哈萨克语基本名词短语自动识别研究与实现
2010-06-05孙瑞娜古丽拉阿东别克
孙瑞娜,古丽拉·阿东别克
(新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046)
哈萨克语(简称哈语)基本名词短语自动识别研究是自然语言浅层句法分析的重要任务之一,在自然语言研究领域越来越受到重视。基本名词短语的识别可以简化句子结构,降低后续句法分析的难度,对机器翻译、信息检索、文本处理均具有重要作用。目前哈语词类标注系统基本实现了对哈语语料库进行词类标注的第一步,要深化哈语语料库语言学研究,必须在词类标注的基础上对语料库进一步做短语标注,使哈语语料库尽快转变为句法结构树库,从而创建功能更加完备的语言知识库,只有这样才能使语言研究者对语言现象进行定量分析。其他语言的信息处理实践也证实了这一点[1-5]。因此,现阶段系统研究短语内部结构特征,完成对哈语语料库短语级的标注是继续进行语料库深加工、建立大规模树库的先决条件。哈语基本名词短语的自动识别研究是哈语语料短语标注这一系统工程的重要组成部分之一,它的顺利实现必将对少数民族语言学、翻译理论等产生重要的推动作用。
本文在参考他人研究成果[ 6-10]的基础上,从哈语基本名词短语属性入手,设计了基本名词短语自动识别系统。研究内容主要包括两个部分:一部分是哈语基本名词短语标注语料库的建立。为减少人工对短语标注的工作量,根据哈语自身的特点,对哈语基本名词短语的结构进行研究,归纳出哈语基本名词短语结构规则,提出了16个相应的形式化描述规则群体,根据这些规则,编程实现对30万词级哈语语料库的基本名词短语标注。在此标注基础上,再通过人工从识别结果中修正标错条目,补充未标注条目,建立哈语基本名词短语标注语料库;另一部分是使用统计和规则相结合方法。通过互信息进行基本名词短语边界预测,再由基本名词短语构成规则对预测边界进行校对和修正并加入标注符,实现基本名词短语识别系统。
1 哈语短语特点
1.1 哈语短语属性

哈语是SOV(主—宾—谓)语言,哈语中用此作确定句子词序和语类的依据,理论上它可有四种排列,即SOV、SVO、OSV、OVS与汉语词序有很大不同,这给哈语短语识别带来了困难。
哈语的时态和人称附加成分非常丰富,因而有曲折短语IP,哈语最基本短语规则为:
Rule:IP→ SI
S→KP VP
KP→NP K
VP→KP V
其中:S-句子,KP-格短语,NP-名词性短语,VP-动词性短语。
1.2 哈语基本名词短语特征
哈语基本名词短语是由语义上能够搭配的两个或两个以上的实词带入表达某种结构关系的词组模式得出的句法单位。哈语作为一种典型的黏着性语言,单词的构成特点与汉语有很大的不同,哈语单词是通过在词干后按一定的顺序连接各种词缀(又称构形附加成分)来构成的,除了从外来语引进的词前缀外,语言本身不存在词前缀,而且哈语中各类后缀的连接有严格的规律可循。因此,根据哈语构词的特点,基本名词短语的识别不能单纯考虑标注的词性,要结合考虑哈语词缀,对哈语基本名词短语识别率的提高会有重要意义。本文对哈语基本名词短语的识别研究是在经过词性标注和构形附加成分切分的哈语语料库上进行的研究。
