文本蕴涵的推理模型与识别模型
2010-07-18袁毓林王明华
袁毓林,王明华
(1.北京大学中文系汉语语言学研究中心,北京100871;2.浙江大学国际教育学院,浙江杭州310027)
1 引言:何为文本蕴涵?
为了有效地处理自然语言中广泛存在的同义异形现象,近年来国外一些学者尝试用“文本蕴涵”(Textual Entailment)来为语言中纷繁复杂的同义表达建立模型。
所谓文本蕴涵,可以定义为一个连贯的文本(Text)T和一个被看作是假设(Hypothesis)的 H之间的一种关系。如果 H的意义(置于 T的语境中解释时)可以从 T的意义中推断出来;那么我们说T蕴涵(Entail)H(即H是T的推断),记作T⇒H。这种关于“文本蕴涵”的定义,十分全面地抓住了为不同的应用所需的对于语言表达多样性的推理。拿问答系统来说,它必须鉴别蕴涵了所期望的回答的文本。例如:
(1)a.Who killed Kennedy?
(谁杀死了肯尼迪)
b.the assassination of Kennedy by Oswald
(奥斯瓦德对肯尼迪的暗杀)
c.Osw ald killed Kennedy.
(奥斯瓦德杀死了肯尼迪)
对于给定的问句(1a)来说,文本(1b)蕴涵了句子性假设(1c);因此,(1b)可以作为(1a)的答句。同样,在信息检索中,由(非句子性)查询表达形式所指谓的概念,必须被相关的检索返回文档所蕴涵。在多文档自动文摘中,摘要中省去的冗余句子或表达,应该被摘要中的其他表达所蕴涵。在信息抽取中,蕴涵关系存在于表达相同关系的不同的文本变体中。在指代求解中,先行语通常蕴涵了指代表达。比如,在“IBM will……The com pany……”这样的语篇中,IBM蕴涵company[3,7,9]。
国外的许多学者积极从事文本蕴涵问题的研究,构造了不同的文本蕴涵的推理模型和识别模型,并且还举行国际性的竞赛和评测[8-9]。为了方便大家的了解,本文介绍几种文本蕴涵的推理模型和识别模型,供对内容挖掘和语义计算关心的同行参考。
2 文本蕴涵的推理模型
Dagan and G lickman[7]提出了一个逼近文本蕴涵关系的推理模型,借以预测蕴涵关系是否存在于一个给定的“文本—假设”对之间。这种推理模型由带有推理规则集的蕴涵型式(Entailment Patterns)知识库和相关的概率评价构成。上文给出的蕴涵关系的抽象定义是一种决定论式的:对于一个给定的文本T和假设H,人们假定T⇒H成立与否。而在他们这个推理模型中,他们采用了蕴涵关系的模糊观念(Fuzzy Notion):通过给一个蕴涵关系的实例标定一个概率得分,来评价蕴涵关系存在于这个特定的“文本—假设”对之间的概率有多大。下面分别介绍这个模型的三个主要的部分。
2.1蕴涵型式
他们把模板(Temp late)定义为带有句法分析的语言表达式,其中任选性地带有可以替换这个结构的某些组成部分的变量。变量可以根据所用的句法表示语言而抽象为某种句法类型,诸如词类或依存分析中的关系类型。一个蕴涵型式由下列两个部分构成:
A.型式结构:一个主蕴涵模板(左侧,记作LHS)和一个被蕴涵模板(右侧,记作 RHS),它们拥有共同的变量域。
B.型式概率:先验(Prior)概率和语境(即后验[Posterior])概率。比如:

其中,蕴涵型式指定了:对于任何变量的实例,一个蕴涵LHS的文本也蕴涵RHS的概率P的条件。概率是这样来估计的:当这个型式用于某个给定的语境中时,其先验和后验概率的真组合(Proper Combination)。
2.2 推理规则
设计推理机制,以便用给定的蕴涵型式库,并组合性地运用概率推理逻辑;从而,达到推断出更大的表达式之间的蕴涵关系。表1列出了用于该系统的一些核心的推理规则。
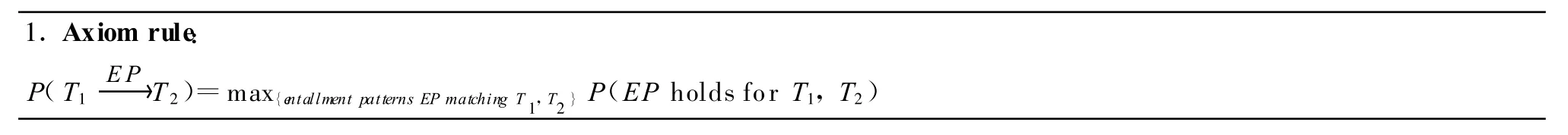
表1 5条核心的推理规则

续表
其中,规则1计算所有匹配性蕴涵型式的最大概率。所以称这种概率为“公理概率”(Axiom Probability),是因为蕴涵型式是给推理引擎的,而不是被演绎的。规则3和4描写前件和后件被组合进更大的表达式之中,而它们之间的蕴涵关系仍然保持不变的两种方式。为了表示这种组合方式,他们首先为语言表达式定义了一个扩展算子,记作E(T);它把T映射到一个更大的语言表达式,其中T被完全内嵌(T保持着其原来的句法结构)。限制性规则4在这种情况下运用:前件被扩展,但是没有破坏它对后件的蕴涵关系。例如:
(1)French p resident⇒president
当然,不是所有的扩展都能保持表达式原有的意义的。例如:
(2)vice p resident×⇒p resident单调性规则3在这种情况下运用:同一种扩展运用于前件和后件,但是没有改变它们之间的蕴涵关系的有效性。例如:
(3)a.Paris⇒French
b.visit Paris⇒visit French
当然,也不是所有的扩展都能表现出这种单调性的。例如:
(4)the population of Paris×⇒the population of French
最后,传递链接规则5说明:完全蕴涵的概率是从文本推导假设的一连串规则的最大积。
表2展示了下例(5)的推理链条,省去了概率:
(5)John bought a novel yesterday.⇒John purchased a book.
