基于Web日志挖掘的个性化服务技术的研究
2010-06-12熊熙湖北工业大学计算机学院湖北430068
熊熙湖北工业大学计算机学院 湖北 430068
0 引言
World Wide Web自1989 年首次提出以来,Web网站无论是在访问量、规模上还是在网站设计的复杂度上都以惊人的速度增长着。这为人们提供丰富信息的同时,也为人们查找自己感兴趣的信息带来了困难。为此,如何针对Web网站内容、网站结构、用户访问日志信息等数据进行研究进入了一个新的阶段。Web日志挖掘技术便是运用数据挖掘的思想来对服务器日志进行分析处理,从而找出用户访问规律和内容喜好,为改进网站结构和内容提供了决策支持。同时,如何应用数据挖掘技术挖掘出有用的知识,更好地为用户服务,已经成为国际上的热门研究方向。本文主要论述了两个挖掘聚类算法相结合在网络用户个性化服务中的应用。
1 Web日志挖掘技术
什么是Web日志挖掘?Web日志挖掘或叫Web使用记录挖掘,它通过挖掘 Web日志记录,来发现用户访问 Web页面的模式。通过分析和探究Web日志记录中的规律,可以对不同背景、不同兴趣和目的的用户行为规律加以分析,来改进网站的组织结构及其性能,增加个性化服务,实现网站自适应,发现潜在的用户群体。Web日志挖掘己成为一个新的研究领域,在电子商务和个性化Web等方面有着广泛的应用。
Web日志挖掘的对象通常是服务器的日志信息,Web服务器的日志记载了用户访问站点的数据,这些数据包括:访问者的IP地址、访问的页面,页面的大小,浏览器类型,响应状态访问时间、访问方式、访问的页面、协议、错误代码以及传输的字节数等。每当网页被请求一次,Web Log就在日志数据库内追加相应的记录。热点的Web站点每天可以记录下数以百计字节的Web Log记录。Web Log数据库提供了有关Web动态的丰富信息。因此研究复杂的Web Log挖掘技术是十分重要的。
Web Log挖掘可以分成三个阶段:数据预处理、模式发现、模式分析,其系统结构如图1所示。
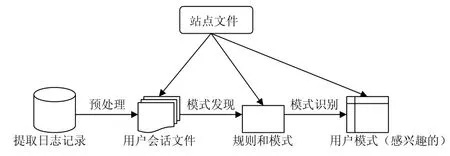
图1 Web日志挖掘技术系统结构图
2 数据预处理
Web Log挖掘首先要对用户的日志记录数据进行预处理,其任务是通过对来自不同数据源的各类用户访问数据的分析,组织转化为所必需的数据挖掘格式并保存起来,形成用户会话文件,等待进一步的处理。Web数据预处理过程共包括四个步骤:数据清洗、用户识别、会话识别和路径补充。
2.1 数据清洗
数据清洗工作与具体站点情况相关,它包括从多个服务器中对日志文件进行处理,删除与挖掘算法无关的数据,合并某些记录,对用户请求页面时发生错误的记录进行适当的处理等等。具体是从服务器日志文件中删除不相关的项和冗余信息,比如一些广告信息动画;辅助文件wav,jpeg,CSS,gif,PEG;脚本程序文件cgi,js;返回码404等,缩小日志挖掘的范围。将 URL地址表示规范化也是这个阶段的任务之一。URL地址规范化就是将相对的URL地址转换为绝对的URL地址,成为适当的数据格式以方便Web数据挖掘过程。
2.2 用户识别
用户识别的主要任务是从清洗过的 Web服务器访问日志所得到的中间数据中,识别出相应的用户。每一个用户需被准确地区分开的难点在于一些本地缓存、代理服务器、单位和个人防火墙的存在,访问站点的用户留下的是同样的IP地址。故姚洪波、杨炳儒提出了三则启发式规则来识别用户:不同的IP地址代表着不同的用户;若IP地址相同,但是操作系统类型或者浏览器软件不同被默认为是不同的用户;若当前用户请求的页面同用户已浏览的页面间没有链接关系,则认为存在IP地址相同的不同的用户。
