动词次范畴英汉论元对应关系获取
2010-07-18朱聪慧赵铁军韩习武郑德权
朱聪慧,赵铁军,韩习武,郑德权
(1.教育部—微软语言语音重点实验室,哈尔滨工业大学,黑龙江哈尔滨150001;2.计算机科学与技术学院,黑龙江大学,黑龙江哈尔滨150001)
1 引言
近年来词汇知识库的重要性无论在计算语言学界还是在理论语言学研究中都日益增长,动词的次范畴化(subcategorization)信息是国内外公认的该知识库中不可缺少的组成部分。次范畴化,又称次语类化,是根据句法信息的进一步划分;动词次范畴化即动词大语类的细化。同其他词类相比,动词表现形式最为复杂,在句法结构中活动能力最强,大多数其他句法成分都要跟它发生一定的结合或限制关系;动词是一般句子里最重要的部分,以动词为谓语或谓语中心词的句子最多,句型最为丰富。
关于动词次范畴化理论及其词汇知识自动获取的研究已经在英、汉、德、捷克、西班牙、希腊等的语言中取得了很大程度的进展[1-2],并在不同程度上建设了有助于单语信息处理的次范畴化词汇知识库。但是在多语言、跨语言信息交流日益频繁的今天,世界上跨语言次范畴化理论研究仍然很少,并且不成体系;更缺少系统地自动获取双语或多语次范畴化知识的实践性研究和相关研究方案。
英语和汉语都属于世界上最具有影响力的语种,英汉相关的信息处理量极大,并且二者在单语动词次范畴化理论研究和自动获取方面又都有着相对较好的科研成果。本文在汉英双语次范畴化形式描写的基础上,基于约90万汉英平行句对的语料库,进行了自动获取跨语言次范畴化论元对应关系的自动抽取;并将自动获取的论元对应关系,加入了统计机器翻译系统,实验证明,加入了论元对应关系的机器翻译系统,在Blue Score上提升了3.42%,N IST分数上有2.48%的提升,这说明了跨语言次范畴研究的价值。
文章其余部分组织如下:第二节简要介绍了提出的汉英双语动词次范畴化的形式描写机制;第三节介绍了基于加强学习策略的英汉双语动词次范畴论元对应关系地自动抽取方法;第四节是对应关系自动抽取的实验结果,以及融合了英汉论元对应关系的统计机器翻译系统的性能提升;最后,给出了结论。
2 次范畴化的句法形式描写
“次范畴化”本质上是一个子类划分的过程。近代的语言学理论大都与动词次范畴化现象有关,这些论述随着语言学基础理论的发展而有所变化。特别是20世纪80年代开始广为传播的词汇主义倾向(lexicalism trend)对次范畴化相关理论在句法和语义方面都产生了深远的影响。早期研究从句法和语义连接的角度出发,赋予论元特定的语义角色,认为论元的语义结构决定谓语的功能和次范畴;在词汇主义的影响下,研究者开始把次范畴化信息看作是词汇本身所特有的属性,即动词自身的特性就决定了它做谓语时可能进入的次范畴类别。