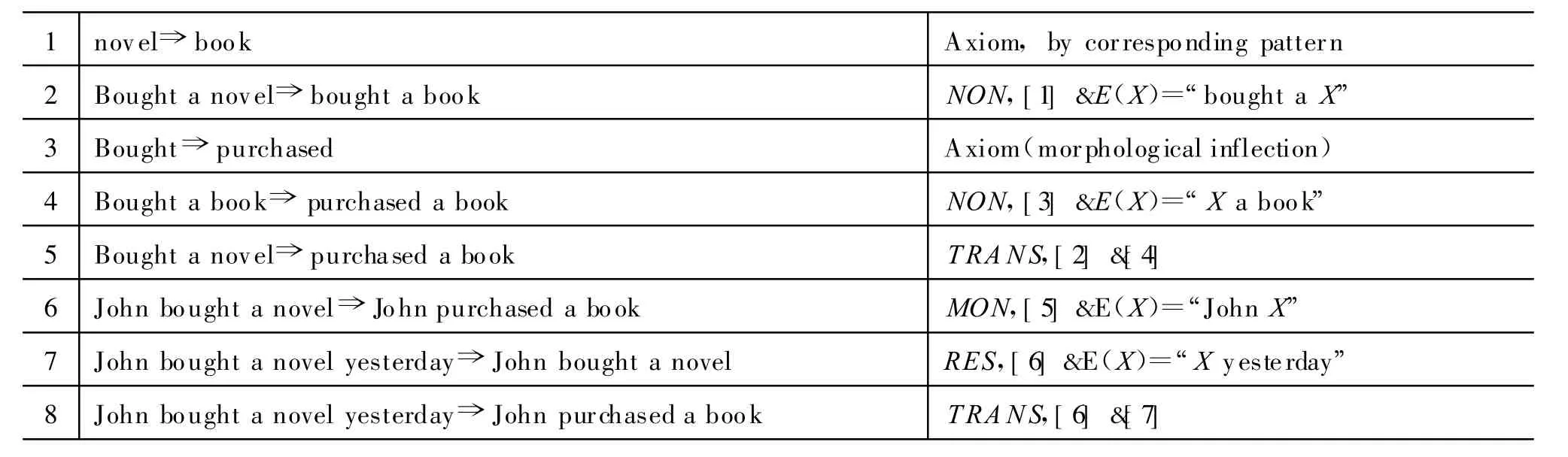
表2 推理链条的示例
2.3 推理引擎
他们用Prolog式引擎来实现上述的推理模型。这个引擎跟一个给定的语料库、一个蕴涵型式知识库和一个推理规则的实现相关联而运作。它拿假设作为输入,并运用这个推理模型,来发现语料库中的蕴涵文本的出现。对于每一个这种文本,该引擎输出相应的变量实例、蕴涵概率的得分和蕴涵推理的踪迹。表3展示了这个推理引擎的可能的输入和输出。可以通过判断输出的正确性,测量精确率和召回率,来评价这个系统。

表3 推理引擎的输入和输出示例
3 蕴涵型式的习得
像上文介绍的文本蕴涵的工作框架,只是提供了一种识别语言表达多样性的一般机制。真正要实现这种模型,需要系统能够获得推理规则和蕴涵型式两个方面的知识。而这些知识的自动学习,目前尚是富有挑战性的研究课题。下面介绍几种习得蕴涵型式的方法。
3.1 基于实例的蕴涵型式的习得
建立上文所涉及的单调性和限制性扩展的经验模型,是一项全新的工作。而学习蕴涵型式(结构和概率)的工作,可以跟有关应用领域中的自动识别同义互释相联系。比如,Lin and Pantel[16]提出了这样的方法:利用分布的相似性(Distributional Similarity)来为问题回答系统抽取推理规则。在问题回答、文本生成、文摘、信息抽取和翻译等领域,学习同义互释的更为主要的方法是基于实例(基于句子)[6]。这种方法的思想是:发现一对(组)看上去是描述大致相同的事实的相匹配的文本片段,并找出共同的词汇项目作为一组“支撑点”(A nchors)。那些跟已知的支撑点共有相同的关系的相应的成分,被习得为互释型式(Paraphrase Patterns)。例如:
(1)a.Yahoo bought Overture.
