嵌入式文本相关说话人识别算法的研究与开发
2010-06-05郭皓婷罗灿华李银国
郭皓婷, 郑 方,罗灿华,李银国
(1. 重庆邮电大学 自动化学院,重庆 400065;
2. 清华信息科学技术国家实验室技术创新与开发部 语音和语言技术中心,北京 100084)
1 引言
在嵌入式平台上实现文本相关说话人识别系统是有很大困难的,这是因为嵌入式平台的硬件条件不足以达到运算量大的说话人识别系统的实时处理要求。对于基于动态时间弯折(Dynamic Time Warping,DTW)算法的文本相关说话人识别系统来说,在普通PC机器上很容易达到实时的效果,但当将其移植到多普达掌上电脑P800(CPU主频仅为201MHz)上时,训练和识别速度就会很慢,很难满足实时性要求。在P800上,一般对于一个内容为三个中文字的语音(有效语音数约为100帧),训练时间需要10秒钟以上,而识别时间需要5秒钟以上。
为了使文本相关说话人识别系统在嵌入式平台上得以实用,必须在保证一定识别精度的前提下,提高训练和识别速度。目前,国内外针对嵌入式文本相关的说话人识别实现的研究,鲜有与运算速度相关的。
考虑到文本相关说话人识别本质上有两个部分,一是对说话人身份的识别(传统的说话人识别),一是对内容的识别(文本相关性)。基于此,有理由认为语音识别的一些技术可以借鉴。另一方面,分析基于DTW算法的说话人识别,不难看出,时间主要耗费在两个模板(特征序列)之间近乎逐帧的匹配计算上。目前最流行和最具有效果的说话人识别莫不是基于高斯混合模型(Gaussian Mixture Model,GMM),而语音识别则莫不是基于隐马尔可夫模型(Hidden Markov Model,HMM)的,这里的一个重要概念就是状态以及状态内特征空间的混合高斯描述方法。因此,引入状态对文本相关的说话人识别不失为一种可行的方法。
鉴于语音识别中的非线性分块(Non-Linear Partition,NLP)算法[1-4]对资源有限的语音识别有一定的效果,本文在研究NLP算法的基础上提出了改进的文本相关的说话人识别系统的建模和识别方式。实验结果表明,基于NLP算法的说话人识别系统具有可接受的识别效果,且训练和识别速度有较大的提升。
2 NLP算法介绍
NLP是这样的一种算法,它根据语音特征信息能量的变化情况,将特征序列分为相对平稳的几块。对不同的发音来说,语音特征信息的变化情况在时间轴上的分布不同,但对同一发音来说都存在着较好的稳定性,这样就起到了压缩信息和时间规整的目的[1]。在实验中,我们使用NLP算法划分语音内容为N块,并且对划分好的语音特征块分别使用高斯模型来刻画说话人的特性。这样就兼顾了语音内容和说话人的双重特性。
NLP算法描述如下:
设有语音观察序列X=(x1,…,xT),其中xt为K阶特征矢量。定义语音特征变化信息为[1]:
1≤t≤T-1
(1)
其中W=(W1,…,WK)是距离加权矢量。定义平均变化信息:
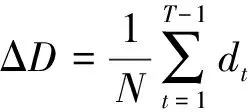
(2)
则当ni(1≤i≤N,令n0=0)满足下式时:
(3)
以特征序列(xni-1+1~xni)作为第i块,长度为ni-ni-1。每块特征可以看作是文本相关的说话人模型的相同状态的输出。
3 系统原理介绍
文本相关的说话人识别系统的原理见图1,整个过程包括训练和识别两部分。
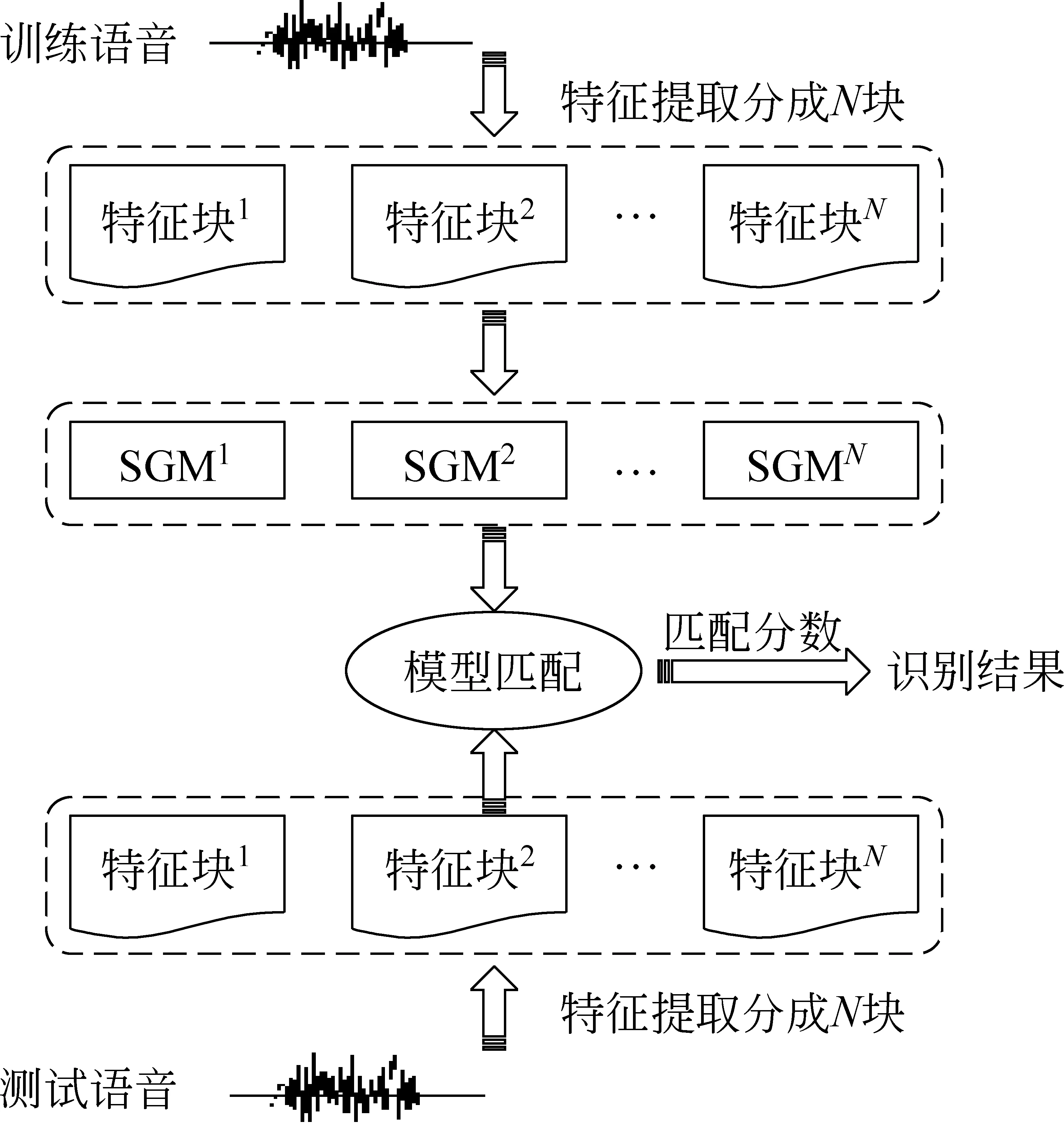
图1 基于NLP算法的说话人识别系统框图
在训练阶段,首先提取特征矢量,并按照上述规则将训练语音的特征序列分为N块,标注为分块1,分块2,……分块N,对每块分别使用单高斯模型(Single Gaussian Model,SGM)建模。在识别阶段,按照同样的方法将识别语音的特征序列分成N块,每块在相应的训练模型上面打分,最终得到最后分数。
3.1 语音模型的训练算法
在说话人识别系统中,常用的建模方式是高斯混合模型GMM[5]。GMM相当于单状态的隐马尔可夫模型。它的结构中蕴含了基于事件的说话人识别模型,具有明确的物理意义[6]。在GMM中,每一个分量可以理解成用来描述一类具有相近声学特征的语音事件,当分量数足够多时,可以用一个分量描述一个事件的分布。根据高斯函数的指数衰减特性和同说话人、同事件的帧间距离最小的假定,容易知道理想情况下,从描述一个事件的高斯分布生成属于另一个事件的矢量的概率接近于零。
本实验使用的模型是单高斯模型SGM,用它来表征说话人的信息。高斯密度函数用公式表示为:
其中X=(x1,…,xT)
(4)
我们假设每一维的特征矢量都是相互独立的,只考虑Σ为对角矩阵的情况。这样,训练的任务就是计算每块语音中的两个参数:矢量中心μ=(μ1,μ2…,μK)和对角协方差矩阵Σ=(Σ1,Σ2…ΣK)。
训练的具体步骤如下:
1. 对每帧训练语音计算得到其特征向量,从而获得整段语音对应的特征序列,对得到的特征序列按照NLP分块原则将其分成N块;
2. 对每个训练语音,从i=1到N进行分块训练,第i块语音的模型即为:
μi=(μi1,μi2…,μiK)
Σi=(σi1,σi2…,σiK)
其中:
(5)
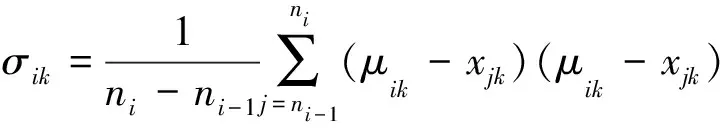
(6)
3. 当训练多次的时候,我们可以对模型进行简单的处理:假如,第一次训练语音的第一块有m11帧,模型为(μ11,Σ11);第N块有m1N帧,模型为(μ1N,Σ1N)。第二次训练语音的第N块语音有m2N帧,模型为(μ2N,Σ2N);这样,两遍训练的新模型的第i块语音参数即为:
(7)
(8)
多次训练的方法以此类推。最终可以将一个人的多次语音训练成一个模型。
3.2 识别算法
原先采用的识别算法大都采取逐帧比较的方法,或者采取限制路径、剪枝算法等手段。本文采取的打分策略是将测试语音的特征矢量序列划分为与训练时相同的N块,每一块分别在对应的训练模板上打分。
识别过程如下:
1. 测试语音和训练语音如果帧数差别太大就直接拒绝。
2. 对待识别语音O=(o1,…,oT),将其非线性分为N块,按照下面的公式计算它的得分:
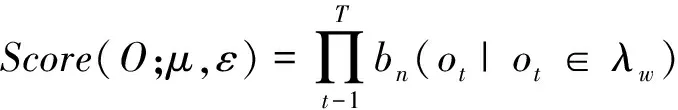
(9)
3. 公式(9)的结果没有考虑到测试语音的帧数对识别结果的影响。如果按照公式(9)的结论,帧数越多,分数会越大,这个显然是不合理的,为此,对识别分数做归一化处理:
(10)
(10)式计算的得分即为识别的最终分数,归一化的处理同时也对每块语音的帧数进行了综合。
对于确认系统而言,需要判断最终分数与规定阈值之间的关系:如果得分大于阈值则予以确认,否则予以拒绝。阈值的设定要看实际应用中系统对安全的要求。
4 实验验证
为了验证算法的性能,我们进行了三组实验。实验选用的数据库介绍如下:
在实验室环境下,由40个人发音10个文本,每个文本每人发5遍,其中,女性22人,男性18人。每个文本包含两个中文字或三个中文字的语音内容,例如:“中国”,“您好”,“马拉松”等。两个中文字和三个中文字的语音各有5个。采样率是16KHz,特征矢量采用是16维的MFCC和16维的一阶MFCC差分。
实验1:分块准则中权重的选择
NLP算法的关键在于分块,分块准则的优劣直接影响着系统的性能。我们分块的依据是根据特征间的变化,按照公式(1)划分的。可以看出,公式(1)中的权重Wk对分块合理与否起着至关重要的作用。在我们的实验中,权重的选择有以下几种[7](1≤k≤K):
1. 索引加权:Wk=k2;
3. 对数索引加权:Wk=[ln(ck+1)]2,常数c=2,1或者1/2;
实验中我们选择分块数M=4,验证不同权重选择对系统性能的影响,测试结果见表1。

表1 不同权重对系统的影响(训练1次)/%
表1的结果验证了每一维的倒谱系数所含的有用信息是不一样的,所以对各维系数要使用不同的权重。从表1中可以看到,方差倒数加权(即系数4)取得了最好的性能,因此在以后的实验中,分块权重的选择就以此为标准。
实验2 :训练次数对识别结果的影响
由于所用的数据库文本只有两个中文字和三个中文字的情况,训练语音非常短,这样就会造成模型刻画的不精确。现在分别统计训练一次、训练两次和训练三次的情况下系统的等错误率(Equal Error Rate, EER)。识别判决的准则是,只有文本和说话人这两个信息都匹配的时候才能接受,其余情况都予以拒绝。测试结果见表2。