在这一历史过程中,对计算语言学,甚至是计算机科学的发展,起到了较大的促进作用的理论主要包括:管约论(Government-binding Theory)、格语法(Case G rammar)、广义短语结构语法(Generalized Phrase-Structure Gramm ar)、范畴语法(Categorial Theory)、词汇功能语法(Lexical-Functional G rammar)、配价理论(Valency Theory)、中心词驱动的短语结构法(Head-Driven Phrase-Structure G rammar)等等。这些不同的语法为动词次范畴化的形式描写和自动获取提供了基础的理论指导和具体实施的可能。
次范畴化句法描述的主要手段和工具是谓词论元(argum ent)结构,由谓词论元分布来形式化描述的句法结构一般称为次范畴框架(subcategorization frame),英文往往缩写为SCF或SF、目前相关研究中单词动词次范畴化框架或多或少地纳入了如下7种信息[1]:
1.论元的数码和类型,即特定谓语动词在某一上下文中所要求的搭配成分和该成分的句法标志;
2.谓语动词的意义,即特定谓语动词在某一次范畴框架中表现出的语义和部分语用;
3.谓语论元结构的语义表示,即次范畴框架本身句法所界定的语义特性或差异;
4.句法层和语义层之间的关系映射,即动词的表现形式和意义、次范畴框架的表现形式和意义等集合上的二元关系;
5.选择倾向或限制,即动词在句法和语义上倾向于或不能选择哪一类成分作论元;
6.谓补成分中可理解论元的控制,即次范畴化框架中那些论元可以省略或替代而不影响语义理解;
7.句型变化,即可以相互转换而不改变基本语义表达的不同次范畴化框架。
以上信息中,前两项是最基本的次范畴化内容;第三项可以看作是根据句法意义对前两项的一种分类;第四项是在句法和语义连接层面上对前三项的进一步细化;第五、六项是对第一项在语义和语用上的补充;最后一项是特定谓语动词所有的SCFs集合上可能的一种等价关系。除此之外,大部分SCF研究成果还都收集了动词SCF基于学习语料的概率或概率分布。
受传统语言学理论的影响,各种手工或自动的动词次范畴化获取研究往往基于不同的谓词论元形式描写。早期手工的或小规模的自动获取研究一般都以单一的方法来形式化论元,例如何万顺基于句法功能构建的26个汉语动词次范畴化框架[3];Brent基于论元的句法范畴设定6个英语动词SCF[4]等等。近年来规模较大的动词SCF自动获取研究一般都采用综合描写的方法来完成论元的形式化,例如A nna Korhonen关于英语SCF的研究[1]和Sabine shulte im Walde关于德语SCF的研究[5]。表1给出了动词次范畴化研究中具有代表性的集中论元描写形式。表中缩略语都是采用的语言学惯例:SUBJ为主语,OBJ为宾语,OBJ2为间接宾语,XCOMP为不定补语,SCOMP为子句补语,NCOMP是名词性补语,OBL是词汇功能语法中的其他功能,NP是名词短语,INF是不定式短语,S指子句,PP是介词短语,ADJP或JP指形容词短语,ADVP指副词短语,WH是疑问词等等(具体解释请参考相关文献)。
