代表帧及其提取方法*
2010-03-14王新舸罗志强
王新舸,罗志强
(1.石家庄陆军指挥学院,河北 石家庄 050084;2.第二炮兵指挥学院,湖北 武汉 430012)
1 引言
关键帧提取技术是实现视频检索的一项重要技术,目前视频关键帧的提取技术已较为成熟,但无论哪一种技术都很少考虑视频制作者的意图,笔者在传统关键帧概念的基础上,针对作者意图提出了一种新的关键帧类型。
2 关键帧的分类
关键帧是反映一组镜头中主要信息内容的一帧或若干帧图像。目前提取关键帧的技术大致可分为5类:基于镜头边界的方法、基于视觉内容的方法、基于运动分析的方法、基于镜头运动的方法和基于聚类的方法。这些算法主要目的是将视频分割成独立的镜头,但如何从镜头中选择出最能代表制作者意图的帧,或者制作者最想展示给观众的帧,却很少考虑。
仅仅将关键帧理解为镜头的分割点[1],实际上缩小了关键帧的范围。关键帧应能反映镜头中的主要内容信息,而镜头分割点处的帧虽然代表镜头的初始内容,对反映镜头内容有重要的作用,但却未必是镜头中最有代表性的帧。关键帧可分成两种:一种是镜头的起始帧和结束帧,称为定位帧;另外一种则是在镜头中最能反映制作者意图,能够代表镜头主要内容的若干帧,称为代表帧。
代表帧在需要对视频进行快速浏览时具有非常重要的意义,通过观看镜头的定位帧和代表帧可快速判断出视频的主要内容,在从大量视频中快速查找镜头时非常有用。目前也在一些实际运用中使用了代表帧,如电视节目视频编目,通常是取每个镜头最接近时间中点的帧作为代表帧,但这一做法并不能很好地满足实际需要。
3 代表帧提取原理
要想从一个镜头中选取出最能反映制作者意图的帧,首先要分析制作者的制作方法,制作者通常在最想展现的内容出现时,留给观众接受的时间,在这段时间内,镜头通常会保持相对的稳定,图像的变化较其他帧要小。例如,制作者要反映一个小船上的船夫会选择从水面的远景,逐渐转移到小船,再转移到船夫,然后镜头在船夫的身上停留一段时间,再转移到其他位置。在这个过程中,镜头从水面到小船和从小船到船夫的移动过程都是比较快的,而一旦转移到船夫身上时,移动过程会明显减慢甚至停止一段时间,除非制作者不想着重表现船夫。再比如要表现一个人物的脸部时,可能会先从人物的侧面开始,逐渐旋转到人脸的正面,然后停留一段时间。
利用制作者的这一处理方法,不难发现代表帧的判断方法[2-3]:首先利用传统的方法找出定位帧,将视频分割成镜头,再利用同一镜头内部相邻帧间的某种特征差值,找到相邻帧间特征值变化最小的若干帧,即这些差值的谷值点,作为代表帧。
4 代表帧提取的实现方法