2.3 会话识别
会话识别就是将用户的访问记录划分成单个的会话,不同用户访问的页面属于不同的会话,日志文件中不同的页面也属于不同的会话。由于在较长的时间里,用户可能多次访问了该站点,也很难知道用户是否为分开几次登录。所以一般利用最大的超时来判断用户是否已离开了该网站,若两次请求时间之间超过了一定的时间界限,就会被认为用户的一个会话已结束,开始了一个新的会话。
2.4 路径补充
由于高速缓冲存储器Cache的存在,一般在会话识别后还要确认Web Log中所有的重要访问记录都是否完整。若用户使用了缓存页面访问网页,则当前请求页与用户上一次请求页之间没有超文本链接,应当检查引用日志确定当前请求具体来自哪一页,通过这种方法将遗漏的页面补充添加到用户的会话文件路径中。总之,可以根据网站的拓扑结构图和引用日志提供的信息,对用户访问路径进行补充。
3 模式发现
模式发现是运用各种算法和技术对电子商务网站中预处理后的数据进行挖掘,生成模式。这些技术包括人工智能、数据挖掘、统计理论、信息论等多领域的成熟技术。可以运用数据挖掘中的常用技术,如分类聚类、关联规则、序列模式以及统计分析等等。网站中一旦用户识别和会话识别完成,就可以采用下面的技术进行模式发现。
3.1 分类
分类技术主要是从个人信息或共同的访问模式中得出访问某一服务器文件的用户特征。分类是将数据按照预先定义的类别进行划分。在Web日志挖掘领域中,分类主要是将用户配置文件归属给定的用户类别。分类技术要求抽取关键属性描述已知的用户类别。发现分类规则可以给出识别一个特殊群体的公共属性的描述,这种描述可以用于分类客户。例如:在某网站中访问浏览过的客户中有30%是女性。可以通过指导性归纳学习算法进行分类,主要包括决策树分类法、贝叶斯分类、最近邻分类法、k-相似相邻分类等技术。
3.2 关联规则
关联规则指发现用户会话中经常被用户一起访问的页面集合,这些页面之间并没有顺序关系,就是要找到客户对网站上各种文件之间访问的相互联系。如果关联规则中的页面之间没有超链接,则这是一个我们感兴趣的关联规则。挖掘关联规则通常使用Apriori算法或其变形算法,从事务数据库中挖掘出最大的频繁访问项集,这个项集就是关联规则挖掘出来的用户访问模式。
利用这些相关性,可以发现用户浏览的某些规律,更好的组织 Web网站的结构。在这里,经典的关联挖掘算法有Apriori算法。一般使用的叫做序列模式挖掘。
3.3 序列模式
在平时生活中,很多事情都属于按时间进行排序的序列这一范畴。比如,在现实超市中,某天顾客购买商品的活动序列;在电子商务网站中,客户对自己感兴趣的物品的点击序列;在网络中,用户对Web网站的访问序列等等。故在科学技术和商业的很多领域中,发现事件之间预期的序列关联显得越来越重要。
网络中的用户数量及其庞大,每人的兴趣爱好又不尽相同,其特点较为复杂。所以网站不仅需要分析用户在访问过程中最喜欢看哪些页面内容,还需要分析用户在浏览某些网页之后,接下来会对哪些其它网页更感兴趣;分析用户每次访问的网页间的联系后进行各种个性化服务,这样才能方便用户,进而吸引更多的用户。为了解决以上问题,便产生了序列模式挖掘。
序列模式挖掘的方法目前有很多种,比较经典的算法有三种:GSP算法、Prefix Span算法和SPADE算法。
3.4 聚类算法
聚类分析是从 Web访问信息数据中聚类出具有相似特性的客户,然后把具有相似浏览行为的用户或数据项归类,利用这类知识可以在电子商务中进行市场分割或者为用户提供个性化Web页面内容。在Web日志挖掘技术中,聚类分析主要集中于用户群体聚类算法和Web页面聚类算法。
