开发人员升级至ASE 15.0的10大理由(五)
2010-05-08
以下的简略模式是一种可行的实现。
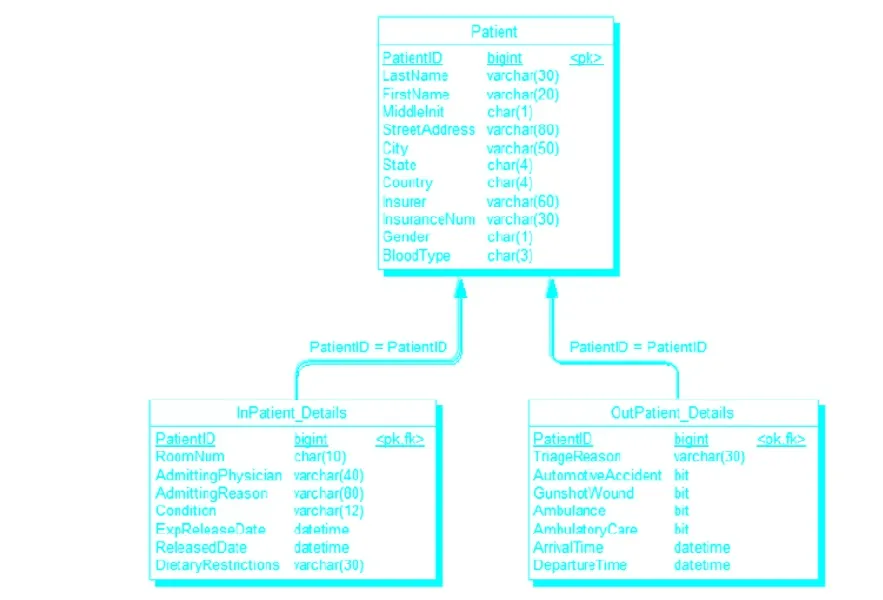
图2 针对不同病人的对象类规范化的物理模式例子
应用程序开发人员的问题是病人信息很可能使用不同的应用程序输入,或同一应用程序中不同的屏幕因为需要不同的工作流程来完全录入必要的病人信息。作为对象模型,开发人员更容易从“patient”父类中抽取出住院或门诊病人,等到将数据保存至数据库时,住院或门诊病人对象在中间层被集成至一个单独的实体中。对象—关系映射需要在某点发生,通常是在中间层。但是在一些情况下,开发人员会使用像Hibernate这样的数据库抽取层,它在介于中间层逻辑和数据库本身的数据库接口层进行对象—关系映射。该层中的对象—关系映射操作常常很麻烦而且效率不高。上例中伪操作可能是:
(1)Get new patient id.
(2)Insert patient information.
(3)If outpatient, insert outpatient information.
(4)If inpatient, insert inpatient information.
这可能会导致抽取层的多次网络交互。有许多抽取层(包括Hibernate)高度依赖于替代触发器来实现最终的数据语义模式分解。该逻辑(从抽取层的角度)被简化为对视图的一个单独插入,如下:
(1)Insert all patient information into patient view.
(2)Instead of trigger fires with following logic.
a.Get new patient id.
b.Insert patient data into patient table.
c.If outpatient, insert outpatient information.
d.If inpatient, insert inpatient information.
