基于领域本体的Web服务发现研究
2010-04-11周宇
周 宇
ZHOU Yu
(河南教育学院 信息技术系,郑州 450046)
基于领域本体的Web服务发现研究
Research on Web service discovery based on domain ontology
周 宇
ZHOU Yu
(河南教育学院 信息技术系,郑州 450046)
随着对Web服务复用、组合研究的不断深入,Web服务发现已成为一个主要面向服务计算领域的研究热点问题,并以查准率、查全率和查询效率作为评价其效能的主要指标。据此本文提出了一个领域本体的构建方法来扩展用户查询端查询的语义精确性,可以提高服务构件的查准率和查全率。另外本文还实现了一个基于领域本体的服务搜索引擎原型系统,可以很好地达到对服务查询效能方面的提高。
领域本体;服务发现;查询;搜索引擎
0 引言
发现服务是面向服务Web软件开发中的一个关键技术,近年来关于服务发现的研究都是考虑到当前公共UDDI上注册的Web服务缺少语义描述,于是都各自增加了对Web服务的语义描述,但这些方法在实际操作上仍然存在诸多困难[1]我们提出的方法与其它方法的不同及优势在于:
1)扩展及求精客户端查询请求,提高查准率和查全率;
2)对现有搜索引擎扩展实现了一个原型服务搜索引擎。解决了其它方法实际操作比较困难的问题。因为目前我们的服务库仍然是传统意义上的www,而非语义Web,所以考虑如何在目前的www上提高服务的搜索效率是有意义的。
1 基于领域本体的Web服务发现
Web服务使用标准的、规范的XML进行描述,该描述包括消息格式、传输协议和位置,能够快速地开发、发现、发布和动态地绑定应用服务[2]。Web服务发现是Web服务中的关键问题之一,Web服务发现则是使服务使用者找到合适的功能,并使Web服务的自动组合成为可能。可以采用信息检索中的某些评价标准来评价Web服务发现技术的性能,例如查准率和查全率等[3]。
本体的目标是捕获相关领域的知识,提供对该领域知识的共同理解,确定该领域内共同认可的词汇,并从不同层次的形式化模式上给出这些词汇和词汇间相互关系的明确定义。OWL-S[4]就是一种采用本体描述语言OWL定义的一套专门描述Web服务的本体。 OWLS作为一个本体,其顶层结构分为服务概要、服务模型、服务绑定三个部分。
领域本体的目标是捕获相关的领域知识,提供对该领域知识的共同理解,确定该领域内共同认可的概念,并给出这些概念和概念之间相互关系的明确定义,减少了由于概念理解的歧异所产生的错误和失误,方便了基于功能的服务发现和组合,同时还弥补了UDDI基于关键字的查找技术的不足[5]。
2 基于领域本体的服务查询方法
2.1 领域本体的构建
目前服务发现方法都是考虑到当前公共UDDI上注册的Web服务缺少语义描述,于是都各自增加了对Web服务的语义描述。本文提出的方法主要是通过建立领域本体来扩展用户查询端查询的语义精确性。我们建立了一个领域本体,服务查询是基于领域本体的。领域本体为服务查询提供专门领域知识。
我们用RDF (Resource Description Framework,资源描述框架)建立了一个计算机领域本体。RDF是一个表示www上资源信息的语言,用来处理元数据的XML应用,能够清楚地表示信息语义,并且是机器可理解的,提供推理支持。RDF 使用 Web 标识符来标识事物,并通过属性和属性值来描述资源。一个RDF文件包含多个资源描述,而一个资源描述是由多个语句构成,一个语句是由资源、属性类型、属性值构成的三元体,表示资源具有的一个属性。RDF用于描述Web站点和页面,由于使用的是结构化的XML数据,搜索引擎可以理解元数据的精确含义,使得搜索变得更为智能和准确,