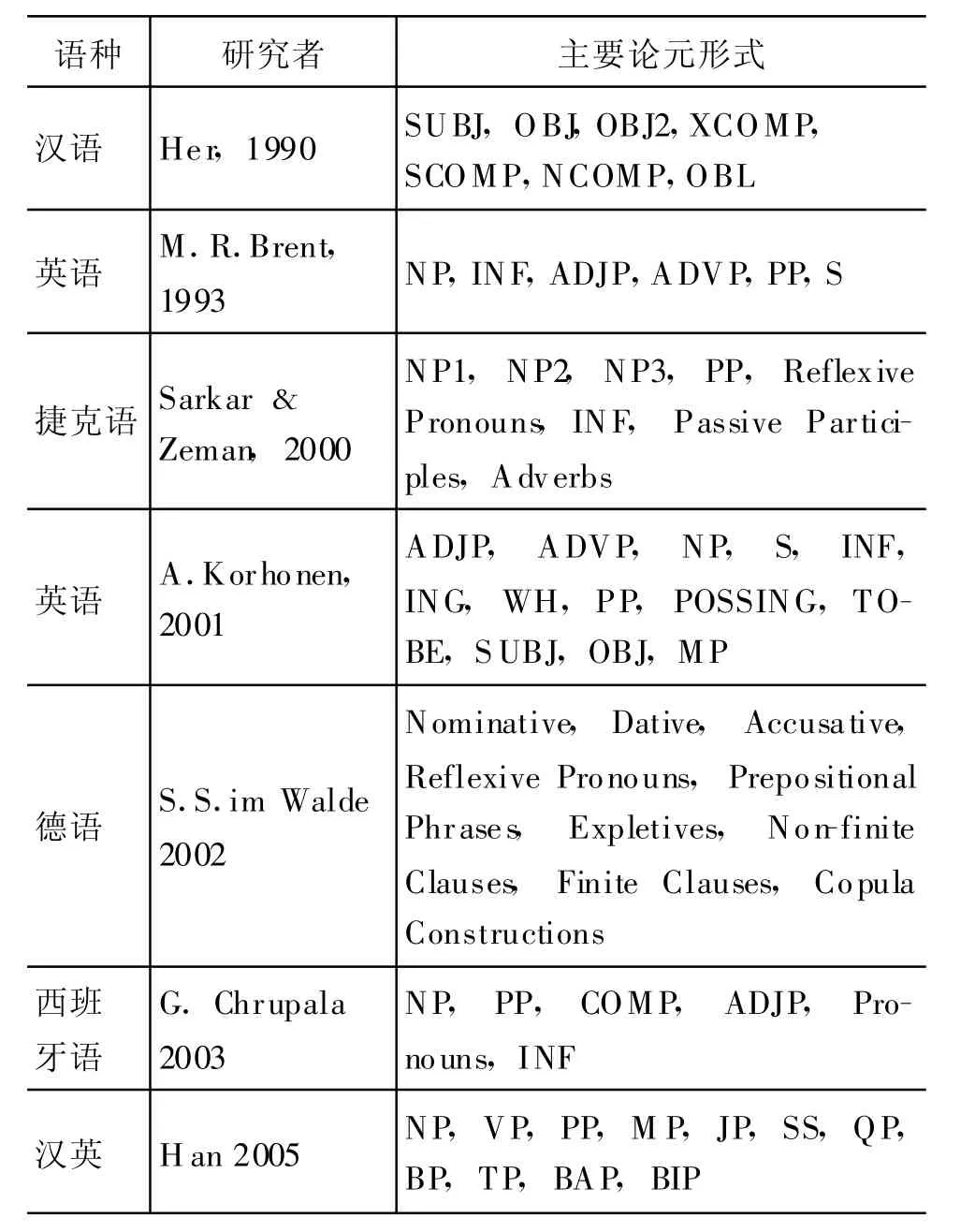
表1 几种论元描写形式
确定了论元的种类和描写形式之后,还要规范谓词论元构成的SCF排列顺序,也就是要确定每一个论元在SCF中相对于谓词和其他论元的位置。表2的例子给出了英语SCF No.26[1]和汉语 No.67[6]的论元构成方式:前者包括手工词典COMLEX,ANIT的分类标记和语义子类型“RAISed(提升)”,后者仅由句法论元按一定顺序构成(英语SCF语义子类型规定了句法结构所包含的意义,还包括‘EQUI',‘PVERB',‘DMOV T',‘EXTRAP',‘NONE'等等)。至于论元之间蕴含的实体关系,文献[7]利用卷积树核对中文实体关系抽取做了深入的研究。
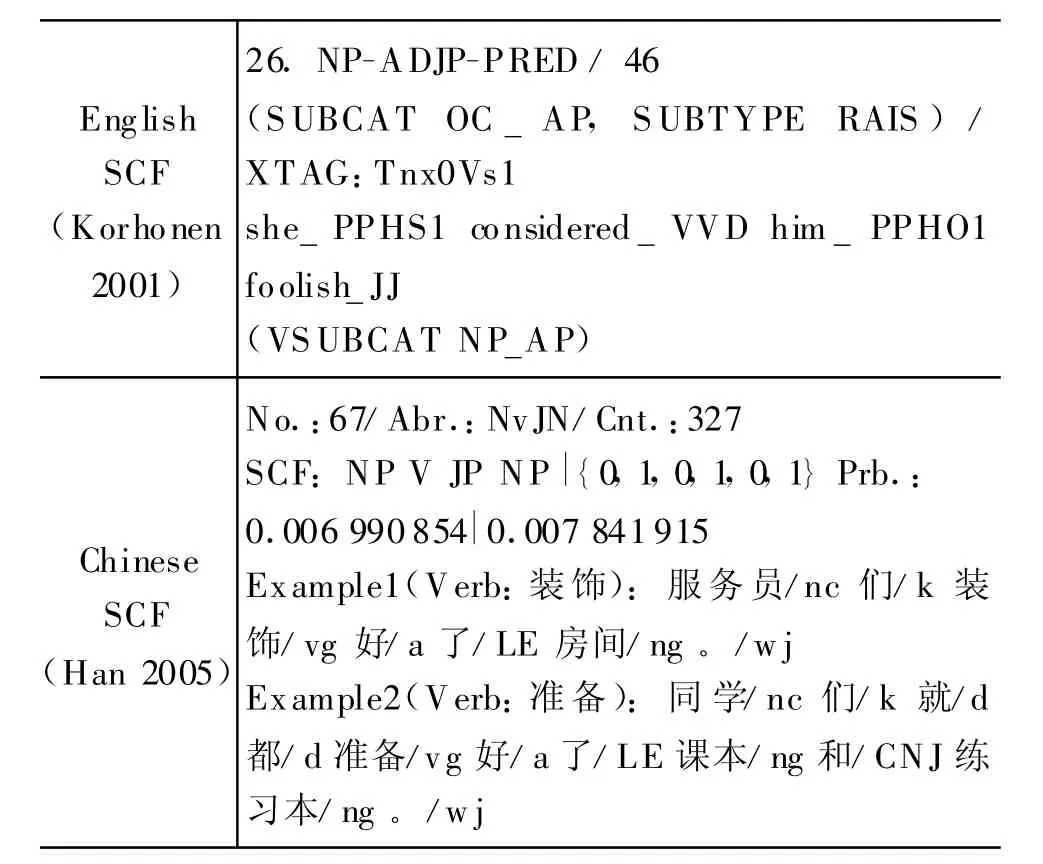
表2 论元组织形式的例子
次范畴化形式描写中句法和语义成分的比重是很难单纯确定的,只有根据不同自然语言处理任务进行适当的调整。次范畴化自动获取及其相关信息的应用都涉及到次范畴化框架的分析,而次范畴化框架的分析实质上是一个由表象到本质的认知过程,因此次范畴框架最好形式化那些句法功能的外在信息,即可观察的句法特征。并且一些较为实用的自然语言处理工具,如词法分析器和句法分析器等,也使得句法SCF较语义SCF更容易获取。只有较好的单语获取结果和兼容性强的句法模式才能保障跨语言次范畴化分析的可行性。
因此在汉英动词次范畴论元对应关系的自动获取任务中采用了句法描写的形式。汉语直接采用文献[6]的138类别纯句法描写的SCF基础类型;表3给出了英语句法SCF所包含的论元类型,AS表示‘as'IT表示‘it',RP表示小品词等等。

表3 英语句法论元类型
3 基于加强学习策略的英汉论元对应关系抽取
现有的次范畴化研究大都侧重于单语动词的谓语形式,只有针对那些包含可能对齐关系的双语句对进行跨语言SCF分析,双语SCF的自动获取才能更为可行,获取结果才会更易于语言学解释。因此,当前首要任务是抽取可能对齐的论元对应关系,即英汉SCF在组成成分上的对应关系。
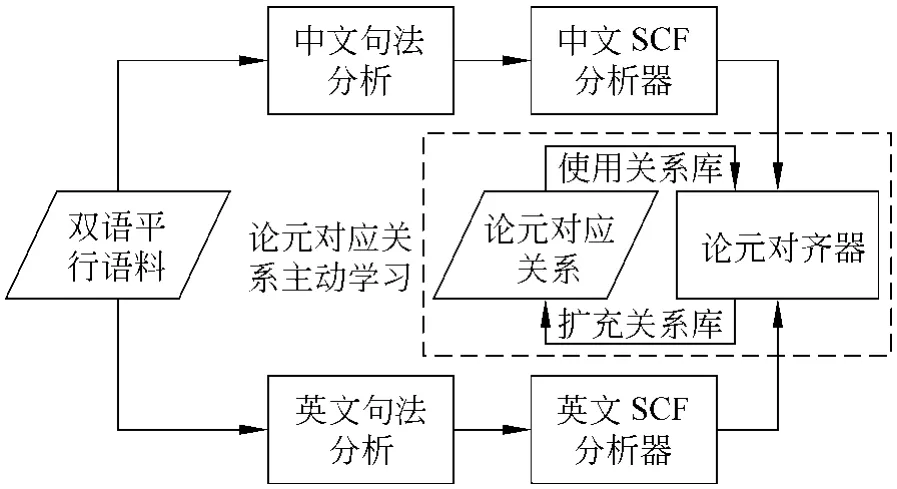
图1 英汉论元对应关系获取流程