这不仅能加快开发速度,还能在应用程序和数据库模式之间提供一个常常需要的抽取层。通过该方法,对任一方的小改动都有可能无需更改对方。
5.2.2 手工数据分区
替代触发器的另一用途就是提供了普通的统一接口来进行手工表分区,以便对应用程序或最终用户隐藏分区。考虑一个至少要将数据在线保留7年的财务应用软件。如果都存在一张表中,则表的大小会以极大的比例增长。常见的技术(尤其在DSS应用程序中)是用单独的物理表来实现每月或每年的数据,如tran_hist_2005、tran_hist_2006、tran_hist_2007、tran_hist_2008……创建一个统一的“transaction_history”视图用来连接单独的表,例如:
create view transaction_history as
select * from tran _hist _2009 union all
select * from tran _hist _2008 union all
select * from tran _hist _2007 union all
select * from tran _hist _2006 union all
select * from tran _hist _2005
…
“分区”随着时间的改变可有不同的权限。例如,去年,一个用户插入(或更新)tran_hist_2008表中的数据。今年,可废除大部分用户的插入、更新和删除权限,防止意外数据修改。ASE中的语义分区不支持不同分区、不同权限。
“分区”可拥有不同的索引。例如,由于更有可能是OLTP或混合负载处理,最近的交易记录与常见的查询有不同的查询参数。较早的“分区”可能需要不同的索引来支持更复杂的DSS类型查询。ASE的语义分区不支持不同分区、不同索引。
“分区”可与单独的命名缓存绑定。例如,较早的数据和索引可能会冲刷缓存中较多当前的数据。通过使用单独的物理表,较早的数据能与较小的命名缓存绑定,在缓存中最大程度保留当前的数据操作。
每个“分区”本身还可以是语义分区表。例如,如果表是按年进行物理分区的,单独的表可根据月份来进行语义分区,进一步改善维护时间。或者语义分区可在不同的键上完成, 例如客户/交易类型,或者甚至用另一种分区类型(哈希而非范围)。ASE中的语义分区不支持多层级分区。
这些是额外的表分区优势,诸如隔离维护每个分区的行动。但是,它存在一个大问题每当一个时间段趋近结束时,不仅需要创建一个新的分区,而且涵盖了分区的视图必须更改,加入新表并移除旧表。虽然修改视图定义并不需要花一秒钟时间,但必须在无人使用该视图时完成,所以必须在行动时强制暂停。另外,真正完整的改变需要以下内容:
(1)创建新的“当前”分区表、索引和用户权限。
(2)更新视图定义,删除并重建的同时修改替代触发器和用户权限。
(3)去除最近的“当前”分区的权限。
(4)从最近的“当前”分区中支持OLTP的索引。
(5)在最近的“当前”分区中增加支持DSS查询的索引。
为了改变视图定义而造成的维护和缩短服务时间要求是本方法的劣势之一,还可能由于改变了对象ID而对预编译对象(例如存储过程)造成不确定的影响。另一个明确的考虑就是因为优化器并不知道每个分区与什么查询语义相关,结果就可能常常出现对所有数据的访问,频繁创建包含任意谓词结果的工作表,并将工作表用于查询处理中。若是语义分区,则优化器了解分区键,能避免中间的工作表并能执行分区消除。虽然表的分区是像上述那样离散的集合,而同样的键将触发优化器去了解没有可用的结果,并且可缩短union all查询的周期。
6 可配置的DSS查询优化
关于ASE 15,经常被问到的问题之一是对开发人员都有哪些特性?赞成开源系统的人们倾向那些产品所吹捧的“开发人员”特性,并抱怨主流的RDBMS系统长时间关注DBA,已经忽略了开发人员。那些产品中的一个严峻缺陷就是查询优化,查询优化器100%的是完全关注开发人员的特性。毕竟,日常运营的DBA通常不会关心查询优化器运行得如何,只要系统性能在可接受的资源消耗范围内。正是开发人员才去考虑该产品是否支持星型连接等。
