面向多核的共享多通道Cache体系及原型构建
2010-03-12刘彩霞薛立成
刘彩霞,石 峰,邓 宁,宋 红,薛立成
(北京理工大学计算机科学技术学院,北京100081,lcxhxb@gmail.com)
多核(Chip Multi-Processor,CMP)处理器能够充分开发不同粒度的并行性,因而成为微处理器的主流发展方向.本质上多核设计的瓶颈还在于解决片内多核之间的互联和通信机制问题,也就是需要一个快速的数据存储和传输路径[1-3].存储系统在多核系统中不再仅仅意味着对数据的组织和存储,合理的存储体系对于提高多核系统并行通信性能甚至系统整体性能起着至关重要的作用[4-5].
基于将不同的存储体系的优势结合的目的,本文提出一种使用多通道Cache作为L2 Cache的可扩展可配置CMP体系Architecture Utilizing Multi-Channel Cache,AUMCC.根据所设计的多通道Cache的不同工作模式,AUMCC可以配置成私有L2 Cache结构或共享L2 Cache结构.AUMCC的共享模式中,多通道Cache的多个独立的访问通道确保了核间共享数据的高效并行传输,提高了核间通信带宽;同时多通道Cache的分离访问模式简化了对L1 Cache的一致性维护开销.基于LEON3处理器的原型系统上性能模拟及测试表明,AUMCC体系能提供高效的并行通信,通信性能相对于基于总线共享Cache结构约高出37%,系统的层次化特点使得系统具有良好的扩展性.
1 使用多通道Cache的多核系统AUMCC总体结构
AUMCC体系是一种采用多数据通道Cache作为L2 Cache的层次化可扩展可配置CMP结构[6](如图1所示).系统中每个核拥有私有分离L1指令和数据Cache,L2 Cache可以根据多通道Cache的访问模式动态配置成私有或共享两种方式,因而AUMCC体系相应的可以配置成私有L2 Cache结构或共享L2 Cache结构.每个核对应一个通道,各个通道依次顺序编址.内核间可以通过底层的互联网络通信,也可以通过共享模式中的多通道L2 Cache交换数据.共享模式的AUMCC中,内核可以读写本地通道内的存储体,可以读其他通道内的存储体,因而不存在多核之间的写冲突问题,简化了对L1 Cache的一致性维护开销,提高了系统性能,同时Cache的多通道特性可以缓解传统基于总线共享Cache结构的总线带宽的瓶颈问题,提高系统访问带宽和可扩展性.
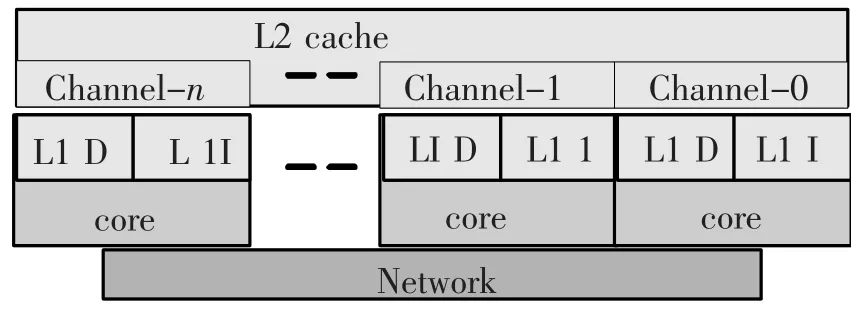
图1 AUMCC总体架构
图1中该结构具有明显的层次性.各功能核及多通道L2 Cache可以看作系统的“超核”.按照构建“超核”的方式,可以通过共享更高级的多通道Cache构成更大规模的系统,相似的构建方式可以应用于memory或辅助存储器.
