基于HTML卡方算法的垃圾邮件过滤器设计
2010-05-28孔颖
孔 颖
(浙江科技学院信息与电子工程学院,杭州310023)
电子邮件作为一种高效、经济的现代通信技术手段,已成为互联网最大的应用项目之一。然而,随之产生的垃圾邮件像瘟疫一样蔓延,污染网络环境,占用大量传输、存储和运算资源,影响了网络的正常运行,严重干扰了人们的正常生活,浪费用户的时间、精力,甚至造成很多额外的经济支出和信息安全隐患。垃圾邮件的判定和邮件的接收者有很大关系,不同用户对同一邮件的判断结果可能会存在差异。在《中国互联网协会反垃圾邮件规范》中,将垃圾邮件定义为具备如下部分或全部特征的电子邮件:
1)收件人事先没有提出要求或同意接收的广告、电子刊物、各种形式的宣传品等宣传性的电子邮件;
2)收件人无法拒收的电子邮件;
3)隐藏发件人身份、地址、标题等信息的电子邮件;
4)含有虚假的信息源、发件人、路由等信息的电子邮件;
5)含有病毒、恶意代码、色情、反动等不良信息或有害信息的电子邮件。
基于内容的机器学习判别方法是当前解决垃圾邮件问题的主流技术之一,包括Ripper、决策树方法、Rough Set方法等基于规则的方法,和 Bayes、SVM、动态马尔可夫建模(Dynamic Markov Modeling,DMM)、Winnow等基于概率统计的方法[1-2]。这些方法的基本思路是:将垃圾邮件过滤看成一个两类问题,研究从样本邮件出发寻找规律(或分类器),利用规律(或分类器)对未知邮件进行预测。随着人工智能、计算机技术的创新和发展,这种将机器学习方法应用于邮件分类领域一直成为当前研究的热点和重点。
本文在简要介绍基于HTML的卡方特征提取算法的基础上,将卡方特征提取和HTML标签相结合,通过神经网络建立模型,对邮件进行预测,得到了较好的实验结果。
1 邮件特征提取
1.1 HTML标签分类
首先需要将收集到的邮件转换为H TML形式,这样可以将邮件特征使用标签来表示。由图1可以看到一封浏览器接收到的邮件示例。
将图1所示的邮件转换为HTML格式,由于文本文件的通用性,所有的邮件均可转换为HTML代码。而HTML为各类标签所组成,对于不同的标签而言,其所代表的含义各不相同,当然,处于标签中的内容所代表的含义也不同,表1大致给出了基本标签所代表的含义。

图1 邮件示例图Fig.1 An example of an e-mail

表1 基本标签含义表Table 1 Meanings of basic tags
当然,标签中许多都是用于格式控制的,对于文本内容没有任何影响,不会使文本特征丢失。将邮件转换格式后为了便于进一步进行特征提取,需要对某些细节进行一些处理,其中主要的方式为:去除含有图片的标签;去除超链接的标签;不考虑标签中与附件有关的内容;将特殊符号转化为特殊的标签。