如果考虑它,企业级DBMS产品的大部分精髓都被赋予了查询优化,一定程度地重写查询优化器将会耗费博士研发团队多年的辛勤工作。毫无疑问,在ASE 15.0中最大的改变正是它—完全重写的查询优化器。
重写优化器需要满足不断增长的混合负载、OLAP和甚至是DSS应用程序的需求,由于要满足实时报表或普通应用程序扩展以利用数据保持力的改变来满足业务需求,诸如市场、趋势分析或其他源于历史数据的信息,如客户波动。考虑以下OLTP与DSS应用程序的趋势变迁描绘图:
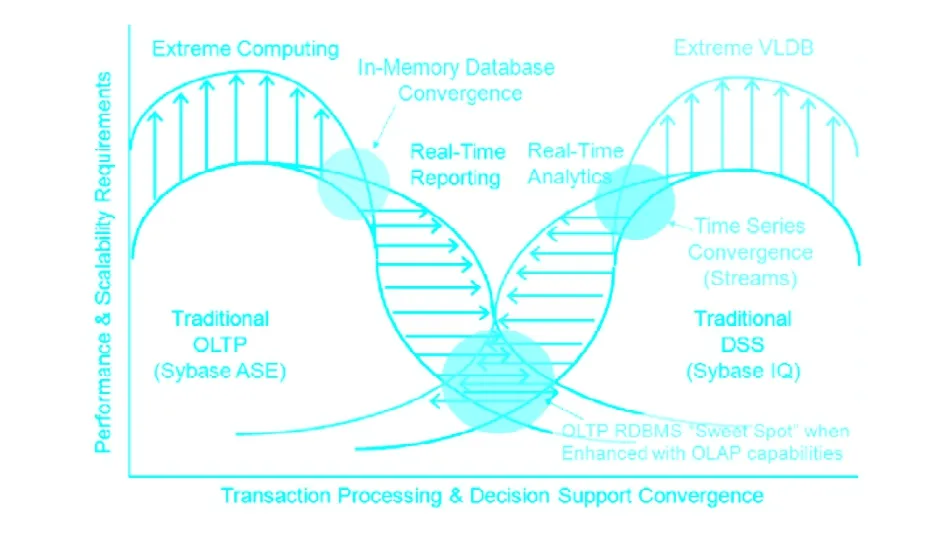
图3 OLTP 和 DSS 应用程序趋势
注意OLTP与DSS系统的变迁,为了填补它们之间的空缺而产生了两类新的需求—实时报表和实时分析。为了支持实时报表复杂查询处理的变化,ASE完全重写了查询优化器,增加了新的典型DSS/报表优化特性,例如:DSS连接技术,诸如合并连接(merge join)、哈希连接(hash join)、N阵嵌套循环连接(n-ary nested loop join)和对星型模型的支持;支持聚合、联合和去重的更快算法;改进了对并行查询的支持,包括导向/矢量连接以减少资源使用。
非常有用的也是比较复杂的特性之一是优化目标和标准。对优化器工程师来说,关键需要考虑开发出的优化器能在最快的时间内能找到优化的执行计划,因为优化时间很容易超过执行时间。例如,一个12向的连接涉及12张相对大的表(每个表在10万至1 000万行),需要10 min优化但仅需30 s去执行。因此,如果优化器了解应用程序的本质,它就能避免在优化阶段的前期找到一个查询计划后,又竭尽全力去寻找可能不会比该计划更快的查询计划。ASE 15.0实施了3个特性以达此目的—优化目标、超时和标准,见表10。
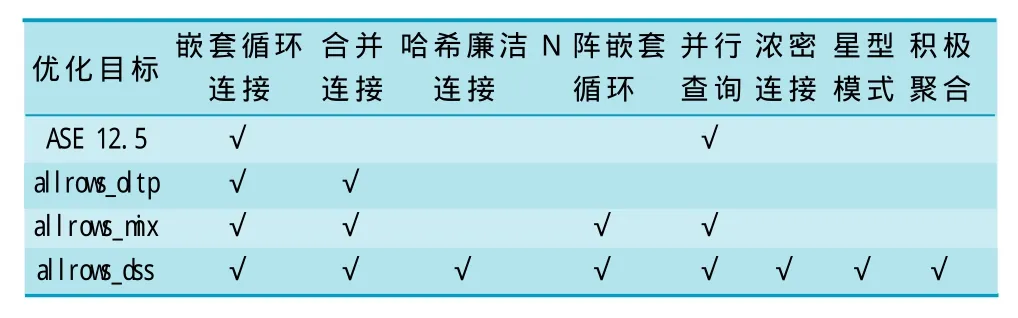
表10 不同优化目标和一些关键查询技术之间的高层级关系
虽然allrows_dss能运行所有内容看起来很诱人,但是请记住前面关于优化时间超出执行时间的讨论。一个关键的原因是合并与哈希连接被认为是DSS类型的操作,因为它们假定连接不会被索引完全覆盖,通常可能并不是即席报表查询的情况。因此,这样的连接条件通常会因数据排序而受益,要么是物理地要么是内存哈希表,与连接排序的连接列。较严厉的OLTP系统应用索引来强制主外键。
虽然“容量规划”常常被包含在开发周期中,而“负载管理”却常被忽略。不幸的是,业务用户通常让硬件/软件来自动执行负载均衡,还需要考虑业务优先权,简直就是不可能的任务。事实是不同的应用程序常常会有不同的优化需求,使用错误的技术同时支持所有的需求将造成失败。请认真考虑,如何去满足冲突的需求:高速插入/最小化优化;复杂查询与更长时间的优化需求。在不断改变的现实中,日趋快速的 CPU,大量廉价的内存。现在更倾向于用更多的CPU和内存来执行密集算法么?四核=低价的大型SMP。它不仅带来了第2阶段的应用程序整合,它增加了复杂度,还在更低的价格点上提供了并行策略的CPU资源。在从未如此扩展的领域中,更大的数据量和更大的使用人群。
好的方法是通过会话级别和查询相关的优化控制,让开发人员来控制优化。因此,ASE 15不仅增加了DSS优化技术,它还令其可配置并通过优化目标提供了3个初始的优化情形。开发人员必须考虑应用程序组件的本质并与DBA一道工作,为不同的应用程序实施“优化情形”,然后这些可以根据应用程序名称或其它特质来通过登录触发器实现。通过这些特性,OLTP应用程序能避免不适合OLTP的长时间优化或复杂优化算法,而报表应用程序则可利用诸如索引联合、浓密连接等的新功能。使用支持表来存储优化情形的登录触发器例子如下:
-- created in master to allow prevent login failures in case the server needs to
-- be booted with traceflag to recover master database only
use master
go
create table optimization_profile (
appnamevarchar(30) not null,
opt_goalvarchar(20) not null,