代表帧的提取是基于定位帧获取算法的[4-7],首先给出一种定位帧的提取算法。
4.1 定位帧提取
定位帧提取原理比较简单,当视频中有镜头切换时,在切换前后的相邻两帧每一个对应的像素点上,会产生很大的颜色变化,利用这一特征可以设计如下算法来提取定位帧。
两帧每一个对应像素点的平均颜色差(以下简称帧差)的计算公式为

式中,Dc(x,y)表示两帧中坐标为(x,y)的 2 个像素的颜色差。颜色差始终保持为正值,可使用灰度值进行计算,也可以使用RGB三色空间的色距表示。考虑到连续帧中的局部区域也会出现颜色较大变化,因此对颜色差进行一次开方处理,以减少局部区域变化对帧差的影响。
图1是一段视频中每一帧与其相邻前一帧的帧差曲线,其中横坐标是时间,纵坐标是帧差。
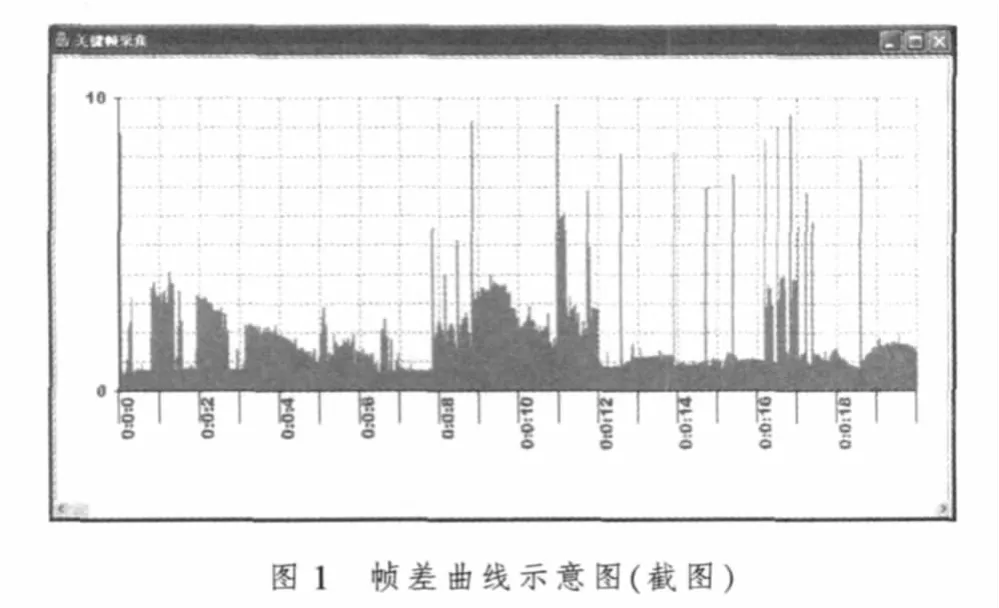
从图1中可以明显看出,在场景切换时,会在图上留下一条特别明显的高脉冲线(如9.0 s,11.0 s,12.6 s等位置),利用这一特征可提取出视频中的定位帧:设置一个高阈值A,一旦某一帧与其前一帧帧差超过A值,即可判定当前帧是定位帧,为防止非定位帧被误判,A值也不能过小,图1中A值应该在6~7之间。
图中还有一部分帧(如 0.8 s,2.0 s,6.5 s等位置)有镜头切换,也出现了较高脉冲,但帧差值比有些无镜头转换的帧(如9~10 s之间)的帧差还小一些。这部分定位帧不能仅使用高阈值A来判断,从图1可观察到这些帧的帧差仍比其前面一段帧的帧差明显大一些。
可以设计如下算法对这部分定位帧进行提取:设置一个低阈值B和一个变化阈值C,当帧差值在A值和B值之间时,进一步判断该帧差与平均帧差之比是否大于变化阈值B,大于则可判定为定位帧,否则不是定位帧。
平均帧差可使用加权法计算,公式为

式中:fn代表新的平均帧差,f代表当前帧差,f0代表旧的平均帧差,K代表加权系数。K的取值范围是0~1,K值越大,表示当前帧差对平均帧差的影响越大,平均帧差变化越快。
图2是提取定位帧的流程图。

4.2 代表帧提取
提取了定位帧,就可以将视频划分成很多镜头,在定位帧的基础上,进一步对镜头的内容进行分析,提取出镜头的代表帧[8-10]。
提取代表帧需要先确定帧差曲线的谷值位置,即必须要对视频进行2次分析,第1次绘制出帧差曲线,找到谷点,第2次提取谷点位置的帧数据,这种方法虽然能准确找到代表帧的位置,但效率较低,如果需要在视频采集的过程中同步提取代表帧,就不能使用这种算法。
如何能在第1次分析时,既找到谷点又能在相应位置提取出关键帧呢?采用谷值预测技术能有效解决只进行一次分析提取代表帧的问题。图3和图4是使用谷值预测技术提取代表帧的流程图,图4是图3中“产生新代表帧”的流程图。