b.Yahoo own Overture.可以从中演绎下面这种蕴涵型式:
(2)X ←subjbuyobj→Y ⇒X ←subjownobj→Y并把Yahoo和Overture作为支撑点。
Dagan and G lickman[7]把蕴涵型式的习得问题看作是包含了下面两种类型的任务:(1)无指导的可能的蕴涵型式的习得,和(2)对这些可能的蕴涵型式的概率性二元分类。他们发展了两种从无标注的语料中学习蕴涵型式并对蕴涵型式的概率进行经验评价的方法。下面分别介绍。
3.2 从平行或单一语料库中抽取同义形式
像 Barzilay and M cKeown[4]、Shinyama et al.[18]、Barzilay and Lee[5]和 Pang et al.[17]等 ,都尝试基于识别平行语料库中的相对应的句子来学习同义互释;因为研究者事先已经知道这些语料库中包含了基本对应的文本。可比较语料库的主要类型是相同文本的不同翻译,还有报道大致相同的事件的新闻资料。
但是,在 Glickman and Dagan[10]中,他们提出了一种基于实例的从单一语料库中习得同义互释的词汇形式的算法。显然,习得一对(组)可比较的语料库是很不方便的,因为并不是所有的领域都有这种语料库,事实上也难以收集这样的语料库。因此,Glickm an and Dagan等致力于发展一种在单一语料库中发现实际的同义互释实例的方法。之所以能够发现这种同义互释实例,是因为相关领域的语料库中往往有对相同事实或事件的重复提及和表述,这种同义形式甚至还能在非常不同的故事中找到。这种方法把统计和语言学过滤结合起来,来产生一种由概率激发的同义互释的可能性得分。他们把这种方法跟 Lin and Pantel[16]基于矢量的方法相比较。看起来,他们的基于实例的方法有助于评价候选的同义形式的可靠性,而这种可靠性恰恰是Lin and Pantel等通过金本位的分布相似性测量方法所难以做到的。
表4展示他们抽取的动词性同义形式的例子和评分。

表4 从语料库中抽取的同义动词及其评分的示例

续表
3.3 从网络上学习蕴涵型式
Dagan and G lickm an[7]用基于实例的、无指导的方法,从朴素的语料库和网络上学习同义互释的型式;借此达到更为广泛的覆盖面,并拟合他们的基于蕴涵的框架的结构。整个学习过程包括两种主要的工作:(1)识别可靠的支撑点集合,和(2)识别联结支撑点并参与蕴涵型式的各种模板。他们遵循一般的共同训练(Co-Training)方式,用自举式(Bootstrapping)的方法,来反复地进行这两种工作。这项工作的一个特别的挑战是,对于任何给定的词汇项目,都能搜索到好的蕴涵(同义互释)型式;而不依赖于事先识别好的特定的支撑点,因而指明了将被识别的蕴涵型式具有同一性。
第一步,为一个给定的词汇核心词语(Lexical coreWord or Term)识别可靠的支撑点集合;其实,正是为了这个核心词语,我们才想要找到同义互释(蕴涵型式)。一个支撑点集合是这样一组词语,它们表明:一个普通事实用多种句子形式来描述,是具有很高的概率的。反复出现的网络搜索查询词语串,可以用来检索包含核心词语和相关支撑点的句子。接着,各种统计标准运用到这些检索到的支撑点候选成分上,来识别有希望的支撑点集合。比如,给定核心词语murder,接下来找到的支撑点集合是
第二步,从众多的支撑点集合中,用算法识别出可以在分析过的句子中把支撑点联结起来的最一般(最小)的语言结构。通过用变量替换那个语言结构中的支撑点,来得到蕴涵模板。
这种自举式的体系就是由上述两种过程的反复执行组成的,可以总结如下:
(1)初始化/播种子:对模板核心的一系列候选成分进行初始化。这些候选成分来自某个输入词库,而这个输入词库又是从词典、WordNet、领域语料库等资源中抽取出来的。
(2)对于每一个模板核心的候选成分,
a.用查询工具抽取包含该模板核心词语的句子,
b.从这些句子中抽取候选的支撑点集合,并测试其在统计上的重要性;
(3)对于每一个抽取出来的支撑点集合,
a.抽取一组包含这些支撑点词语的句子,
b.从这些句子的相匹配的部分子结构中
抽取候选的模板和核心,并测试其在统计上的重要性;
(4)反复进行(2)和(3),直到满足习得的要求;
(5)在抽取出来的模板中生成蕴涵型式,并评价其概率。
表5展示了应用这种算法得到的一个初步的输出。

表5 由自举式算法得到的输出的示例

续表
3.4 学习蕴涵型式的概率
上述反复地抽取模板的处理过程,可以产生一个反映支撑点集合和模板的频度的列联表,如表6所示。

表6 反映支撑点集合和模板频度的列联表