实验中,节点数2、3、4时的平均精度分别为98.82%、90.29%、76.72%,可见,随着预测节点数增多,预测精度降低,预测结果的稳定性也开始下滑.这是因为,当预测的节点数增多时,所有节点组成区域内的链路组合数量呈指数倍增长,而组合数越多,使得预测结果的搜索空间越大,模型越难准确地命中真实的情况,从而导致其预测稳定性的下滑;同时,当数据集大小有限时,对于每种组合下的输入数据就会更少,即每种标签下对应的训练样本变少,使得各标签的训练过程不充分,模型出现欠拟合现象,从而导致其预测精度变低.
利用CACTI进行的对比实验表明,4个1 KB大小的单端口SRAM在工作频率和面积上都优于一个4端口4 KB的全定制SRAM模块,而且单端口SRAM可以由EDA工具快速编译生成,便于设计实现.因此本文采用存储体多体交叉的方式实现本体系中的多通道Cache[7-9],其硬件组织结构如图2所示.
2 多通道Cache体系结构
2.1 多通道Cache硬件组织结构
设计意图:简洁的问题拉近了教师与学生的距离,让学生有亲切感并迅速进入问题探究.逻辑的学习应该避免简单机械的记忆和抽象的理解,而应通过学生具体、生动的举例来体会逻辑用语.
本文在Xilinx的开发板DS-KIT-4VLX60 MB上利用Xilinx FPGA XC4VLX60-10 FF1148C建立了基于LEON3[11]处理器的AUMCC体系以及基于总线共享Cache结构(SCA)的原形平台.首先利用VHDL语言设计实现多通道Cache控制器,并将其嵌入编译到Grlib库的总线控制器中,实例化该库中三端口SRAM生成多端口Cache存储阵列.将LEON3软核和VHDL设计文件一起利用make工具编译生成库IP核.之后由XST综合工具生成的FPGA网表文件并由Xilinx公司的布局布线和下载工具生成相应的 SOF文件,通过JTAG端口将SOF文件下载到FPGA上进行硬件配置.使用LEON3的基于GCC的LECCS交叉编译系统对基准程序进行编译,得到二进制代码以后,通过串行口下载到FPGA开发板上执行,系统配置参数如图4所示.
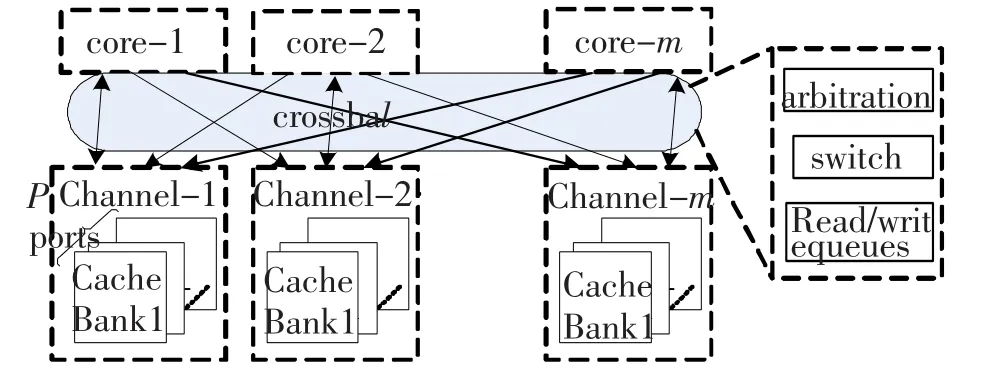
图2 多通道Cache组织结构图
2.2 双模式操作与并行交叉访问
本文为多通道Cache设计了“私有”和“共享”两种工作模式.1)在私有模式下,任意核core-i只能读/写与其对应通道内的多个存储体,不能访问其他的通道;2)在共享模式下,每个核可以读取其他通道的数据,但不能向其中写入数据.任意核必须通过其对应通道的存储体与其他核交换共享数据.