在RDF中,如下的英文陈述:" http://www.example.org/index.htmlhasacreatorwhosevalueisJohnSmith",用RDF图的描述如图1所示。
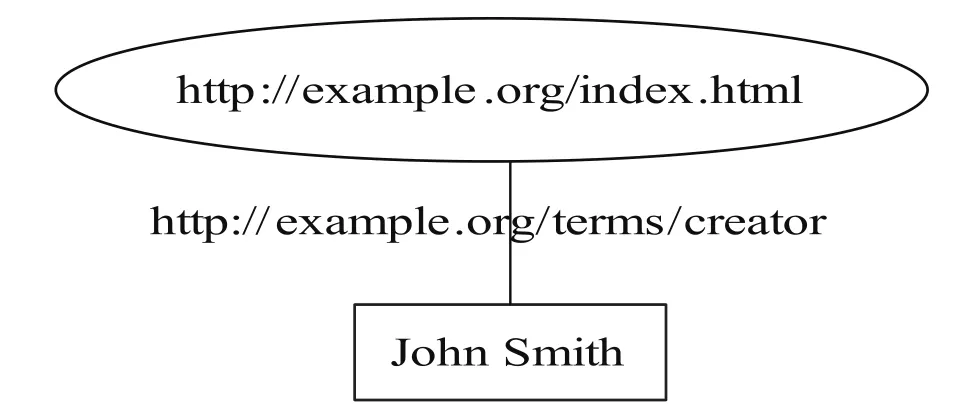
图1 用RDF图描述的一个陈述
在RDF图中利用节点和弧作为表达陈述的元素。一个陈述用RDF图可以表示为:
一个表示主体的节点(http://www.example.org/index.html) :
一个表示客体的节点(John Smith ) ;
一个由主体节点指向客体节点的表示谓词的弧 (http://www.example.org/terms/creator);
图1用RDF/XML可以用来表示如下:

2.2 转换查询为RDF查询
在服务发现的研究中,基于关键词匹配的服务查询具有以下缺陷:1)对所需查询的目标不能准确描述;2)不能度量候选者和查询目标间的符合程度。这两点直接影响到搜索的查准率。而基于领域本体的服务查询则可以避免上述缺陷。
基于领域本体的服务查询主要步骤如下:1)转换初始化查询为RDF查询;2)查询推理和查询扩展。基于领域本体的服务查询系统体系结构如图2所示。
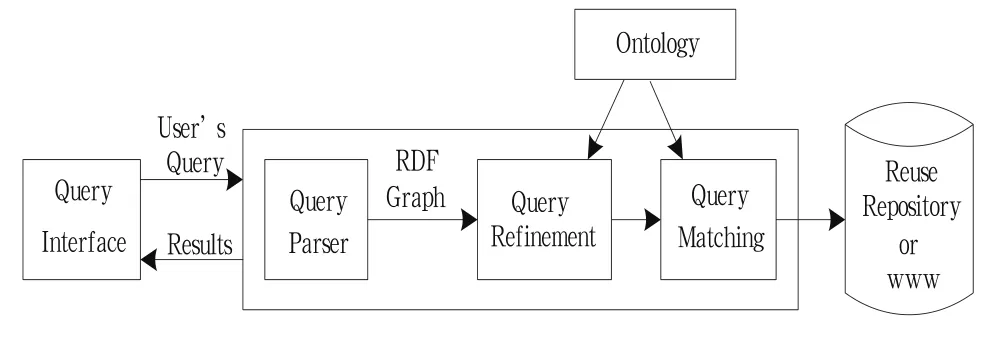
图2 基于领域本体的服务查询系统结构图
用户可以用自然语言设置服务构件查询。系统转换这种查询为RDF图,这个RDF图将与表示为RDF图的www资源进行匹配。例如:查询:"what are the components of Application system?",可以表示为图3所示的RDF图:

图3 服务构件查询图
3 基于领域本体的全文搜索引擎设计与实现
利用以上构造好的领域本体我们实现了一个的基于本体的服务搜索工具,能对用户的初始查询进行扩展,从而构造一个更加完整和准确的概念和知识,并以修正后的查询利用检索引擎来匹配资源。该搜索引擎系统,包括用户数据库服务器、用户接口及登录、资源描述、Web信息搜集器、检索器、索引器和用户分析器等功能部分。其结构如图4所示。
搜索引擎主要组成部分介绍:
1)Web信息采集器:信息采集器对整个搜索引擎的体系结构有很大影响,是搜索引擎的一个重要组成部分。基于本体的Web信息采集的功能包括爬虫管理、爬虫算法、信息监控、数据更新、数据存储以及数据压缩和通信模块。
移动爬虫运行在远程Web服务器上,将集中在服务器端的处理在信息采集过程中,移动爬虫将在Internet中Web站点之间的移动,对Web站点进行“本地采集”以及对采集的数据进行处理,最后将压缩的数据传回服务器端处理;接着移动爬虫继续迁移到其它Web站点进行信息采集,其迁移路径采用自适应迁移策略控制,采用该策略可以减少网络数据传输量和缩短工作时间;移动爬虫的并行度控制策略可以控制信息采集器中移动爬虫的个数,这样就不会过分加重远程Web站点的负载,增强系统的稳定性。

图4 基于领域本体的搜索引擎结构示意图
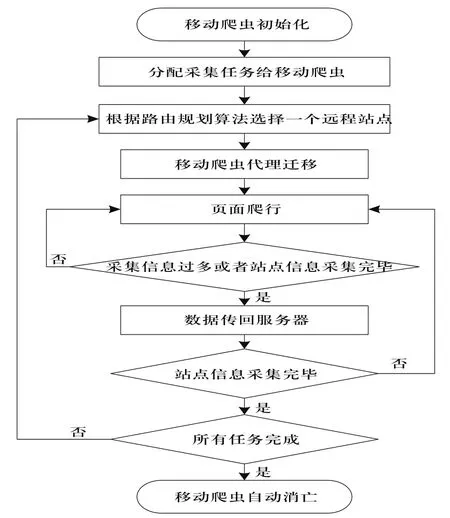
图5 基于领域本体的网络爬虫工作流程图
网络爬虫与本体技术的融合是搜索引擎的一种新的模式。 图5描述了基于本体的网络爬虫工作流程图。
2)索引器:索引器把下载的网页进行关键字提取,把这个文档内的全部单词分别提取出来放在数组或者链表中,然后依次对每个单词进行索引,得到的索引库为全文索引数据库。充分利用分布式本体的计算优势,将索引器的一部分功能如对文本解析建立文本索引、建立图像内容的特征索引等处理分布式到远程Web站点上处理,最后由移动爬虫将压缩后的结果传送到索引服务器端进行汇总、分类处理,减轻了服务器端的负载。检索器将这两部分索引文件组织成特定的数据结构供检索器查询检索。当Web页面数据发生更新时索引数据也需要更新,网页数据的更新可以触发索引的更新,因为网页数据的更新可以根据驻留在服务器端的模块及时反馈到服务器端。