完成了细节处理后,需要对各种标签进行分类,以便于对不同标签内的内容赋予不同的权值,达到最终的特征提取目的。根据HTML语言的特点,在标签分类时使用如表2所示的方式。
特征提取将标签中最为相关的特征集中在一个数据集中,考虑到整个数据集包含所有邮件的特征,如邮件中的单词、图片和它们在预处理时所产生的标签等[3]。由于特征提取广泛用于文本的分类,通常这些分类方法也可以用于处理垃圾邮件,在本实验中采用了2种提取法:TF-IDF算法和卡方分布算法。
1.2 卡方特征提取
卡方分布处理的是某个特征的度与整个数据集之间的关系[4]。如w是数据集C(由两部分构成)中的一个特征,则w的卡方值可用式(1)给出
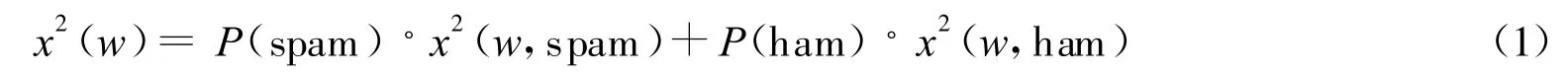
式(1)中P(spam)和P(ham)分别表示垃圾邮件和正常邮件在数据集中出现的概率,这样就可以给出特征w在整个数据集中的卡方分布,如式(2)所示:
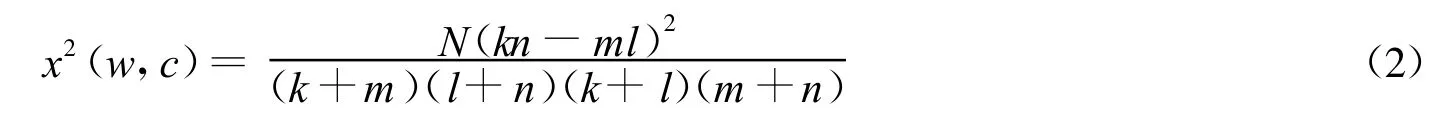
式(2)中:k为正常邮件数据集中包含特征w的邮件数量;l为垃圾邮件中包含特征w的邮件数量;m为正常邮件数据集中不包含特征w的邮件数量;n为垃圾邮件数据集中不包含特征w的邮件数量;N为正常邮件数据集中所有邮件的数量。同样的,所有的特征的卡方值均取其最高值,最终这些值均作为神经网络中的一个节点。
1.3 TF-IDF加权算法
目前加权使用最广泛的算法 ——TF-IDF加权算法[5-6]:
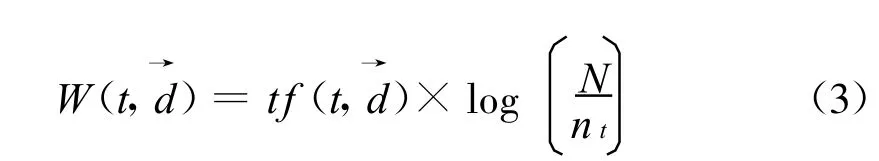
式(3)中,W(t,d)为特征项t在邮件d中的权重;tf(t,d)为特征项t在邮件内容中的词频;N为训练文本的总数;nt为训练邮件集中出现特征项t的邮件数。用TF-IDF算法来计算特征词的权重值是表示当一个词在这篇邮件中出现的频率越高,同时在其他文档中出现的次数越少,则表明该词对于表示这篇文档的区分能力越强,所以其权重值就应该越大[7]。将所有词的权值排序,根据需要选择特征项。
为消除文档长度不一对文本表示方式的可能影响,往往需要对加权后的向量进行规范化处理,使得权值落在[0,1]中。即:

表2 标签相关特征Table 2 Characteristics of tags

1.4 基于LVQ神经网络的邮件分类器设计
LVQ神经网络是一类混合神经网络,它分为有人值守和无人值守[7]。本实验中将模型分为两层,第一层是竞争层,该层中每个节点表示一个子集;而第二层为输出层,每一个节点均为一个集。每个集可以划分为若干个子集。由于LVQ神经网络可以通过结合不同的子集创造复杂的界限,故适合于将垃圾邮件从若干不同的子集中分辨出来。以下为筛选算法:
1)初始化向量权重W={W1,W2,…,Wn},学习率α∈[0,1]。