在AUMCC体系的私有工作模式下,每一个功能核只读写L2 Cache本地通道的数据,因而不存在L1 Cache的一致性问题.在共享工作模式下,任意功能核只能读取L2 Cache非本地通道的数据,因而共享模式下L1 Cache的一致性协议可以采用简化的MESI协议——M协议:为每一个L1 Cache块设置一位“M”位,用来标识在共享模式中读取的L2非本地通道内的数据是否被通道拥有核修改.当任意功能核修改了L2 Cache本地通道内的数据时,会通过广播方式通知其他所有核,其他核接收到通知后会根据Tag位和通道标识(CID)将相应的L1 Cache中的M状态位置“1”.L1 Cache在进行Tag比较的同时会查看状态位是否为“1”,若状态位为“1”,则即使Tag命中,也会发出L1 Cache“缺失”请求,进而产生共享读请求,访问L2非本地通道.L2 Cache会根据核标识(CID)将命中的数据送入相应的CPU及L1 Cache中.依据这样的L1 Cache一致性协议,AUMCC Cache体系结构如图3所示.
本文以基准程序集 MediaBench[12]和 OOPACK[13]为基础,从不同的分类中选择了7个典型的基准测试程序basicmath,bitcount,blowfish,matrix,dijkstra,fft和stringsearch.测试结果给出了8核AUMCC体系及SCA体系中各基准测试程序运行时间(如图5所示).相比SCA结构,AUM-CC体系中不存在L1 Cache的一致性维护开销,而且L2 Cache的多通道支持高效的并行访问,因而AUMCC体系中各种测试程序的运行性能均有所提高,平均加速比可以达到37%.通信与交互比较多的应用在两种体系中的性能都最好,说明共享Cache结构能满足核间高速、低延迟的通信需求.对于通信和并行交互比较多的测试程序,AUMCC的性能加速比更高,分别达到 1.52,1.46,因而相对SCA体系,AUMCC体系可以提供更高效的并行通信性能,支持核间共享数据的高效并行传输.
