.