3)检索器:检索器模块具有以下四项功能:匹配计算、相关反馈、结果排序和日志分析。
功能就是接受用户提交的查询请求,按照查询条件在索引库中搜索满足条件的文件,并根据用户定制的过滤条件和排序因素组织搜索结果集,返回给用户接口。本文搜索引擎的检索器就是利用索引数据库提供的特征索引库、图片对应网页的全文索引库、关键字索引库以及超链接分析库和查询历史库等多个数据源,实现对用户输入关键字的准确、快速的匹配。
4)用户接口
用户接口提供一系列查询方式、选项以满足用户不同的查询要求,将用户的查询请求提交给检索器去匹配。检索器将排序后的结果集返回给用户。
用户接口具备的主要功能为:待查文本的输入、图像特征提取、关键字和其他输入的选择、生成查询描述、结果显示、相关反馈方式查询。在获取了文本关键字或图像的特征向量以及其他的一些辅助信息后,根据一定的规则和格式生成查询描述,提交给检索匹配模块。从检索器接收排序后的查询结果后显示在用户界面中。
4 结论
本文提出了一个领域本体的构建方法,基于这个领域本体,表示了服务构件的检索过程,并且实现了一个基于领域本体的服务搜索引擎原型系统,优点是求精和扩展用户的初始查询,支持用户的模糊查询,查全率和查准率都得到了提高。特别是随着Internet变成可重用软件资源库,搜索引擎支持构件查询是必须的。
[1] F.Baader,D.McGuinness,D.Nardi,and P.F.Patel-Schneider.Description Logic Handbook:Theory,Implemtation,and Applications.Cambridge University Press,2002.
[2] Gilmer Orth.The Web Services Framework:A Survey of WSDL,SOAP and UDDL Master's thesis,Vienna University of Technology,May,2002.
[3] Ankolekar A.,Burstein M.,Hobbs.J.R,et al.DAML-S:A Semantic Markup Language for Web Services.In:Proc.of International Semantic Web Conference (ISWC),pp.348-363,Sardinia,Italy,2002.
[4] OWL-S Coalition,OWL-S,available at http://www.daml.org/secviceslowl-s/,2005.
[5] DAML-S Coalition.OWL-S:Semantic Markup for Web Services.http://www.daml.org/services/owl-s/1.0/.in:ProceedingsoftheInternationalSemanticWebWorkingSymposium(SWWS)July30-Augustl,2001.
TP391
A
1009-0134(2010)12(上)-0217-03
10.3969/j.issn.1009-0134.2010.12(上).70
2010-08-21
周宇(1964 -),男,湖北人,讲师,研究方向为计算机技术及应用。