我走到那十几个孩子身边,轻轻拥着第一个孩子,真诚地说:“宝贝们,都抬起头来。你们都有资格拥有徐老师做的小红花,因为老师记得你们所做的每一件让我感动的事情。小辉主动去到垃圾,回来时把垃圾筒洗得干干净净,弄得我们都不好意思往里面丢垃圾了,对吗?”
因此,在写入第1块共享数据之后,读写操作就可以并行执行.当多方的计算负载均衡,速度匹配的时候,核之间可以进行流水并行传输.同步等待延迟最小,传输效率达到最高.
2.3 AUMCC Cache体系结构
可见,在私有模式下,所有的存储体都不存在访问竞争.在共享模式下,AUMCC不存在多核写冲突的问题,简化了维护L1 Cache数据一致性的硬件开销,提高了核间共享数据的传输速度,有利于提高系统应用的实时性.在共享模式下,通道内存储体的低地址交叉方式消除了核间的读冲突.
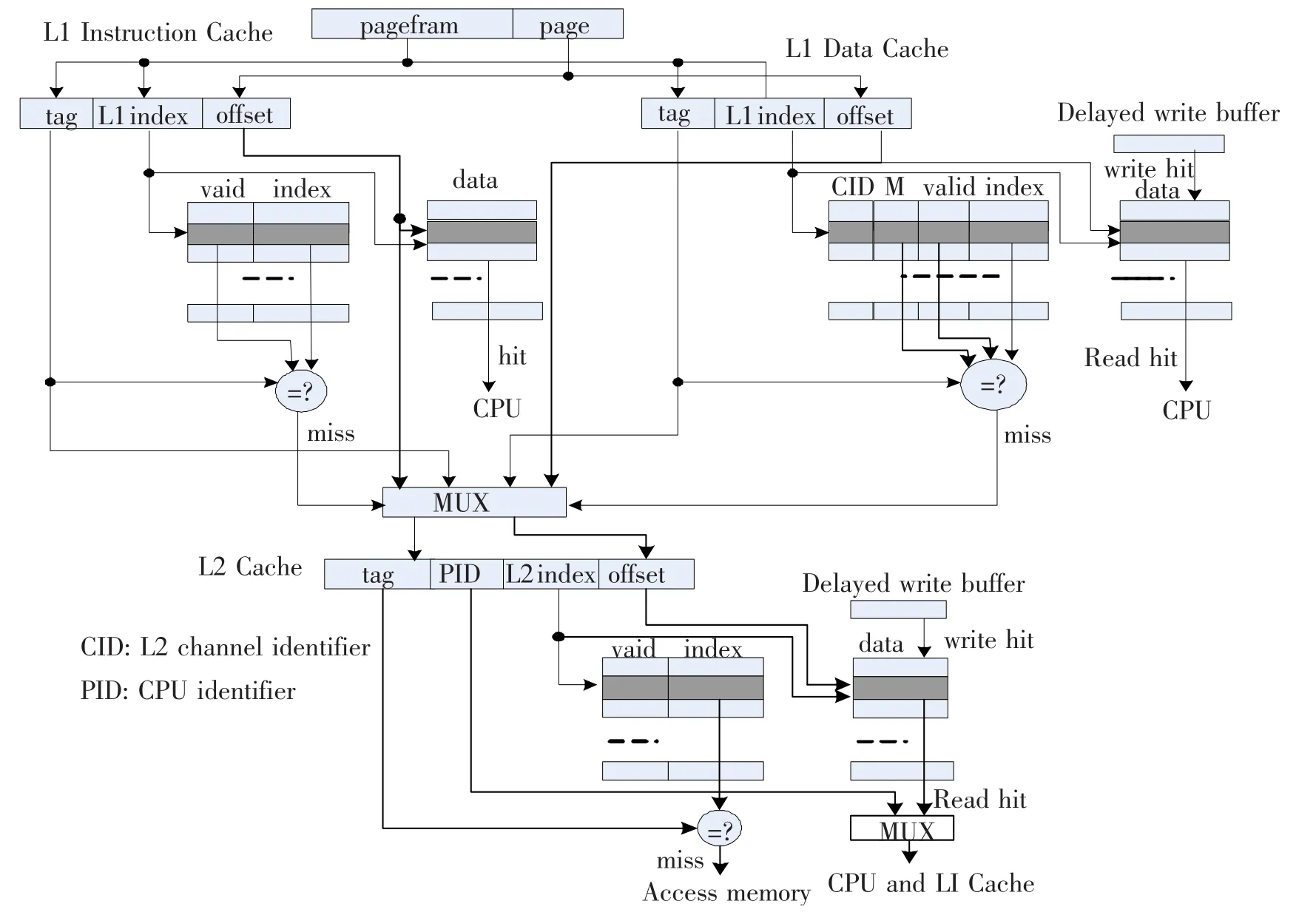
图3 AUMCC Cache体系结构
3 AUMCC原型系统的构建及性能分析
3.1 原型系统的构建平台及构建方案
AUMCC原型系统的构建平台及构建方案设置为:系统环境为Windows with Cygwin,仿真器为Modelsim 6.1f,综合工具为Xilinx ISE 8.1,开发板为Xilinx的DS-KIT-4VLX60 MB.
第三模块是素质拓展模块,通过就业讲座、社会实践、各种比赛等形式,提高学生的综合素质,更好地适应用人单位的需求。
多通道Cache由交叉开关和单端口Cache以多体交叉方式构成.该方案中,m个核通过一个m*n的交叉开关(crossbar)共享一个具有m个访问通道、n个访问端口的Cache存储阵列.每个通道内设置了p片单端口Cache.每一个Cache模块拥有独立的Cache控制器,可以提供独立的访问端口.通道间以高位地址交叉方式编码形成多通道Cache地址,存储器的多体交叉是提高其数据带宽的有效方法[10].通道间高位交叉使得多通道Cache的相邻地址分布在同一个Cache通道内,可以减少通道冲突.而通道内各Cache则以低地址交叉方式形成通道地址,低地址交叉方式可以为访问同一通道的各请求提供基于“生产者-消费者”的流水并行访问方式,降低共享冲突.