2)从训练邮件集中选取一个示例,计算它各个向量之间的距离,分别取欧几里德距离和余弦距离,这些可以表示不同文本之间的相似性[8]。其中余弦距离可用式(5)表示:
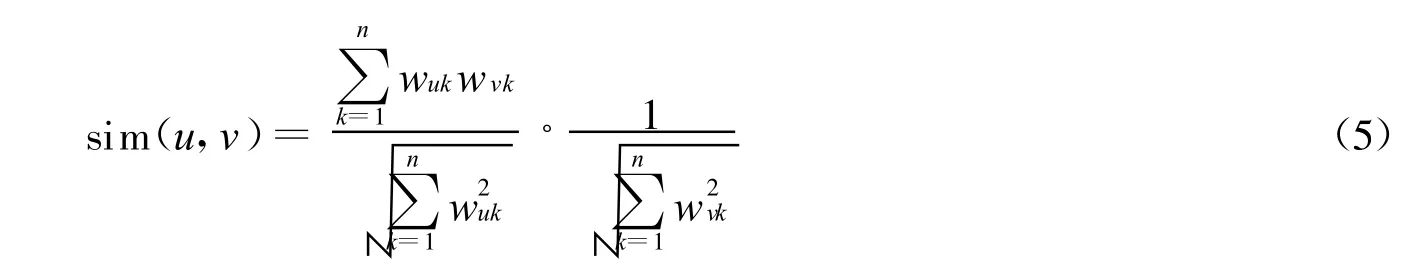
3)比较不同权向量之间的距离,在结果中,神经元之间最为相似的取值1,其余隐藏层的输出层取值0。

4)调整距离,如果一个输入示例属于数据集r,那么在数据集s中神经元c拥有最大的权值,然后根据式(7)调整各个权值:
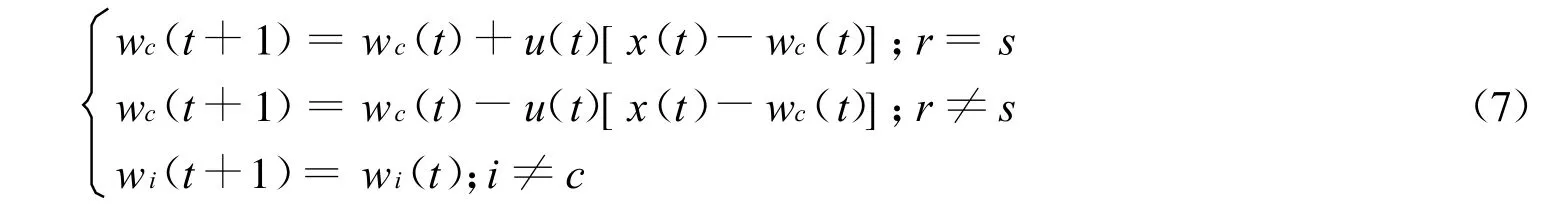
5)修改学习率U(t),当重复增加时降低U(t)。
6)检查停止状况,并确认重复的次数足够多。
使用上述方法提取特征之后代入LVQ神经网络进行计算,使用MATLAB可以模拟出如图2的LVQ神经网络。
1.5 过滤原理
邮件预处理是建立在训练模型的基础上的,因为用LVQ神经网络建立的模型是建立在许多学习样本邮件基础上的,需要巨大的计算资源。因此,用于建模的邮件如何进行预处理十分关键。
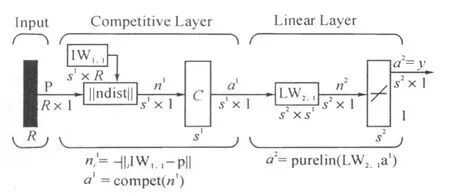
图2 LVQ神经网络Fig.2 LVQ neural network
在特征提取过程中,通过把普通的邮件转化成HTML标签形式,减少分类过程中产生的特征向量数,把每个特征所出现的概率用到卡方算法中,最后再通过LVQ神经网络建立模型,进行邮件分类。电子邮件过滤模型如图3所示。
2 实验结果分析
评价一个解决分类问题的模型是否适用的一个直接手段就是看它的错分率,即错误分类数与总记录数的比值。所示必须测量用来建立模型和在建立模型过程中没有用到的记录组成的测试样本,选择最具有普遍意义的而不是最适合训练样本的模型。
考虑N封待测试邮件(Ns封垃圾邮件和N b封垃圾邮件,N=Ns+Nb),在算法邮件分类模型中,垃圾邮件被分类器正确判定的有A封,误判的有B封;正常邮件被分类器正确判定的有C封,误判的有D封,显然Ns=A+B,Nb=C+D。根据定义,有下列各式成立:
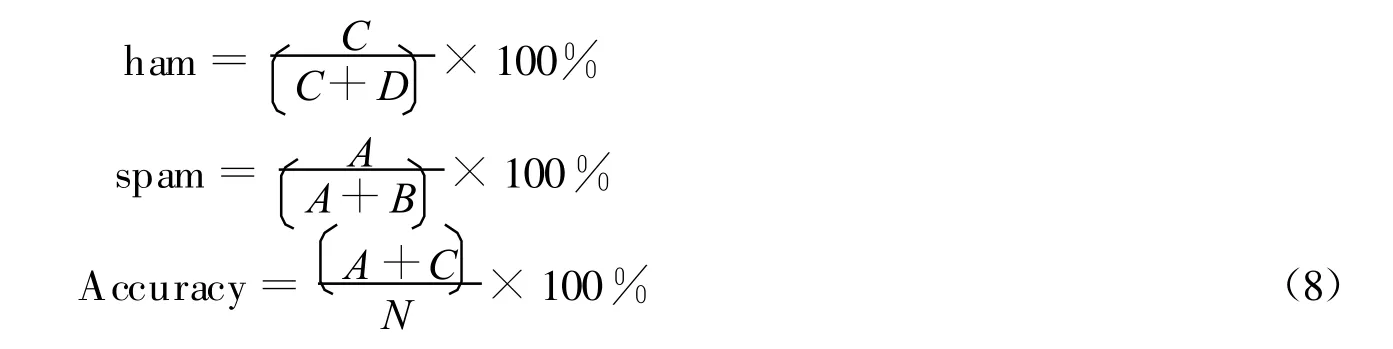
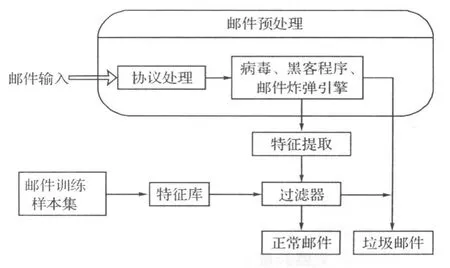
图3 电子邮件过滤模型Fig.3 Filtering model of an e-mail
垃圾邮件过滤应用模型采用ham%、spam%和Accuracy等传统分类指标,来分析特征提取和特征值计算方法、训练模型的选择对邮件分类模型的影响。
本次实验使用的是SEWM2008比赛中的数据集作为评测数据集邮件样本。抽取样本中的4 000封,其中正常邮件有3 120封,垃圾邮件有880封。分别用基于HTML的卡方和TF-IDF两种不同的特征提取方法,把得到的邮件特征向量通过LVQ神经网络模型进行过滤,从而得到的实验结果,如表3所示。