我们收集了一些双语平行语料,分别经过英汉句法分析器为句子添加了相关句法信息。其中英语句法分析采用的是Collins的中心词驱动的句法分析,而汉语句法分析采用的是哈尔滨工业大学机器智能与翻译研究室开发的完全句法分析器。添加句法信息后,我们认为距离句法推导开始符号“S”最近的动词就是该句的核心动词。分别寻找出英汉句子的核心动词后,如果两个核心动词在双语词典中有定义,则此句对保留;否则,删除此句对。经过以上的处理,共有约90万句对保留了下来。SCF分析器为添加句法信息后的句子标注相应的SCF类别,其中汉语SCF分析器采用的是文献[8]提出的可以容忍句法噪音的分析器,汉语动词SCF论元识别精度为93.43%。而对应英文句子,手工分析了文献[1]附录A给出的180个例句和部分典型语料,归纳了66条句法论元识别和论元组合规则,并应用这些规则进行SCF类型获取。在1 000句英文句子的开发语料上的测试结果表明,英语论元识别结果的精确率约为92.6%。接下来,我们设计了一种基于主动学习策略的双语SCF论元对应关系获取器。它只以一条中英文的NP论元是等价的启发式规则(“汉语论元的NP=英文论元NP”)为初始种子,主动学习器就可以利用现有的知识库,在平行语料上自动抽取相应的论元对应关系,并将新的对应关系加入知识库,用于后续的关系获取,整体获取流程见图1。
3.1 SCF论元对应关系主动获取算法
为了避免传统切分方法需要人工确定论元对应规则的缺点,我们提出了一种基于主动学习策略的论元对应关系自动抽取方法。这种方法几乎不需要任何先验的语言学知识,而且可以直接在句法分析器的输出结果上以双语平行语料为基础进行对应关系的获取。我们的方法首先用一些简单的对应关系初始化知识库,然后根据当前知识库里已有的论元对,在平行语料上不断地抽取新的论元对应关系,并将新的对应加入知识库,以便后续抽取时继续使用。如此不断迭代,逐渐扩展论元对应关系知识库。理论上,在初始化论元知识库时,只需要加入“NP(汉语)=NP(英文)”(没有任何句法嵌套关系的一个汉语名词性论元词和英文名词论元是等价的)这一条规则,就可以完成论元知识库的建立,我们在实验中确实也只用了这一条规则初始化知识库。算法简要流程如下:

图2中是两组平行句对处理的例子。在处理第一个例子时,知识库中只有一条初始化对应关系“汉语NP=英文NP”,根据算法步骤(1),找到核心动词对应关系“V[杀害了]=V[murdered]”;然后根据步骤(2),在剩下的论元中寻找能与当前知识库中已有的对应关系相匹配的对应,在本例中为“NP[刘胡兰]=NP[Liu Hulan]”;因为英汉SCF论元中剩余未匹配论元的数量都为1,所以将剩余的论元对应关系,“BIP[被敌人]=NP[The enem y]”作为新抽取的论元对应关系加入知识库,即算法步骤(4)。接下来处理例子中的第二个句对,此时知识库中已经增加了一条新的对应关系,同理找到核心动词的对应关系“V[涂]=V[painted]”;此时,根据步骤(2),可以找到两条对应关系符合现有知识库的描述 ,“NP[墙]=NP[the wall]”和“BIP[被老孙]=NP[Lao Sun]”;最后根据步骤(4),“JP[黑了]=AP[Blace]”又被作为新的对应关系加入知识库。通过处理这两组平行句对后,论元对应关系知识库增加了两条新的论元对应关系,如此反复进行,最终就可以得到该数据集上的论元对应关系知识库。