蕴涵型式及其估计的蕴涵概率可以从这种列联表中导出。比如,表6显示assassinate蕴涵m urder具有很高的概率,而相反方向的蕴涵关系只适合于部分情况。他们计划研究怎样从这种表的横栏上来合理地估计先验的蕴涵概率。估计蕴涵型式的概率是富有挑战性的,因为这种语料上没有标注蕴涵关系方面的标记。
蕴涵模板出现于其中的语境,为相应的蕴涵型式的可用性,确定了一种后验的语境概率。比如,从表6中学习这种语境:其中 murder蕴涵assassinate,那么人们需要识别适合于左边两列的典型语境,即相应的政治性情景;这种情景区别于右列的非政治性情景。他们认为这种工作跟词义消歧分类相似。事实上,使用语境概率的主要动机是在碰到有歧义的词语时,能够正确地应用蕴涵型式;比如,只有在bank表示金融[机构]的意义时,bank⇒company才能成立。因此,他们探索怎样用词义消歧的表示和学习方法去学习语境概率。最后,另一个富有挑战性的工作是,在应用蕴涵型式时,怎样根据语境匹配的程度,合适地把先验和后验估计结合起来。
4 文本蕴涵的概率性词汇方法
由于文本之间的蕴涵关系并不是一种确定性的关系,并且文本之间的蕴涵关系在一定程度上可以化简和归约为两个文本中所包含的某个词汇概念之间的蕴涵关系;因而,通过构建词汇蕴涵的概率模型来逼近文本蕴涵,不失为一种简捷有效的途径。下面主要介绍G lickm an et al.[11-12]所报道的这方面的工作。
4.1 文本蕴涵的通用生成概率机制
Glickman et al.[11]注意到蕴涵所指的不确定性和概率性,例如:
(1)a.Wherewas Harry Resoner born?
b.Harry Resoner's birthplace is Iowa.
c.H arry Resoner was born in Iowa.
d.Harry Resoner is returning to his hometown to getmarried.
对于一个问题回答系统来说,可以认为包含(1b)的文本蕴涵了问句(1a)所期望的答句(1c);但是,包含(1d)的文本是否蕴涵了答句形式(1c),就不好确定了。
为此,他们提出了一个文本蕴涵的通用生成概率机制。他们假定:语言资源是在某种事态语境中生成文本的。这样,文本是跟对于假设的隐式的真值指派一起生成的。他们定义了相应的概率空间中的两类事件:
(1)对于假设h,他们用 Trh代表随机变量,其值就是在生成文本的[可能]世界中赋予h的真值。于是,Trh=1是h被赋予真值1(真)的事件。
(2)对于文本t,他们仍然用t代表生成文本是t的事件。
文本蕴涵关系:如果t增加了h为真的可能性,即P(Trh=1|t)>P(Trh=1);那么可以说t在概率上蕴涵h,记作t⇒h。
蕴涵置信度(Confidence):他们用点式互信息(Pointw ise M utual Information)来表示由文本提供的用以评价假设的(跟其先验概率有关的)真值的信息的边际(最低限度的)量:

4.2 从文本蕴涵到词汇蕴涵
上文提出的文本蕴涵生成概率机制,为建立文本蕴涵的概率模型提供了必要的基础;但是,估计文本蕴涵的成分概率也是十分重要的,因为对于语料库中的文本的假设的真值指派是无法观察到的。由于为完整的文本蕴涵问题建立模型是一个长远的研究目标,因而他们把重点放在词汇蕴涵(Lexical Entailment)这个子目标上,即识别假设中的某个词汇观念能否从特定的文本中推演出来。
在估计蕴涵概率时,他们假定:假设h中的词项u的真值概率,独立于h中的其他词项;于是,得到下列公式:
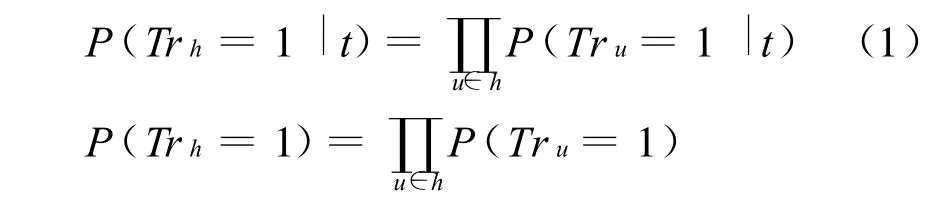
这样,蕴涵关系的识别问题便可以看作是一种文本分类工作(Text C lassification task);其中,类别就是对于词汇表中不同的词的词汇真值的抽象的二分概念。首先,他们单纯根据各个u在t中是否显性地出现,构造初始的标记添加系统。然后,以无指导的方式运用朴素的贝叶斯方法(Naïve Bayes),这种方式可以从定义好的概率机制中分析性地导出。
4.3 词汇蕴涵的概率模型
作为一种初步的逼近,他们假定:对于语料库中的任何文件,词项u的真值决定于它是否显性地在这个文件中出现。就某个方面来看,标记添加系统类似于具有下列功能的布尔搜索系统——根据文本性假设中的关键词来进行(无扩展的)布尔搜索,以找到候选的主蕴涵文本。根据贝叶斯假设,他们把概率公式P(Tru=1|t)改写为:

这样,就可以根据先验概率P(v|Tru=1)、词汇V中的每一个u与v的词汇概率P(v|Tru=1)与P(v|Tru=0),来估计P(Tru=1|t)。这些概率是比较容易从语料库中估计的,只要给出初始模型对于真值指派的估计,并假定文件的多项事件模型(M ultinom ial Event M odel)和拉普拉斯平滑(Lap lace Smoothing)。从上面的等式,可以对任意文本t和假设h的P(Trh=1|t)和 P(Trh=1),都有一个精确的概率估计。把概率估计转换为分类判定的准则,可以从他们提出的关于文本蕴涵的概率机制上分析性地导出。如果P(Trh=1|t)>P(Trh=1),他们就给蕴涵关系作出肯定性的分类;并且,为了划分等级,给P(Trh=1|t)/P(Trh=1)指派一个置信度得分。事实上,经验性评价证明,这种解析阈限几乎是最优的。
他们通过人工的方法构建“假设—文本”对集合,用一部分来训练上述模型,再选取一部分来测试;结果宏观的平均正确率达70%,平均置信权重得分(ConfidenceWeighted Score,Cw s)达0.54,都超过了用其他方法建造的系统。
4.4 词汇所指的语义匹配假设
Glickman et al.[12]指出,文本理解应用的一项基础工作是识别语义上等同的文本片段;而大多数语义匹配工作是在词汇平面上进行的,目的在于确定:一个文本中的某个词语的意思,是否在另一个文本中也得到了表达。通常,这种词汇匹配模型要测量字面上相同的词汇重叠的程度;当然,也会通过各种词汇替换标准来扩充词汇重叠的范围。这种词汇替换标准是基于WordNet等资源、或者各种统计文本相似性方法所得到的结果而确立的。也就是说,从单纯的词汇重叠扩展为词汇所指(Lexical Reference)的相同。比如,Lin[15]提出了著名的测量语义相似性的分布假设:出现在相似语境中的词语在语义上也相似。利用分布相似性,可以从单一语料库中识别同义互释的型式。
因为,假设h中的词汇概念在给定的文本t中得到表达,这通常是文本蕴涵的必要(而非充分)条件;所以,文本蕴涵的识别可以化简归约为:识别假设h中每一个词语的意义是否被相应文本t中的某些意义所指谓。Glickman et al[12]提议,这个目标可以通过下列定义来抓住:
如果文本t中的一组词语显性或隐性地指谓了词语w的可能的意义,那么词语w被文本t词汇性地指谓了。
可见,词汇蕴涵应该是更为复杂的蕴涵模型(或语义匹配)系统的一个组成部分。词汇指称可以看作是把文本蕴涵自然地延伸到诸如词语等小于句子的假设(Sub-Sentential Hypotheses)上。这种工作虽然把重心放在词上,但是可以推广到词语复合体和短语上。为此,他们建造了有关的数据库,请两个标注者根据下列规范对有关的“句子—词语”对进行标注:
定义给定的句子和目标词,评定目标词是(真)否(假)被句子指谓。在下列情况下标定“句子—词语”对[的词汇蕴涵关系]为真,在其他情况下一律标定为假:
(1)词。如果句子中的某个词,在该句子所构成的语境中,表示了目标词的意义(如:同义词、下义词),或者表示了目标词的意义的所指(如:blind→see,sight)。
(2)短语。如果句子中几个词语组合起来形成独立的表达形式,表示了目标词的(相同义项的)意义(如:call off→cancelled,home of→located)。
(3)语境。如果目标词的意义所指不是由单独的词或短语表示,而是由句子中的某个或几个部分(甚至整个句子)来表示。例如:
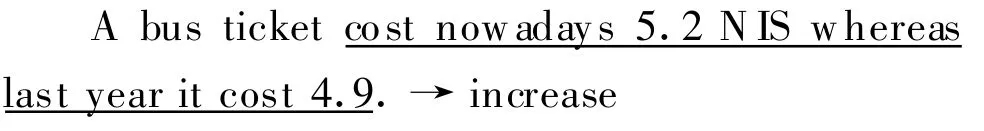
通过对标注语料的分析,他们证实了他们的假设:只有当假设h中的所有的实词的意义被文本t所指谓,它们之间的蕴涵关系才有可能成立。
4.5 基于词汇所指的语义匹配模型
Glickman et al.[12]指出,有了上述词汇所指数据库,就可以对各种词汇模型从质和量上进行比较。他们展示五种可用以词汇所指工作的模型,并对它们的表现进行测试和分析。每一种模型都向给定的一对文本t和目标词u指派一个[0,1]得分,这个分数可以解释为词语u在文本t中被词汇性地指称的置信度。下面分别介绍这五种词汇指称模型:
(1)WordNet模型:直接利用WordNet的词汇信息。首先,对文本和目标词进行词目化处理(lemmatize);然后赋分:如果文本包含目标词的同义词、下义词、或者其派生形式,那么赋分1;其他情况下,赋分0。
(2)相似性模型:利用Lin[15]的分布相似性测量方法,对于文本t和目标词u,他们用下列公式指派最大相似性得分:
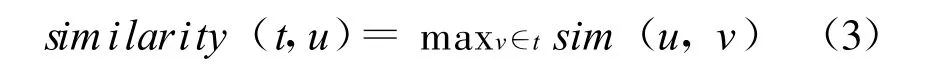
其中,sim(u,v)是u和v的相似性得分。