表3 各实验结果比较Table 3 Comparison of experimental results
从表3实验结果的比较可以看出,在数据集足够大时,采用LVQ神经网络的分类器对于不同方法提取的数据集均有较好的结果,其中采用卡方分布法提取的数据集在处理结果方面略微优于传统的TFIDF提取的数据集。实验还表明,不管是正常邮件分类、垃圾邮件分类还是整体分类,都具有较高的准确率。
3 结 语
从基于HTML的卡方特征提取方法和LVQ神经网络分类器结果可以看出,该模型是一种较好的垃圾邮件处理系统。通过转换邮件文本为HTML代码,便于处理其中内容,而使用LVQ神经网络的分类器,在数据集足够大时所得结果往往优于同等情况下的其他分类器,这在实际应用时具有一定的参考价值。
[1] YIH W T,MCCANN R,KOLCZ A.Improving spam filtering by detecting gray mail[C]//Fourth Conference on Email and Anti-Sparn.Mountain View,CA:CEAS,2007.
[2] CLEARY J G,WRITTEN I H.Data compressing using adaptive coding and partial string matching[J].IEEE Transaction on Communications,1984,32(4):396-402.
[3] ZEITOUN I K,YEH L.Join indices as atool for spatial datamining[C]//International Workshop on Temporal,Spatial and Spatio-Temporal Data Mining,Lecture Notes in Artificial Intelligence.Paris:Springer Press,2007:102-114.
[4] 刘洋,杜孝平,罗平,等.垃圾邮件的智能分析、过滤及Rough集讨论[R].武汉:第十二届中国计算机学会网络与数据通信学术会议,2002.
[5] 王斌,潘文锋.基于内容的垃圾邮件过滤技术综述[J].中文信息学报,2005,19(5):1-10.
[6] 程红蓉,秦志光,万明成,等.图像垃圾邮件中文本区域的自动提取方法[J].解放军理工大学学报:自然科学版,2009,10(3):258-261.
[7] 王龙,李晓光,钟绍春.基于K-近邻法及移动AGENT技术的垃圾邮件检测系统研究[J].计算机应用研究,2009,26(7):2630-2632.
[8] 万明成,耿技,程红蓉,等.图像型垃圾邮件过滤技术综述[J].计算机应用研究,2008,25(9):2579-2582.