图2 英汉论元对应关系抽取样例
4 实验结果
如前所述,从90万汉英双语句对中应用我们提出的论元对应关系自动抽取方法,共抽出约270万对含有词形信息的英汉动词次范畴论元对应关系,而去掉词形信息,自动抽取的英汉SCF论元类型对应关系共16类,详见表4。

表4 自动抽取的英汉论元对应关系
因为SCF框架中的论元不是标准的短语结构,而自动抽取的对应关系中的论元有很多只是标准短语的一部分,或者是多个不同短语的组合,所以很难单纯确定自动抽取的对应关系的正确性。而为了验证我们自动抽取的英汉论元对应关系的有效性,我们将这些对应关系加入了基于phrase的SM T系统。借鉴文献[9]在SM T系统中调整规则集属性的方法,我们在没抽取对应关系之前,我们使用GIZA++获得了词对齐信息,并将此信息和英汉对应关系匹配后,加入了SM T系统中的规则表(Phrase Table),我们将使用原始Phrase Tablet的翻译系统作为基准系统。系统的训练数据是我们收集的约90万英汉句对,而测试语料为美国国家标准与技术研究院(National Institute of Standards and Technology,简称NIST)2003年的汉英机器翻译评测语料,包括汉语句子506个,每个汉语句子对应16个手工翻译的参考答案。
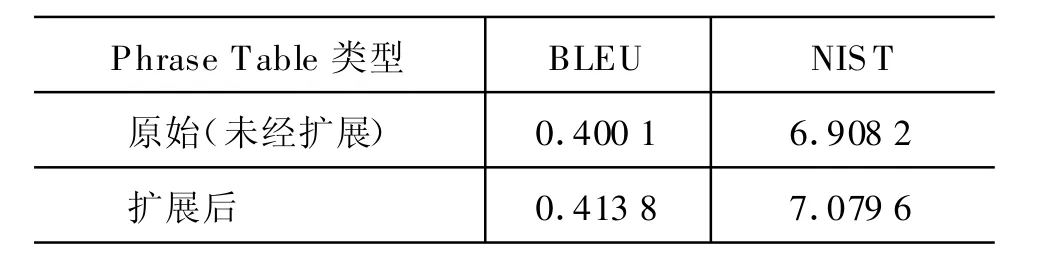
表5 融合论元关系前后SMT性能
由表5可以看出加入论元对应关系后,BLUE分数增加了0.013 7(提升3.42%),NIST分数增加了0.171 4(提升2.48%)。这在统计机器翻译的评测中是具备一定显著意义的。这是因为未经扩展的Phrase Tab le中的英汉短语对,大都是基于词对齐的方法获取的,其中大都是标准的单词和短语的英汉对应关系。而我们通过扩展加入了大量单词串的对应。这些对应中的单词串不一定是标准短语,与原有英汉短语对有很大的不同,也就是说经过扩展,Phrase Table中增加了很多额外的双语对应信息,所以提高了SM T的性能。由此可见,我们从真实语料中自动抽取论元对应关系,对统计机器翻译的性能提升方具有一定的实用性价值。
5 结论
本文提出了一个基于主动学习策略的英汉动词次范畴论元对应关系自动抽取方法。这种方法几乎不需要任何先验的语言学知识,可以在真实的双语平行语料上自动发现英汉论元的对应关系,并抽取出含有词形信息论元对。将自动获取的英汉论元关系融入基于Phrase的SM T系统后,翻译的性能有了明显提高,说明了我们方法自动抽取的对应关系的有效性,也为统计机器翻译的研究提供了新的研究方向。