parallel _deg tinyintnot null,
use_stmtcache bit not null,
use _mergejoin bit not null,
use _hashjoin bit not null,
use _idxunion bit not null,
delayed _commitbit not null,
primary key (appname)
)
go
exec sp_logintrigger 'drop' go
if exists (select 1 from sysobjects
where name= ' sp_optimization_profile' and type='P' and uid=user_id()) drop procedure sp_optimization_profile
go
print "...creating procedure: 'sp_optimization_profile'" go
create procedure sp_optimization_profile as begin
declare @appnamevarchar(30),
@opt _goal varchar(20),
@use_stmtcachebit,
@use_mergejoinbit,
@use_hashjoinbit,
@use_idxunionbit,
@delayed_commitbit
if suser_name()='sa' return 0
if has _role('sa _role',0)=1 return 0 select @appname= (case
when clientapplname is not null then clientapplname else program_name
end)
from master.. sysprocesses
where spid=@@spid
set export on
if exists (select appname
from master. . optimization_profile where appname= @ appn ame)
begin
select @opt _goal=opt _goal,
@use_stmtcache=use_stmtcache from master. . optimization_profile
where appname= @ appname
if @opt_goal="allrows_oltp" set plan optgoal allrows_oltp if @opt_goal="allrows _mix" set plan optgoal allrows _mix if@opt_goal="allrows_dss" set plan optgoal allrows_dss
if @use_stmtcache=1
begin
set statement_cache on set literal _autoparam on
end else begin
set statement_cache off
end
if @delayed_commit=1 set delayed _commit on ...
end
return 0
end
go
grant exec on sp _optimization_profile to public go
exec sp_logintrigger 'master. .sp_optimization_profile' go
如果一个单独的服务器试图支持不同类型的应用程序(OLTP和DSS),则强烈推荐使用该技术,因其支持应用程序开发人员控制每个应用程序必要的优化配置,而无需在应用程序中进行硬编码配置。除了优化情形外,开发人员也必须考虑临时表和应用程序相关tempdb的负载管理。当一个服务器与DSS用户共享时,这将改善需要支持混合负载的OLTP应用程序响应度。当大型的DSS查询充满tempdb时,通过避免tempdb挂起问题,它也能改善OLTP应用程序的可用性。