3.2 AUMCC体系性能测试
在任务流水的计算模式下,核间的共享数据相继构成“生产者-消费者”关系:前一个核的计算输出直接作为下一个核的计算输入.为了有效支持这种传输模式,在AUMCC中采用了交叉访问的机制:1)当“生产者”core-i向其对应通道内的存储体Bank-i写入第1块共享数据之后,释放该存储体,转而向Bank-i+1写入第2块共享数据;2)“消费者”core-j(j≠i)启动读访问,从Bank-i读出第1块共享数据;core-i释放Bank-i+1,向Bank-i+2写入第3块数据.依此类推,直至全部并行流水传输完成.
在消除了多通道Cache的访问冲突之后,所有核可以同时访问不同的存储体.理论上看,AUMCC的访问带宽可以随着核数量的增长而线性增长,具有良好的可扩展性.为此,定义AUMCC体系的带宽B为在某个单位时间内所能完成的访问请求的数目,模拟时以每拍实际完成的访问请求的数目DPC(Demands per cycle)来衡量共享数据Cache的带宽,N为核的数量.7个基准程序的扩展性模拟结果如图6所示.

图4 系统参数配置
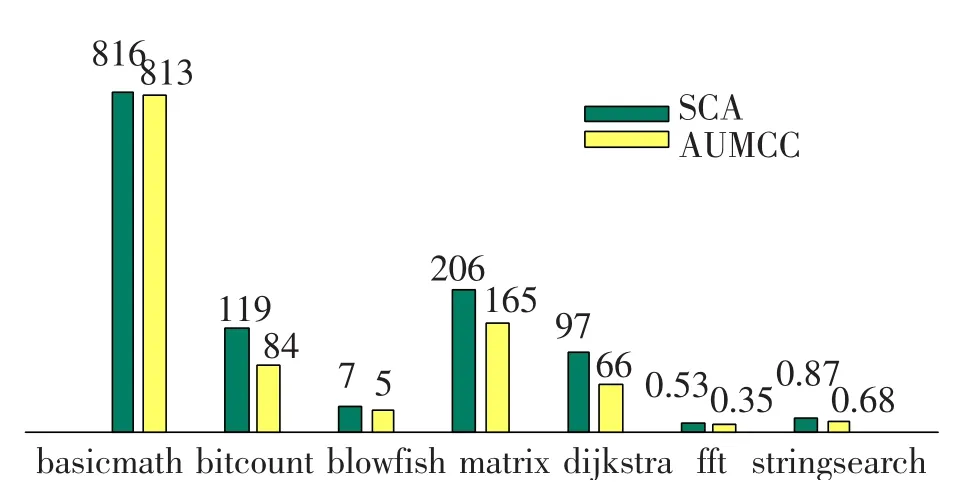
图5 两种体系下基准程序得运行时间
3.3 系统扩展性测试分析