[1] Korhonen A.Subcategorization acquisition[D].Trinity H all University of Cambridge,2001.
[2] Han Xi-wu,Zhao Tie-jun,Qi Hao-liang,et al.Subcategorization acquisition and evaluation for Chinese Verbs[C]//p roceedings of the COLING 2004,Sw itzerland,2004:723-728.
[3] Her O S.G rammatica l functions and verb Subcategorization in mandarin Chinese[D].University of Haw aii,1990.
[4] Brent M.From grammar to lexicon:unsupervised learning of lexical syntax[J].Computational Linguistics,1993,19(3):243-262.
[5] Sabine Shu lte im W alde.Inducing German semantic verb classes from purely syntactic Subcategorization information[C]//Proceedings of the 40thAnnual Meeting o f the Association for Com putational linguistics,USA,2002:223-230.
[6] 韩习武.汉语动词次范畴化自动获取技术的研究[D].哈尔滨工业大学,2005.
[7] 黄瑞红,孙乐,冯元勇,黄云平.基于核方法的中文实体关系抽取研究[J].中文信息学报,2008,22(5):102-108.
[8] Conghui Zhu,Tiejun Zhao and Xiw u Han.Chinese Verb Subcategorization A cquisition from Noisy Dataon Sentence Level[C]//Proceedings of 2009 World Congress on Com puter Science and Information Engineering,USA,2009:239-244.
[9] 方李成,宗成庆.基于层次短语的统计翻译系统中规则冗余度的高效约束方法[C]//第四届全国学生计算语言学会议论文集,太原,2008:303-309.