2 基于规则的基本名词短语识别
本文结合哈语的特点对基本名词短语定义如下:哈语名词短语是符合一定句法功能的非递归短语,每个基本名词短语都有一个核心(Head),基本名词短语内部所有成分都围绕着这个核心进行扩展。
2.1 规则获取
在基本名词短语结构规则中出现的词性标记,采用基于XML文件的哈语语料库词性(Pos)标注符号,即v动词,n名词,adj形容词,prep介词,ono 相声词,pron 代词,int 感叹词,conj 连词,num 数词,adv 副词,[ ]词性不明。本文通过分析语料库,结合《现代哈萨克语实用语法》[11]《现代哈萨克语结构研究》[12],以词类信息的词性及构形附加成分为核心,再附加一些限定条件,归纳了哈语基本名词短语内部构成规则。
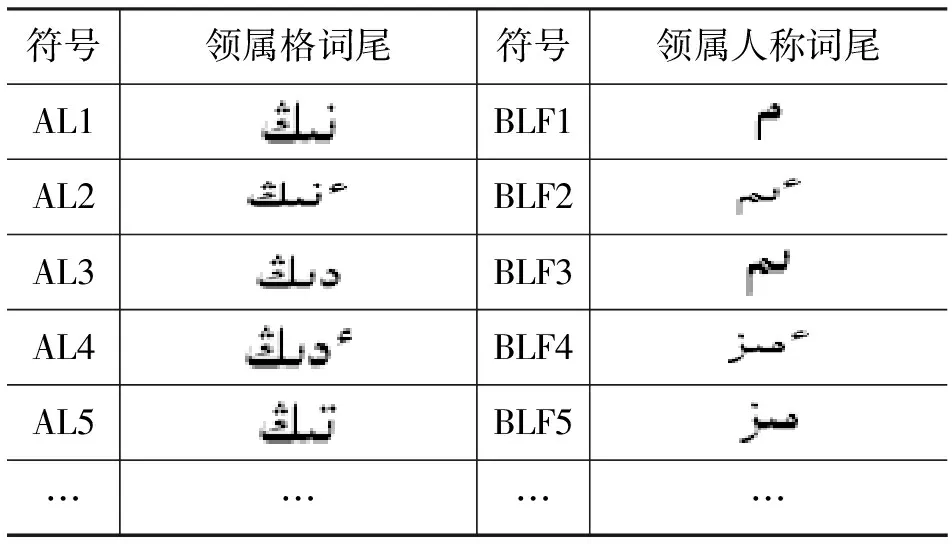
表1 基本名词短语构形附加成分
本文首先将基本名词短语的结构关系从语料库中提取出来,用统计归纳的方法,总结出以下10个基本结构:1) n+n; 2) n+conj+n; 3) pron+conj+pron; 4) pron+n; 5) adj+conj+adj; 6) adj+n; 7) adj+adv+n; 8) num+n; 9) v+n; 10)[ ]+n。再重点统计分析了基本名词短语构形附加成分中的后缀和词尾,制定了相应的符号标记,建立了基本名词短语构形附加成分集,提出了16个相应的形式化描述规则群体,由于篇幅有限,只列举部分具有代表性的附加成分和规则。表1 所示为部分基本名词短语构形附加成分。
部分哈语基本名词短语规则集,形式化表示如下:
R01 n+n[AL1|AL2|AL3|AL4|AL5|AL6]+n[BLF1|BLF2|BLF3|BLF4|BLF5|BLF6|BLF7|BLS8|BLS9|BLS10|BLS11|BLS12|BLS13|BLT14|BLT15| BLT16|BLT17]
R02 pron+ EC1| EC2| EC3| EC4| EC5+ pron
R03 pron+n[BLF1|BLF2|BLF3|BLF4|BLF5|BLF6|BLF7|BLS8|BLS9|BLS10|BLS11|BLS12|BLS13|BLT14|BLT15|BLT16]
R04 adj + EC1+ adj
R05 v+n[BLF1|BLF2|BLF3|BLF4|BLF5|BLF6|BLF7|BLS8|BLS9|BLS10|BLS11|BLS12| BLT15| BLT16| BLT17]
……
2.2 用规则标注语料
用规则标注语料,是对已做词性标注和构形附加成分切分的XML 文件进行基本名词短语标注。根据上下文环境用规则对每个词加短语标记B、I、O,“B”基本名词短语开始,“I”基本名词短语内部,“O”基本名词短语外部。标注过程如下:
(1) 提取XML语料库文本三个信息:词性:“pos”,构形附加成分:“affix”, 单词:“word”;
(2) 进行匹配规则,采用最长匹配原则;
(3) 匹配成功,对XML文本的每个词加入基本名词短语边界标记属性np=“B”or“I”or“O”。
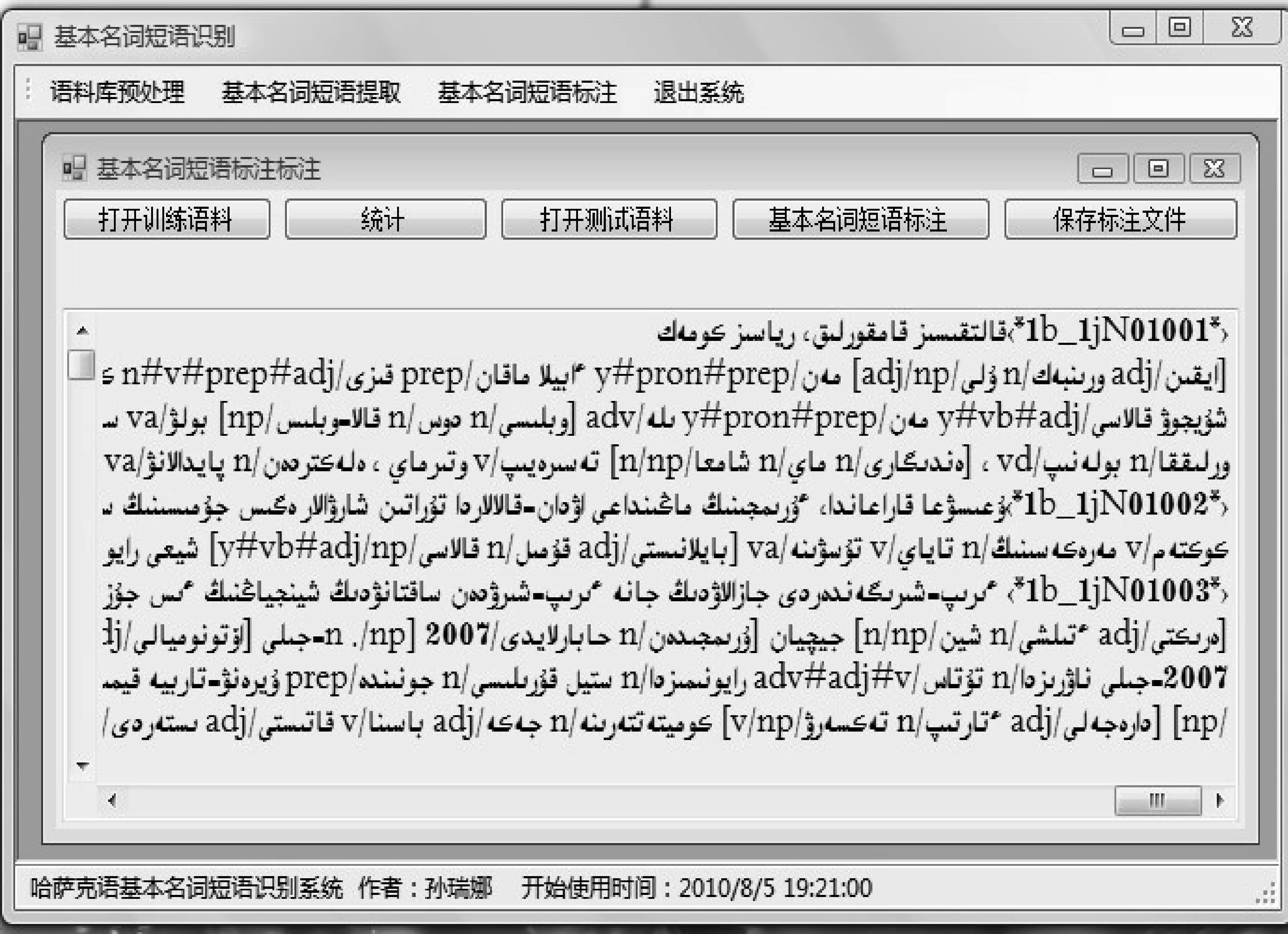
对31天的《新疆日报》XML格式的语料库进行基本名词短语标注,封闭测试准确率为80.2%,开放测试准确率为72.1%。规则方法标注界面如图1所示。

图1 规则方法标注界面
3 统计和规则相结合的方法
从规则方法标注的基本名词短语语料库中选择15天的语料(16万多词),人工方式对识别结果修正标错条目,补充未标注条目,建立统计方法所需的训练语料库。
首先对语料库文本进行粗切分,即按常见的切分标志,如用分号、逗号、句号、感叹号、问号进行切分,再采用互信息进行基本名词短语边界预测,然后通过基本名词短语构成规则对预测边界进行调整,加入标注符。系统结构如图2所示。
3.1 基于互信息方法的边界预测
互信息是信息论中的一个概念[13],它用来度量一个消息中两个信号之间的相互依赖程度。二元互信息是两个事件的概率的函数,公式如下:

(1)
那么对于一个有n个词的哈语语句“w1/c1/w2/c2/…wn/cn”,wi(0 图2 系统结构 图3 统计和规则结合方法的标注界面 (1) 对待识别的哈语语句“w1/c1/w2/c2/…wn/cn”设词串为t=w1w2…wn,对应的词性串为s=c1c2…cn,对于n元关系(n>2)词串可以简单地看作是一个t1=w1w2…wk-1元(k=1,2…,n-1)和一个t2=wk…wn元之间的二元关系,这里t1+t2=t。对于词性串同样有s1=c1c2…ck-1,s2=ck…cns=s1+s2。本文主要考虑词性。 (2) 设f(s)为词性串c1c2…cn在语料中共同出现的频率;p(s)为词性串c1c2…cn在语料中共同出现的概率。 根据最大似然估计,p(s) ≈f(s),对词性串s=c1c2…cn根据公式(3)可以定义其互信息为 (2) (k=1,2…,n-1) 如果词性串s结合十分紧密,那么f(s)就与f(s1)或f(s2)相差不大,据式(2)计算的词性串互信息就比较大;反之f(s1)和f(s2)就会远大于f(s),这样计算出的互信息就较小,因此我们通过互信息的值来预测基本名词短语的边界,在测试语料库中加入左“[”右“]”边界信息。 由于式(2)需要大规模的经过基本名词短语标注的语料库,目前这种语料很难获得,本研究只手工标注了部分语料,语料规模小对通过互信息得到的基本名词短语预测结果的准确率有很大影响,预测边界不能够保证获得的短语符合基本名词短语的语法属性,且预测的边界存在边界歧义,为了解决这个问题,结合规则的方法对统计得到的结果做进一步处理,通过基本名词短语构成规则对预测边界进行调整。 (1) 读入一句经边界预测后的哈语句子,从右向左扫描该句做括号匹配。 (2) 判断是否出现边界歧义的短语,即是否出现以下边界匹配歧义“[*[* *]”、“[* *]*]”、“[*[* *]*]”若没有出现,则对短语加入标注符“np”,否则转第(3)步。 (3) 调用基本名词短语构成规则库,对边界匹配进行选取。若没有匹配的规则,则删除该短语的歧义边界,否则转第(4)步。 (4) 若边界匹配后得到的词性串符合基本名词短语内部构成规则,则选取使得基本名词短语长度最大的边界匹配,删除错误边界,并加入短语标记“np”。 从《新疆日报》(其中包括文艺、体育和新闻等题材)语料库中抽取15天人工标注的XML格式语料 (1.78MB)做训练文本和15天的TXT格式语料(1.02MB)做测试文本,分别进行封闭和开放测试,封闭测试准确率为82.9%,开放测试准确率为74.2%,标注界面如图3所示。 一般情况下,基本名词短语识别评估系统有三个重要指标分别是准确率、召回率和F值。定义如下: a= 正确识别的基本名词短语的个数 b= 没有识别的基本名词短语的个数 c= 识别错误的基本名词短语的个数 (3) (4) (5) 两种方法的实验结果比较如表2所示。 表2 实验结果 表2表明:与基于规则的方法相比,统计和规则相结合的方法可以使精确率提高2.5%。虽然精确率提高幅度不大,但这说明结合互信息方法在一定程度上可以弥补规则方法的不足,提高精确率。 相对于精确率,召回率较小,因为与召回率相关的是未召回的基本名词短语数,对于系统的影响较小,而错误召回不仅错误识别了基本名词短语,还会波及后期将识别其他短语,因此本研究宁可增大未召回基本名词短语数,而尽量提高精确率,这是短语识别的一个原则,所以识别结果中召回率相对较低不能作为系统性能评价的主要因素。 从实验结果来看,识别方法基本令人满意,但因哈语中含有曲折短语,与其他语言的短语有很大区别,且哈语中用做确定句子词序和语类依据的有四种排列方式,与汉语词序有很大不同,这些对哈语短语识别带来了一定困难。因此,同其他语言在基本名词短语识别的性能相比,目前两种识别方法的精确率、召回率较低,尚需进一步提高。下面分析自动识别错误的几方面原因: (1) 目前语料库加工的校验工作未能跟上, 录入错误、词性标注及附加成分切分错误时而出现。后期修正语料库错误,重点完善词性标注及附加成分切分错误的不足,提高短语规则在识别中的作用。 (2) 对于基于规则的方法。通过经人工校对的正确的基本名词短语标注,对人工总结的基本短语规则的分布情况进行了统计分析,发现识别所用规则多集中在n+n,[ ]+n,pron+n结构中,对于出现错误多的规则,下一步考虑采用错误驱动策略对规则进行限制。 (3) 在标注语料库中还存在未登录的新词构成的短语,人工总结的规则存在不足,需要在后期结合考虑未登录词,改进并完善规则库。 (4) 对于统计和规则相结合的方法。