在镜头的第1帧,先预设一个参考帧差F,只有帧差低于这一值时才有可能被判定为代表帧。然后依次分析每一帧,一旦遇到帧差比参考值低,就判断当前处于曲线的下降通道,此时严格的讲,每当帧差下降一次,就有可能已经达到曲线的谷点,应临时保存该帧的数据为新的代表帧,但这样会在曲线的下降过程中临时保存大量的帧数据,降低程序运行效率。
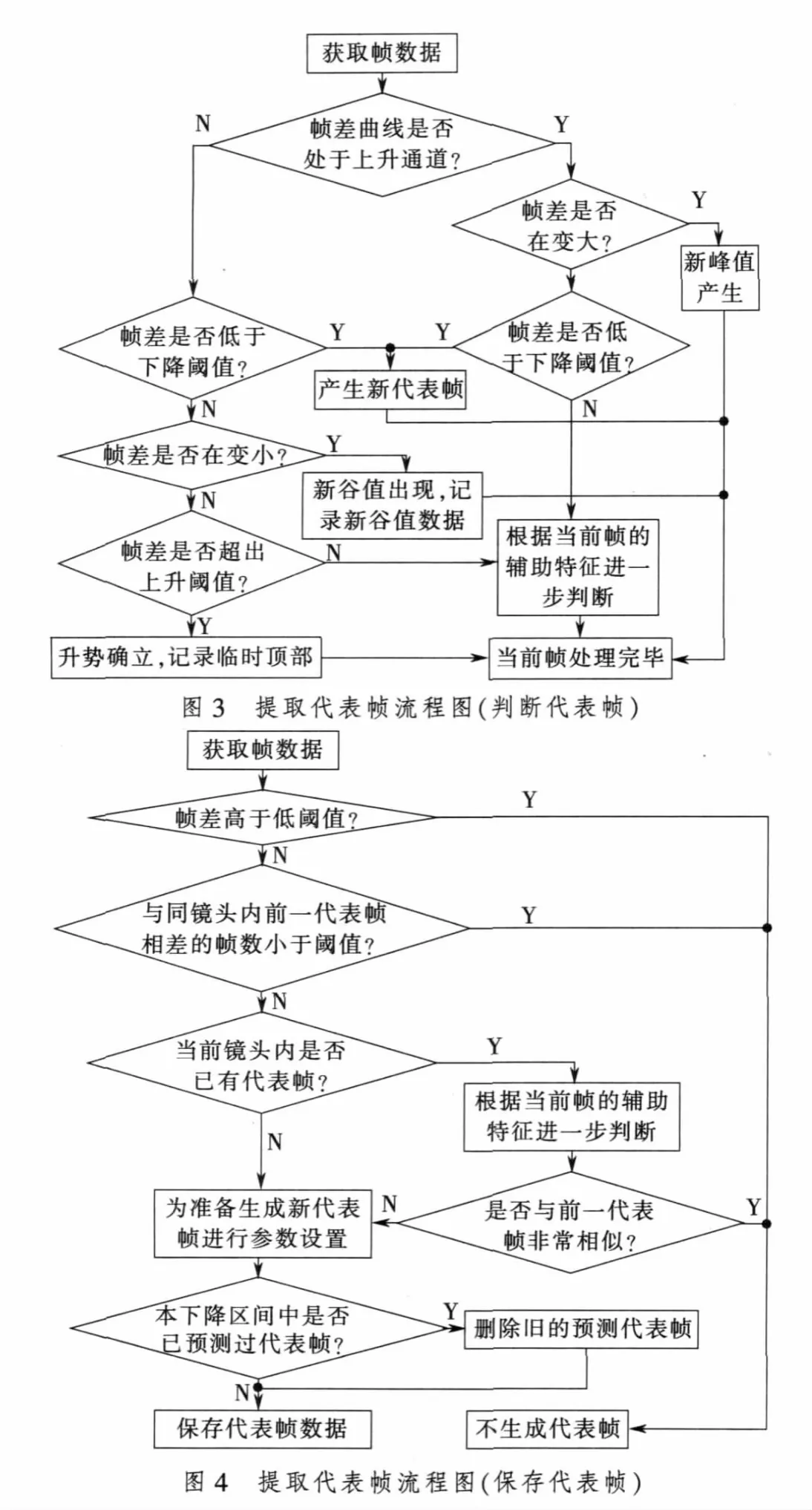
为解决这一问题,可增加一个参数D,在曲线下降时,并不立即将当前帧作为代表帧,只有当帧差与参考帧差F之比低于参数D时,才将当前帧设置为预测代表帧,同时将当前帧差设置为参考值。预测代表帧并不一定是真正的代表帧,若帧差继续下降,与参考帧差F之比再次低于参数D时,就将该点设置为新的预测代表帧,同时删除旧的预测代表帧。若帧差开始进入上升通道或当前镜头结束(遇到了定位帧),则将最后一次提取的预测代表帧设置为代表帧。若帧差从上升通道转到下降通道,就以峰值为参考值,继续进行新的代表帧判断。
5 小结
严格地讲,在现有人工智能发展状况下,代表帧的提取要完全依赖计算机智能提取是不现实的。但任何一种技术的发展都离不开大量的尝试和经验的积累,希望本文能够为视频内容智能识别带来新的思路。
[1]陈晓艺,姜秀华.MPEG视频的镜头分割技术[J].中国传媒大学学报:自然科学版,2004,11(1):26-29.
[2]除忠强.电视新闻节目基于内容的视频检索技术及其实现[J].电视技术,2008,32(10):72-74.
[3]陈静.基于代表帧的视频摘要算法[J].现代计算机,2006(6):82-84.
[4]王彦㭎,马驷良.基于关键帧提取的视频分割算法[J].吉林大学学报:理学版,2004,42(4):570-571.
[5]胡双演,李钊.基于内容的视频分析技术研究[J].综合电子信息技术,2006,32(5):42-44.
[6]蔡肯,梁晓莹.基于内容的视频检索技术[J].现代计算机,2007(12):59-61.
[7]叶军,周卉,李建良.基于视频分割的关键帧提取[J].计算机工程与设计,2008,29(1):109-111.
[8]刘佳兵.视频检索中的关键帧提取技术[J].福建电脑,2007(12):55.
[9]周政,刘俊义,马林华,等.视频内容分析技术[J].计算机工程与设计,2008,29(7):1766-1769.
[10]佟超,吴文怡.基于颜色的关键帧图像检索技术研究[J].电视技术,2008,32(10):17-18.