聚类就是将物理或抽象的集合分组成为由类似的对象组成的多个类或簇,在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。通过聚类,我们能够识别密集的和稀疏的区域,因而发现全局的分布模式,以及数据属性之间的有趣的相互关系。数据对象算法的选择取决于数据的类型、聚类的目的和应用。如果聚类分析被用作描述或探查的工具,可以对同样的数据尝试多种算法,已发现数据可能揭示的结果。
3.4.1 用户群体聚类算法
用户群体聚类,不是指简单的根据IP地址得到用户所在地来给用户聚类,而是先对每一个用户访问过的所有Web页面进行聚类,即Web文档聚类;然后根据数据预处理过程中提到的启发式规则,判断每一个用户访问过的页面属于哪一网页类,从而将所有访问该网页类的用户聚成一类。所以,一个用户可以分别属于多个类。
首先要分析用户浏览行为和Web站点的表示。以L=<IP,ID,URL,TIME>的形式服务器日志。其中IP为用户的IP地址,ID为用户ID,URL为用户请求的URL,TIME为请求网页相应的浏览时间。设A为用户的浏览行为,LA.URL=URLA,n≥1,hits为目前客户浏览页面LA.URL的次数。有如下公式:
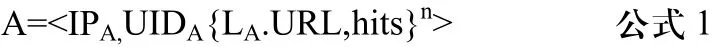
设hi,j是j用户在一段时间内访问第i个URL的次数;每一行向量M[x.,j]表示所有用户对URLx的访问情况;每一列向量M[i,y]表示用户y对该站点中所有的 URL的访问情况。因此,可以这样认为:行向量既代表了站点的结构,又蕴涵有客户共同的访问模式;而列向量则既反应了客户类型,也勾勒出了客户的个性化访问子图。那么,分别度量行向量和列向量的相似性,就能直接得到相关Web页面和相似客户群体,进一步分析还能获得客户访问模式,即频繁访问路径。据此就可以建立如下所示的URL-UserID关联矩阵Mm×n:

相似性的度量是根据 Hamming距离来判断的。对于M[i,j]>0,令M[i,j]=1。然后,计算向量间的Hamming距离。当Hamming距离越小的时候,其相似程度越高。设X,Y间的Hamming距离Hd(X,Y),公式为:
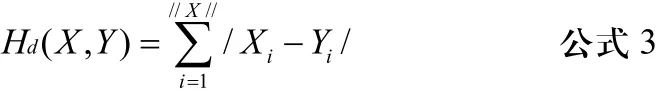
根据公式2,URL-UserID关联矩阵Mm×n的列向量M[i,y]是用户访问站点网页的个性化子图,具有相似访问个性化子图的用户即为相似用户群体。在电子商务网站中,根据交易数据库,若用户仅作了浏览而并未与商家成交,则关联矩阵列向量中的值是未成交的浏览次数。那么,此类用户群体为潜在用户群体;否则,则为在册用户群体。这是特殊情况。聚类时,首先对URL-UserID关联矩阵Mm×n进行预处理,然后计算列向量间的 Hamming距离,建立列向量间的距离矩阵。接下来根据公式4来计算阈值:
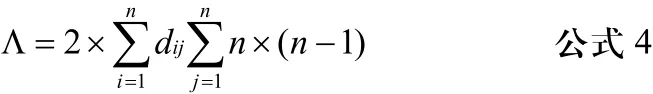
如果ijd<Λ,那么所有的满足这个条件的第j个用户和第i个用户被划分为一个类。同时,我们还要考虑到用户对某一网页的访问频率。因此,要对聚类的结果进行确认。可以运用下面的公式计算用户U和类C之间的连接强度来进行确认。
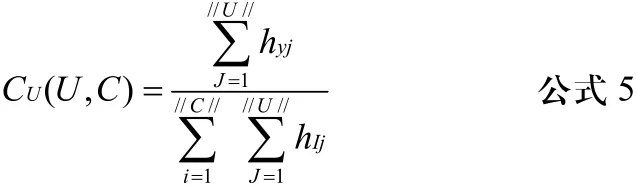
若使用公式5计算得到的连接强度CU(U,C)小于某个阈值(如2/C),那么,将这个客户U从类C中移出,并与其它被排除的U划为另一个类C2。
3.4.2 Web页面聚类算法
Web页面聚类是将内容相关的页面归类,它的主要作用是可以利用这些信息为用户的查询提供相关的超链接,后文中的个性化系统便是通过这个算法对用户进行推荐服务。