使用统计方法进行基本名词识别所用的是二元模型,只考虑了相邻词之间的作用,忽略了远距离词对基本名词短语识别的影响,后期通过提高模型的元数降低错误,同时因为训练语料规模太小,对识别有一定的副作用,后期加大训练语料规模。 本文首先采用基于规则的方法对哈语语料库进行基本名词短语标注,在此标注基础上,再通过人工修正标错条目,补充未标注条目,建立基本名词短语标注语料库。进一步又尝试了基于统计和规则相结合的识别方法,通过互信息预测短语边界,再利用基本名词短语构成规则调整预测边界,识别结果达到了预期目标。在今后的研究中,将进一步扩大语料库规模,完善基本名词短语构成规则库,改进识别算法。 [1] Steven Abney. Parsing by chunks:In Pobert Berwick, Steven Abney, Carol Tenny eds.Principle-Based Parsing[C]//Dordrecht:Kluwer Academic Publishers, 1991: 257-278. [2] 赵军,黄昌宁.基于转换的汉语基本名词短语识别模型[J].中文信息学报,1999,13(2):46-63. [3] 刘芳,赵铁军,于浩等.基于统计的汉语组块分析[J].中文信息学报,2000,14(6):28-32. [4] 张昱琪,周强.汉语基本短语的自动识别[J].中文信息学报,2002,16(6):1-8. [5] 华沙宝,达胡白乙拉.对蒙古语语料库基本名词短语的定界与统计分析[J].中文信息学报,2005,19(5):52-58. [6] 周强.汉语短语的自动划分和标注[J].中文信息学报,1997,11(1):1-10. [7] 张锋,许云,侯艳,等.基于互信息的中文术语抽取系统[J].计算机应用研究,2005,22(5):72-73. [8] 俞士汶,朱学锋,段慧明.大规模现代汉语标注语料库的加工规范[J].中文信息学报,2000,14(6):58-64. [9] 李衍,朱靖波,姚天顺.基于SVM的中文组块分析[J].中文信息学报,2004,18(2):1-7. [10] 代翠,周俏丽,蔡东风.统计和规则相结合的汉语最长名词短语自动识别[J].中文信息学报,2008,22(6):112-117. [11] 张定京.现代哈萨克语实用语法[M].北京:中央民族大学出版社,2004. [12] 杨凌.现代哈萨克语结构研究[M].新疆:新疆大学出版社,2002. [13] Magerman D, Marcus M. Parsing a Natural Language Using Mutual Information Statistics[C]//Proceedings of AAAI’90,1990:984-989.
3.2 基于规则的边界调整
3.3 预测边界调整算法
3.4 系统实现
4 实验结果及分析
4.1 评价指标

4.2 实验结果比较

4.3 实验结果分析
5 结论