表2 训练次数对系统的影响
按照这种判决准则,则会出现四种错误:文本相同,说话人也相同的情况,系统予以拒绝(错误拒绝);文本相同,但是说话人不同的情况下,系统予以接受(错误接收);文本不同,说话人相同的情况下予以接受(错误接收);文本不同,说话人也不同的情况下予以接受(错误接收)。针对表2中训练次数为3的实验,对系统错误类型的具体分析结果如表3所示:
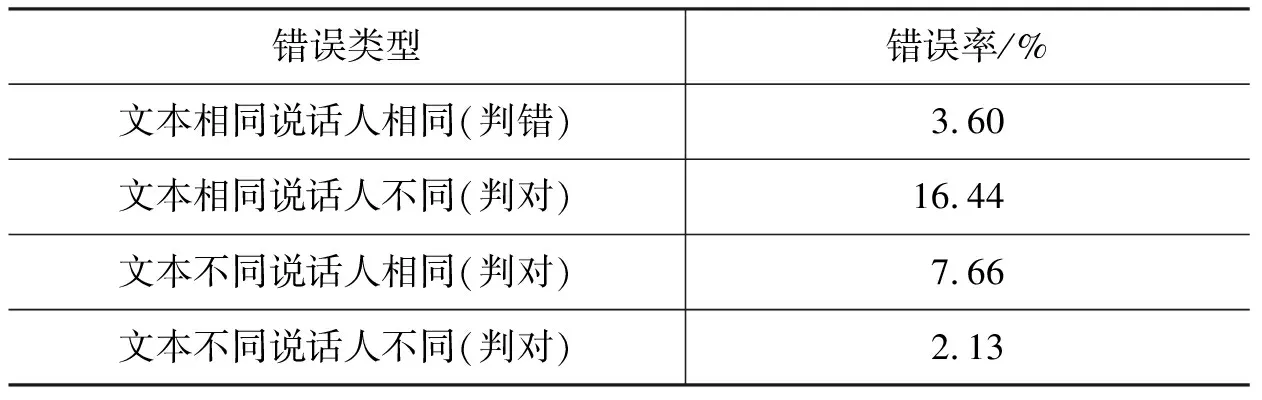
表3 错误结果分析
表3中,第一种错误是错误拒绝(False Rejection),后三种错误都是错误接受(False Acceptance)。表中统计的比例,是相应类型的错误个数占其试验样本总数的比例,分别对应错误拒绝率或错误接受率。
从表2的结果可以看出,当训练一次的情况,系统的性能并不理想。但是当训练二次和三次的时候,系统的识别率得到很大的提高。我们分析其理由是,实验选取的语音内容只包括两个或者三个中文字,时间只有一秒到两秒,有效语音帧数则只有50—150帧,因此,一次训练获得的模型,很可能由于有效语音帧数太少而训练得不够充分。而当训练次数增多时,对模型的刻画会随着参与训练的语音帧数的增加而更加充分,识别率的提高也是必然。在实际的使用过程中可以采用多次训练的方式提高系统的性能。但是由表3的结果可以看出,在训练次数增加的情况下,虽然对语音的刻画越来越精确,但是说话人的个性特征却没有得到很好的突出,使得系统对说话人信息的判别不太准确。
实验3 :算法的时间开销
我们引进NLP的思想,就是希望通过压缩信息和时间规整,以期达到提高系统运行速度的目的。因为DTW算法以其简单有效,小计算量而得到了广泛的应用,并且效果和HMM算法相差不大,因此,本论文的基线系统,是采用了传统的DTW算法的说话人识别系统。
时间消耗测试所用的平台是多普达(dopod)掌上电脑P800的模拟器,P800的CPU主频为201MHZ,其存储空间为128M的ROM和64M的SDRAM。测试结果见表4:

表4 DTW和NLP算法时间消耗比较
表4的试验结果是训练和识别时,每帧所消耗的时间。对于一个内容为三中文字的短语语音来说,其有效帧数大约为100帧,那么其训练时间由大约12秒降低到大约3秒,速度提高了4倍;识别时间由大约4.5秒降低到大约2秒,速度提高了2.5倍。而且,对多遍训练的情况来说,基线系统由于训练了多个模型,导致训练和识别的时间会随着训练次数增加而线性增长;而采用NLP的系统只保留整合后的一个模型,故识别时间随着训练次数的增加几乎没有增长。由于多遍训练的普遍存在(为了提高识别性能),这大大增加了系统的实用性。