路遥:鼓舞亿万农村青年投身改革开放的优秀作家。路遥,原名王卫国,陕西清涧人,1949年12月出生,1992年11月去世,曾任中国作家协会陕西分会党组成员、副主席,先后创作了《人生》《惊心动魄的一幕》《在困难的日子里》等作品,荣获“陕西省有突出贡献专家”称号,享受国务院政府特殊津贴。特别是他勇于改革文坛风气,创作了长篇小说《平凡的世界》,展现了我国城乡社会生活和人民思想情感的巨大变化,颂扬了拼搏奋进、敢为人先的时代精神,激励了一代又一代青年人向上向善、自强不息。
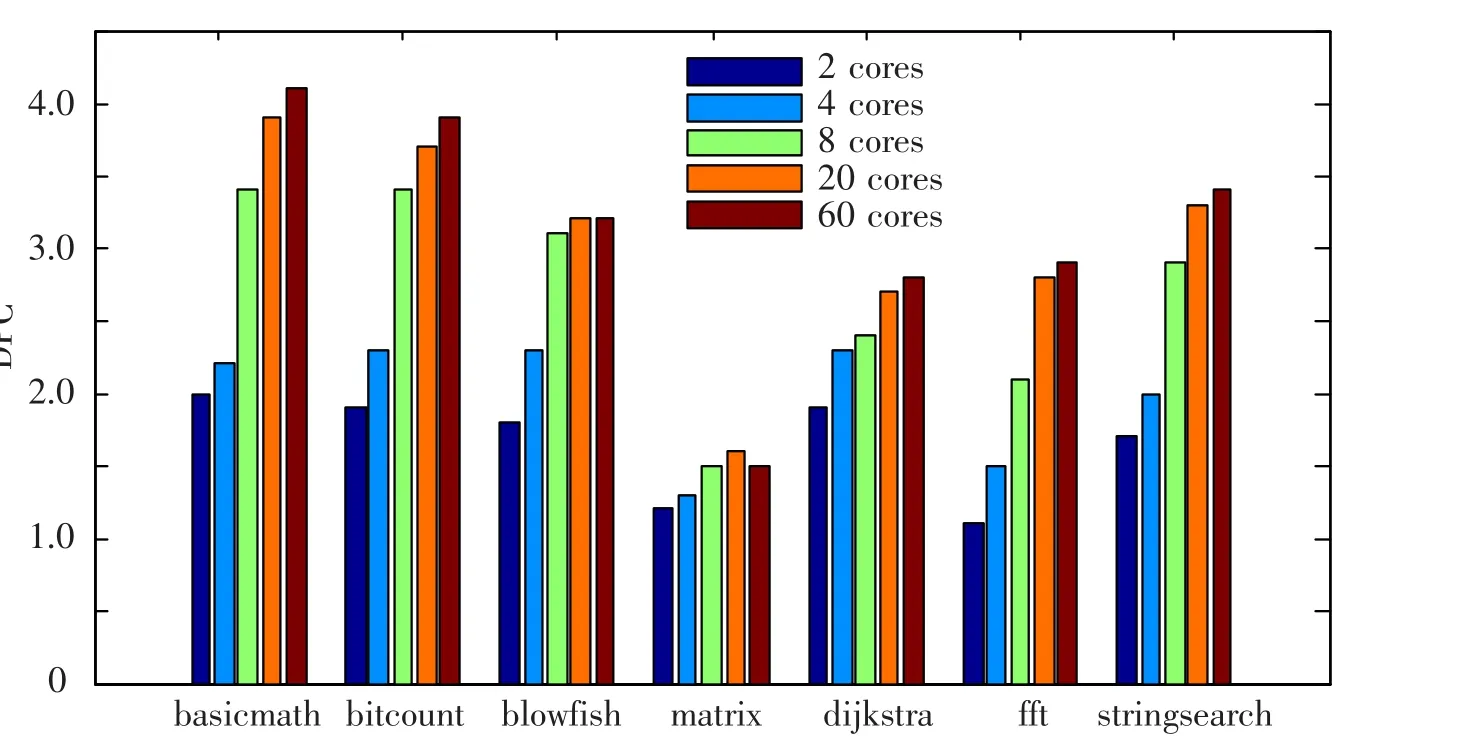
图6 AUMCC系统有效访问带宽与核数量的关系
由实验结果可见,当N<12时,B快速增长,与N呈近似的线性关系.随着N的进一步增大,核与存储体之间的控制逻辑开销、互连总线和交叉开关端口数量以O(N2)数量级增长,AUMCC的工作频率开始下降,访问延迟越来越大,有效访问带宽增长十分缓慢.当N<8时,带宽的平均增长率为30%;当8<N<12时,平均增长率为13%;当N>12时,带宽增长率低于5%.因此,AUMCC适合于12核以内的多核CMP.当核数量超过8核以上时,将以4核为一个超节点进行结构扩展.超节点内部采用AUMCC实现紧耦合的数据传输,超节点之间通过片上网络或者其他共享存储结构进行数据传输.