(3)对齐模型:这是一种基于词语同现统计的词汇概率模型,它对于文本t和目标词u作如下的对齐定义:

其中,P(u|v)是简单的同现概率,即一个句子中既包含v又包含u的概率。
(4)贝叶斯模型:这种模型处理语境指称问题,而不是词对词的匹配。这种模型基于朴素的贝叶斯文本分类方法,语料库中的句子被当作文档使用,类别就是目标词u的所指。包含目标词u的句子被用作正例,其他句子被当作反例。它对于文本t和目标词u作如下的指称关系定义:
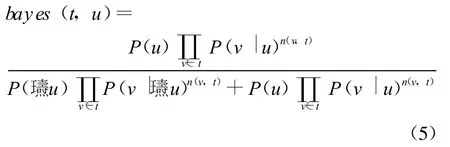
其中,n(w,t)是词w出现在文本t中的次数,P(u)是句子包含词u的概率,P(v|(u)是不包含词u的句子包含词v的概率。为了减少数据规模和解释零概率,他们运用平滑手段和特征选择信息。
(5)混合模型:把WordNet模型和贝叶斯模型结合起来,以便既很好地识别明显的词对词指称的例子,又能很好地识别语境隐含的指称的例子。通过评价两种模型的朴素的线性插值(简单地平均这两种模型的得分),来综合它们的威力。
5 文本蕴涵的句法—语义模型
为了系统实现的方便,一般的文本蕴涵识别处理往往采用词汇概率方法。但是,也有人尝试句法分析或基于句法的语义分析模型,以此更加逼近人类理解蕴涵关系时的心智过程,并进一步提高蕴涵识别的精确率和召回率。下面介绍几个这方面的有关工作和处理模型。
5.1 句法分析在蕴涵识别中的贡献与运用
Vanderwende et al.[19]介绍,他们请两个熟练的语言学者分析PASCAL文本蕴涵邀请赛的测试语料,离析出那些单纯根据句法线索就可以准确地预测“文本—假设”对之间是否具有蕴涵关系的部分;从而,了解用健壮的[句法]分析器可以解决这项工作的多少(比例)。
两个人工标注者评价测试集中的“文本—假设”对,断定它们在蕴涵关系方面属于下面的哪一种类别:
[1]True by Syntax(从句法上看是真的),
[2]False by Syntax(从句法上看是假的),
[3]Not Syntax (不是句法层面上的),
[4]Can't Decide (无法作出判断)。
结果,发现37%的测试项目可以通过人工根据句法来判断;如果允许利用普通的义类词典(Thesaurus),那么可以提高到49%。
所谓句法线索,主要包括“文本—假设”对之间是常见的句式变换形式(A lternation),和基于句法的论元指派、句内代词回指求解等。例如:
(1)a.T:The A lameda Central,west of the Zocalo,was created in 1592.
b.H:The A lam eda Central is west of the Zocalo.
(2)a.Schroeder's election→b.Schroeder was elected
(3)a.w here hew as surfing→b.while surfing
(1a)中的同位结构可以提升为(1b)之类的主句结构,(2a)中的名词化结构可以变换为(2b)之类的带时制的从句,(3a)中的限定结构可以变换为(3b)之类的非限定结构。
值得注意的是,如果“文本—假设”对在句法结构方面没有共同之处,那么往往可以断定它们之间没有蕴涵关系;当然,要建造一个能够自动地发现两个句子之间缺乏句法重叠的系统是不太可能的。另外,如果两个句子的主语与动词都是对齐的(A ligned),但是宾语没有对齐;那么,它们之间一般没有蕴涵关系。
Herrera et al[13]介绍,他们参加RTE-1竞赛的系统的工作原理是:寻找文本和假设的依存树之间的匹配关系。该系统主要有以下三个部分:
1)依存分析器:它基于Lin[15]所报道的Minipar。该依存分析器把来自“文本—假设”对语料库的数据规范化,进行依存关系分析;构造出能够表示这种依存关系的合适的结构,并且记住它们。
2)词汇蕴涵模块:它从分析器中获得信息,返回假设中被文本所蕴涵的节点。
3)匹配评价模块:它沿着词汇蕴涵节点,搜索进入假设的依存树的路径。
其中,不仅同义关系、下义关系等词汇知识,而且否定关系和反义关系,都对于判断“文本—假设”对之间的蕴涵关系有用。例如:
(4)a.T:Clinton's new book isnot big seller here.
b.H:Clinton's book isa big seller.
(5)a.T:...m inister says his country w ill not change its p lan...
b.H:South Korea continues to send troops.