URL-UserID关联矩阵Mm×n的行向量M[x,j]反映了所有客户对本站点中不同页面的访问情况。如果客户对某些页面的访问情况相同或相似,那么,这些页面理应为相关页面,可以聚为一类。聚类时,同样先对URL-UserID关联矩阵Mm×n进行预处理,去掉所有值为零的行向量,对于可先令M[i,j]=1。再计算行向量间的Hamming距离,建立行向量间的距离矩阵Mm×Hmd。在对称矩阵M’Hd中,dij∈M’Hd(1≤i≤m,i<j≤m)表示第i个行m×mm×m向量和第j个行向量间的Hamming距离,对角元素的值为0。接下来根据公式4计算阈值,也可以按照具体情况自己指定阈值的大小。对于(1≤i≤m,i<j≤m),如果dij<Λ,那么就将第i个URL和所有的满足这个条件的第j个URL划分为一个类。
同样,与用户群体聚类算法提到的情况:上述聚类过程中没有考虑客户对某一 URL的访问频率,因此也要对聚类的结果进行确认。同理,根据公式5进行确认。若计算得到的连接强度CU(U,C)小于某个阈值(如1/C),那么,将这个客户U从类C中移出,并与其它被排除的U划为另一个类C2。
3.5 用户访问模式挖掘
经过上文所叙述的分类、关联规则、聚类算法、统计分析后,重点将用户群体聚类算法与 Web页面聚类算法相结合,我们就可以更快捷准确地得到每一类用户的访问模式(如表1所示)。
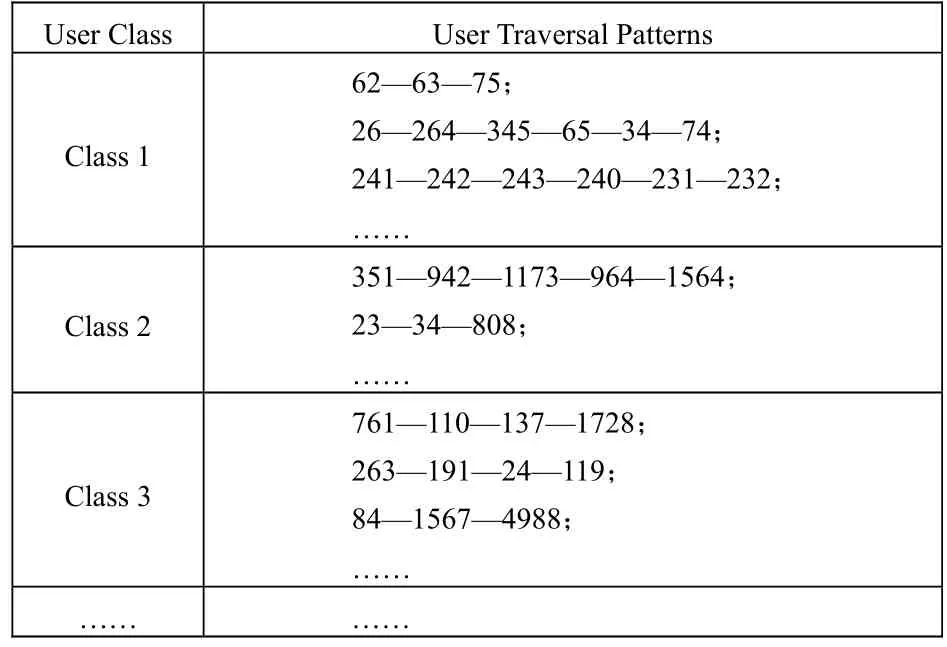
表1 挖掘出的每类用户的访问模式
4 模式分析
模式分析是基于Web的日志挖掘中最后一项重要步骤。我们通过模式发现、选择和观察,把从Web日志挖掘中得到的相关规则、模式和统计值转换为知识,再经过模式分析这一步骤得到相应的模式,即用户所需要的规则和模式,采用可视化图形的方法,以推荐页面的方式提供给访问该网站的用户,即个性化服务。
5 个性化服务的应用和发展方向
实现个性化服务系统较重要的一步便是用户访问模式的挖掘。这是一个较新的研究领域,它的应用非常广泛,主要应用在电子商务、站点系统改进、站点系统性能的改进、网络拓扑结构的改进和构建自适应站点、网络安全以及智能化等方面。
[1]Dimitrios Pierrakos,Georgios Paliouras.KOINOTITES:A Web Usage Mining Tool for Personalization.
[2]李文媛,林克正.Web日志挖掘研究[J].金融理论与教学.2008.
[3]Abraham,Ajith.Business Intelligence from Web Usage Mining [J].Journal of Information& Knowledge Management.2003.
[4]姚洪波,杨炳儒.Web日志挖掘数据预处理过程技术研究[J].微计算机信息.2006.
[5]陈志敏,沈洁.基于 Web日志的混合挖掘模型研究[J].扬州大学学报(自然科学版).2007.
[6]张涛,周爱武,谢荣传.基于概念格和关联规则Web个人化系统[J],计算机技术与发展.2008.
[7]Meng X F,Lu H Y,SG-Wrap;A schema-guided wrapper generator demonstration,Proc of ICDE'2002,Los Alamitos,CA:IEEE Computer Society Press.2002.
[8]宋麟,王锁柱.基于模糊多重集的Web页面与用户聚类算法研究[J].计算机工程与设计.2008.
[9]赵娜,田保慧,姜建国.基于加权矩阵聚类的Web日志挖掘算法[J].现代电子技术.2008.