4 结论
1)提出一种面向多核系统的使用多通道Cache作为L2 Cache的高效存储架构AUMCC.
黎永兰母亲李玉愤恨地说,自己的女儿还是一个副区长,但平日里穿的衣服都是淘宝上买的几十块的平价货,遇到重大场合才舍得穿一件几百块钱的好衣服,生活品质连刚毕业的大学生都不如。
2)针对性能需求设计了多通道Cache的体系,其两种分离访问模式不仅简化了L1 Cache的一致性维护开销,同时使得AUMCC可以分别配置成共享L2 Cache和私有L2 Cache两种架构.
3)采用LEON3处理器基于FPGA构建了AUMCC体系原型系统并进行了系统性能仿真模拟,结果表明,AUMCC体系相对于传统基于总线共享的存储架构而言有37%的性能提升.同时系统扩展性试验表明,该体系具有明显的层次化特点,易于扩展.
[1]OLUKOTUN K,HAMMOND L.QUEUE:The future of microprocessors[J].ACM,2005,3(7):26-29.
[2]Costin Iancu,Steven Hofmeyr.Runtime optimization of vector operations on large scale SMP clusters[C]//Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques.New York,NY:ACM,2008:122-132.
[3]HOEFLER T,GOTTSCHLING P,LUMSDAINE A.Leveraging non-blocking collective communication in highperformance applications[C]//Proceedings of the Twentieth Annual Symposium on Parallelism in Algorithms and Architectures.New York,NY:ACM,2008:113-115.
[4]LEE Jaejin,SEO Sangmin,KIM Chihun,et al.COMIC:A coherent shared memory interface for cell be[C]//Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques. New York,NY:ACM,2008:303-314.
[5]OZTURK O,KANDEMIR M,CHEN G,et al.Customized on-chip memories for embedded chip multiprocessors[C]//Proceedings of the 2005 Asia and South Pacific Design Automation Conference.New York,NY: ACM,2005:743-748.
[6]Haroon-Ur-Rashid,SHI Feng,JI Weixing,et al.Tri-BA:A novel scalable architecture for high performance parallel computing applications[C]//Proceedings of the 6th Conference on WSEAS International Conference on Applied Computer Science.Stevens Point,Wisconsin: World Scientific and Engineering Academy and Society (WSEAS),2007:396-401.
[7]AMD.AMD AthlonTM64处理器[EB/OL].[2005-03 -08].http://www.amd.com.cn/CHCN/Processors/ Product Information/0,30-118-9484,00.html.
[8] OZTURK O,KANDEMIR M.Data replication in banked DRAMs for reducing energy consumption[C]// Proceedings of the 7th International Symposium on Quality Electronic Design.Washington,DC:IEEE Computer Society,2006:551-556.
[9]刘彩霞,石峰,薛立诚,等.一种块传输多端口存储控制器:中国,200710098503.7[P/OL].[2007-10-09].http://search.sipo.gov.cn/sipo/zljs/hyjs-jieguo. jsp.
[10]HENNESSY J L,PATTERSON D A.计算机体系结构:量化研究方法[M].3版.北京:机械工业出版社,2002.
[11]Grlib-gpl-1.0.19-b3188.tar.gz[OL].[2008-09-30].http://www.gaisler.com/cms/index.php?option =com-content&task=view&id=156&Itemid=104.
[12]GUTHAUS M R,RINGENBERG J S,EMST D,et al. MiBench:A free,commercially representative embedded benchmark suite[C]//Proceedings of the 4thAnnual Workshop on Workload Characterization.Washington,DC:IEEE Computer Society,2001:3-14.
[13]Evaluating Performance and Power of Object-Oriented vs. Procedural Programming in Embedded Processors.[EB/ OL].[2008-9-19].http://www.auto.tuwien.ac. at/AE2002/Presentations/chatzigeorgion/ADA.ppt.