可见,蕴涵关系不可能存在于一个词项跟其否定形式之间,如例(4)所示;但是,可能存在于一个词项跟其反义词的否定形式之间,如例(5)所示。
“文本—假设”对之间是否具有蕴涵关系,是根据它们之间的相似性来决定的。而这种相似性被定义为假设中能够跟文本匹配上的节点的比例。经过试验,发现这种相似性的阈值是50%。也就是说,当假设中能够跟文本匹配上的节点的比例达到或超过50%时,可以说它们之间具有蕴涵关系;当这种比例小于 50%时,可以说它们之间不具有蕴涵关系。
为了比较该系统的性能,他们设计了两个简单的基线系统:
1)基线系统I:单纯计算假设中的词在文本中出现的比例数;
2)基线系统II:单纯计算假设中可以被文本中的任何词所蕴涵的词的比例数;
这两个基线系统都取50%作为阈值。
结果显示,该系统对于RTE-1竞赛的测试语料的精确率,比上面两个基线系统要高。具体地说,基线系统I的总的精确率是54.95%,基线系统II的总的精确率是55.48%,该系统的总的精确率是达56.36%。这说明,两个句子在词汇上有较高的重叠,并不意味着它们之间具有蕴涵关系;相反,两个句子在词汇上有较低的重叠,并不意味着它们在语义上完全不同。为了确定两个句子之间有无蕴涵关系,必须分析它们在次结构(Substructure)方面的句法关系;也就是说,必须对句法关系进行深度的(In-dep th)处理。
5.2 利用论元结构和原子命题识别蕴涵关系
And reevskaia etal[2]介绍,他们参加RTE-1竞赛的系统的工作原理是:用简单的一般性的启发式和知识贫乏的方法来识别同义互释,用NP同指互参、NP语块切分、RASP和 Link两个分析器来给“文本—假设”对中的每一个句子产生谓词—论元结构(PAS)。例如:
(1)a.Two-thirds of the Scottish police force w ill be dep loyed at the happening.
b.
其中,(1b)是句子(1a)的谓词—论元结构(PAS)表达式。
然后,用WordNet词汇链和一些专门的启发式规则来建立这些PAS中相应成分的语义相似性;最后,为这些相应的PAS的结构相似性和相应词汇成分的相似性设定阈值,用以判断“文本—假设”对之间的蕴涵关系是否成立。结果显示,他们的算法和系统在精确率和召回率方面更加偏向前者而不是后者;具体地说,在精确率方面达到0.55~0.57,但是在召回率方面只有0.15~0.18。这个系统,成为他们将来研发事件同指互参和可比较文档分析的基线系统。
Akhmatova[1]介绍,他们参加RTE-1竞赛的系统的工作原理是:基于句法的语义分析,用原子命题(A tomic Proposition)作为蕴涵识别的主要元素。因为要想知道一个假设H是否被一个文本T所蕴涵,人们必须比较它们的意义。而句子的意义可以表示成包含在句子中的一组原子命题。于是,为了比较句子的意义,先要比较这些原子命题。这样,通过比较包含在“文本—假设”对句子中的原子命题,来发现该句子对之间有无蕴涵关系。
原子命题可以定义为其真值为真或假的最小陈述形式,并且,其真值的真或假不依赖于其他命题的真值的真或假。例如:
(2)a.Coffee boosts energy and provides health benefits.
b.Coffee boosts energy.
c.Coffee provides health benefits.
句子(2a)中包含(2b,c)两个原子命题。把句子分割成原子命题,必须对句子进行基于句法的语义分析,这种深层的句法、语义分析对蕴涵识别是至关重要的。在实现时,他们从分析器Link产生的结果中抽取原子命题,把它们输入到语义分析器,以推导出用一阶谓词逻辑表示的意义表达式。同时,利用从WordNet数据库中拿来的语义知识(比如,词语之间的同义、蕴涵关系),通过自动演绎系统OTTER来对原子命题进行比较;如果假设中的原子命题能够跟文本中的原子命题相匹配,那么蕴涵关系成立。现在,该系统可以识别基于语义和句法的蕴涵关系,还有可能利用更多的内部和外部知识来处理复杂的蕴涵现象。
5.3 浅层的词汇统计和深层的自然语言处理相结合
Jijkoun and Rijke[14]介绍,他们参加RTE-1竞赛的系统的工作原理是:计算有向的(Directed)句子相似性,即核查“文本—假设”对之间在有向的语义[实在的]词方面的重叠。他们用基于频率的词项权重,结合两种不同的词汇相似性测量方法。通过在RTE-1竞赛的测试语料上的运行,结果表明该系统的正确率达0.55。
首先,他们把“文本—假设”对中的句子都看作是一组词语,计算有向的句子相似性的得分;然后,设定阈值来判定“文本—假设”对中的句子之间有无蕴涵关系。这种方法可以用下面这种准算法来实现:

其中的要旨是:根据度量词的相似性wordsim(w1,w2)的需要,对于假设中的每一个词,都要在文本中寻找最相似的词。如果这种相似词存在(maxSim即不为零),就给总的相似性得分加上加权的相似性值。否则,就减去词的权重,即对假设中那些在文本中没有匹配词的词进行处罚。最终,他们发现如果不作出过度的拟合,那么他们的系统简直无法改进;由此说明:需要探索更深层的文本特征。
鉴于浅层的词汇统计和深层的句法分析都有缺陷,Bos and Markert[6]提出了把两者结合起来的路子:基于词汇重叠的浅层方法和利用定理证明的深层方法相结合。再用机器学习的方法把这两种方法得到的特征结合起来。结果,他们参加RTE-1竞赛提交了两个运行结果:一个只用浅层特征,正确率是0.555 0;另一个利用所有的特征,正确率是0.562 5。他们感叹:他们的方法面临的困难是缺少背景知识。
[1] Akhmatova,Elena.Textual Entailment Resolution via A tom ic Proposition[C]//Proceedings of the PASCAL Challenges W orkshop on Recognising Textual Entailment.2005.