5 展望
混合高斯模型能够较好地刻画说话人的特性,当高斯混合数越多的情况下,刻画也就越准确。本实验采取的是单高斯模型,所以对目标说话人区分能力较弱,因此一个直观的想法就是增加混合数目。但是,对于嵌入式应用中训练遍数不多的情形,这必然引起训练数据不足的问题。一个解决的方法是引入通用背景模型(Universal Background Model, UBM)并利用自适应算法进行说话人模型训练。当然,引进UBM势必会增加系统的时间开销,因此我们计划在未来的研究中,UBM的训练脱机完成,说话人模型的训练采用快速自适应算法并仅取最大似然的前几个高斯混合,这可以大大降低建模过程的时间消耗,而不至于影响说话人模型的描述精度。
[1] 蒋力. 基于概率统计模型的非特定人语音识别方法与系统的研究[D]. 北京:清华大学,1989.11.
[2] 郑方.非特定人连续数字识别方法与汉语语音数据库的研究[D].北京:清华大学,1992.
[3] 郑方,吴文虎,方棣棠. CDCPM 及其在语音识别中的应用[J]. 软件学报, 1996, 7:69-75.
[4] Thomas Fang Zheng, Chai Haixin, Shi Zhijie. A real-world speech recognition system based on CDCPMs[C]//Int’l Conf. on Computer Processing of Oriental Languages (ICCPOL’97), 1997, 1: 204-207.
[5] Reynolds A. Reynolds. Speaker identification and verification using Guassian mixture speaker models[C]//Speech Communication. 1995, 17(1-2): 91-108.
[6] N. Z. Tisby. On the application of mixture AR hidden Markov models to text independent speaker recognition[C]//IEEE Trans. Signal Processing, March 1991, 39(3): 563-570.
[7] Zheng, F., Wu, W.-H., Fang, L.-T., A Log-Index Weight Cepstral Distance Measure for Speech Recognition [J]. J. of Computer Science and Technology (JCST), 1997, 12(2):177-184.