[2] Andreevskaia,Alina,Zhuoyan Li and Sabine Berger.Can Shallow Predicate A rgument Structure Determ ine Entailment?[C]//Proceedings of the PASCAL Challenges Workshop on Recognising Textual Entailment.2005:
[3] Bar-Haim,Roy,Idan Szpek tor and Oren Glickman.Definition and Analysis of Intermediate Entailment Levels[C]//Proceeding o f the ACL Workshop on Empirical Modeling of Semantic Equivalence and Entailment.2005:55-60.
[4] Barzilay,Regina and Kathleen M cKeow n(2001)Extracting Paraphrases from a Parallel Corpus[C]//ACL/EACL.2001:50-57.
[5] Barzilay,Regina and Lillian Lee.Learning to Paraphrase:An Unsupervised Approach Using Mu ltiple-Sequence A lignment[C]//Proceeding of the NAACLH LT.2003:16-23.
[6] Bos,Johan and Katja Markert.Combining Shallow and Deep NLP Methods for Recognizing Textual Entailment[C]//Proceedings o f the PASCAL Challenges W orkshop on Recognising Textual Entailment.2005:
[7] Dagan,Ido and O ren G lickman.Probabilistic Textual Entailment:Generic App lied M odeling of Language Variability[C]//PASAL workshop on Learning Methods for Text Understanding and M ining,Grenoble France.2004.
[8] Dagan,Ido,O ren G lickman,Alfio G liozzo,Efrat M armorshtein,Car lo Strapparava.DirectW ord Sense M atching for Lexical Substitution[C]//COLING-ACL'06.2006:
[9] Dagan,Ido,Oren G lickman and Bernado Magnini.The PASCAL Recognising Tex tual Entailment Challenge[J].Lecture Notes in Computer Science,2006,3944:177-190.
[10] G lickman,Oren and Ido Dagan.Identifying Lexical Paraphrases from a Single Corpus:A Case Study for Verbs[C]//Proceedings of Recent Advantages in Natura l Language Processing.2003:
[11] G lickman,Oren,Ido Dagan and Moshe Koppel.A Probabilistic Lexical Approach to Textual Entailment[C]//Proceedings o f the N ineteenth International Joint Conferenceon A rtificial Intelligence.2005:1682-1683.
[12] G lickman,Oren,Eyal Shnarch and Ido Dagan.Lexical Reference:a Semantic M atching Subtask[C]//Proceedings of the 2006 con ference on Empirical M ethods in Natural Language Processing.2006:172-179.
[13] Herrera,Jes s,Anselmo Pe as and Felisa Verdejo.Textual Entailment Recognition on Dependency Analysis and WordNet[C]//Proceedings o f the PASCAL Challenges Workshop on Recognising Textual Entailment.2005:
[14] Jijkoun,Valentin and Maarten de Rijke.Recognizing Textual Entailment Using Lexica l Sim ilarity[C]//Proceedings of the PASCAL Challenges Workshop on Recognising Tex tual Entailment.2005:
[15] Lin,Dekang.Automatic Retrieval and Clustering of SimilarW ords[C]//Proceedings o f the 17thinternational Conference on Com putational Linguistics,Morristow n,NJ,USA.Association for Computational Linguistics.1998:768-774.
[16] Lin,Dekang and Patrick Pantel.Discovery o f Inference Rules for Question Answ ering,Natural Language Engineering 2001,7(4):342-360.
[17] Pang,Bo,Kevin Knight and Daniel M arcu.Syntaxbased A lignmentofM ultip le Translations:Extracting Paraphrases and Generating New Sentences.H LT/NAACL.2003.
[18] Shinyama,Yusuke,Satoshi Sekine,K iyoshi Sudo and Ralph Grishman.Automatic Paraphrase Acquisition from New s A rticles[C]//Proceedings of the Second International Conference on Human Language Technology Con ference[H LT-02].2002:313-318.
[19] Vanderwende,Lucy,Deborah Cough lin and Bill Bolan.What Syntax can Contribute in Entailment Task?[C]//Proceedings of the PASCAL ChallengesW orkshop on Recognising Tex tual Entailment.2005.
