基于B/S架构的Web网页结构检测应用研究
2009-05-12陈圣俭孙明涛
陈圣俭 孙明涛
摘 要:随着互联网的普及,大型的跨国公司要求公司对内对外的所有网站都遵循统一的框架结构,因此为了判断网页结构是否符合标准,需要对网页结构进行检测。Web结构分析是指从Web文档中自动分析网页结构的过程,检测不符合标准的网页。依据W3C Markup Validation Service的设计理念,基于DOM结构树和正则表达式的操作,以分析Web网页结构为基础,提出了Web页面结构检测的设计思想。在解析Html和CSS代码的基础上,网页结构检测正确率达到80%以上。
关键词:正则表达式;网页结构树;检测;文档对象模型;属性元素
中图分类号:TP311文献标识码:A
文章编号:1004 373X(2009)02 135 04
Application and Research on Web Structure Inspection Based on B/S Construction
CHEN Shengjian,SUN Mingtao
(Computer Science and Technology College,North China Electronic Power University,Beijing,102206,China)
Abstract:As the popularization of Internet,like the multinational companies,the company is asked to follow the unified guideline to all the Website,in order to judge whether the Webpage is consistent with the guideline,the Webpage′s structure is needed to inspect.Web structure′s analysis refers to the course of auto-analyzing Webpage′s structure,and inspect the page that is not with the guideline.Based on W3C Markup Validation Service,the DOM tree and regular expression,with analyzing the Webpage′s structure,the designing idea of how to inspect Webpage′s structure is brought forward.Based on the Html parse and CSS code parse,the correct rate on Web structure inspection is up to 80%.
Keywords:regular expression;web page structure tree;inspection;document object model;attribute element
0 引 言
随着网络的发展,互联网上信息量的激增,在网页上合理地布局信息的格式变得非常重要,因此Web结构的设计越来越受到开发者的重视。在一般情况下,页面的框架被大多数开发者定义为3部分(上、中、下)或者有规律的几部分,对于大型的跨国公司,他们要求位于不同国家的各个部门的所有网站都遵循统一的标准结构。根据某跨国公司中国研究院制定的网页设计标准,依据W3C的Markup Validation Service[1]设计思想,提出了Web页面结构检测系统的设计方案,分别对各部门的网站进行半自动检测,省略了人工测试的随意性,同时使开发者的设计更加规范。
1 Web页面概述
1.1 HTML简介
HTML(Hypertext Markup Language)超文本标记语言[2],被用来结构化信息,并通过浏览器表现信息设计的内容,作为构造网页的通用语言,具有简单、多样、灵活的特性。
Web上的数据大部分是以HTML的形式出现的。HTML文档由标记(TAG)和元素组成。HTML标记确定了浏览器所显示文档元素的格式,大多数HTML标记是成对出现的,它们分别用作开始标记和结束标记,HTML的结束标记与开始标记的惟一区别是多了斜杠“/”。HTML标记放在尖括号里,如 <HTML>是位于HTML文档中的第一个条目,HTML文档由标题<HEAD>和主体<BODY>两部分组成。HTML文件的基本结构为[3]:
(1) <HTML>和</HTML>是HTML文件的首标记和最后一个标记,用来表示HTML文件的开始与结束;
(2) <head>和</head>标记是第二个出现的,用来表示HTML文件的头区域;
(3) <title>和</title>标记用来表示HTML文件的标题,出现在浏览器的最顶端左上角;
(4) <body>和</body>表示文件的主题信息,也就是正文。是Web结构分析的主体部分。
可以根据HTML的属性,灵活地扩展HTML元素的能力。
1.2 DOM简介
DOM(Document Object Model) [1]是一个独立于平台和语系的接口,它是相关于文档的一系列对象列表,通过操作这些对象,可以对XML文档进行读取、遍历、修改、添加和删除操作。在DOM中最基本的对象是Node,从Node中又派生出了几种具体的节点类型。对应于XML中各种相应的节点[4]。在使用DOM加载XML文档后,在内存中形成一个节点树,也就是相应的Web结构树,由XML的标签节点形成的对象模型组成。这些对象包括相应的属性、方法,以对数据进行操作。
在DOM规范的设计思想下,HTML跟XML一样是一种树形结构的文档,<HTML>是根(Root)节点,<head>,<body>是<HTML>的子节点(Children Node),互相之间是兄弟节点(Sibling Node);<body>下面才是子节点<table>,<div>,<span>,<p>等。
所谓样本文档分析[5],就是把文档输入HTML分析器(Parser),按照文档对象模型生成一种树形结构表示。DOM 是W3C 制定的一种独立于平台和具体编程语言的API 接口标准。它提供了一个标准的对象集合用以表示HTML或XML文档及其各组成部分(即对象)之间的关系,并为存取和处理这些对象提供了标准的编程接口。
1.3 总结
虽然HTML语言具有一系列的优点,便于表达Web页面信息,但是HTML语言同样存在缺点。HTML的“标记”只是告诉浏览器软件如何显示所定义的信息,却不包含任何语义,因此由HTML语言所表述的Web页面经过浏览器分析后只适合人们浏览,不适合作为一种数据交换的方式由机器处理[4]。在此以文档对象模型为基础,构造一棵DOM树,把需要的信息在DOM树的不同层次中的路径作为信息抽取的标记,根据父子节点和兄弟节点的关系的基本原理为基础,设计了一种检测学习算法来半自动地提取并检测Web页面框架。
2 网页结构的检测
2.1 对于W3C Markup Validation Service的认识
W3C的标记验证服务,是在SGML的基础上,将待验证页面的HTML同DTD(Document Type Definition)[1]进行比较,检测HTML语法随意性的缺点,提示正确的HTML文档定义格式。这种方法可以确保页面HTML的有效性,从而使页面能够在所有的浏览器中正常的显示,同时给出开发者或相关人员有针对性的提示。
2.2 Web结构检测的设计思想
根据网页的URL,利用基于HTTP协议的WebRequest,WebResponse[6]类操作,可以获取页面对应的HTML和CSS源代码的字符流,根据W3C的标记验证服务对网页代码进行相应的检测,并且纠正其中的错误,然后将源代码构造成DOM树;根据制定的检测标准(主要是网页框架的限制标准值),提取源代码中对应的属性值,再者根据兄弟节点和父子节点之间的联系,分析原始网页的框架,从而匹配该网页是否符合给定的标准;对于符合标准的框架给出其准确值,对于不符合标准的框架则予以提示,并要求纠正。具体的流程图如图1所示。
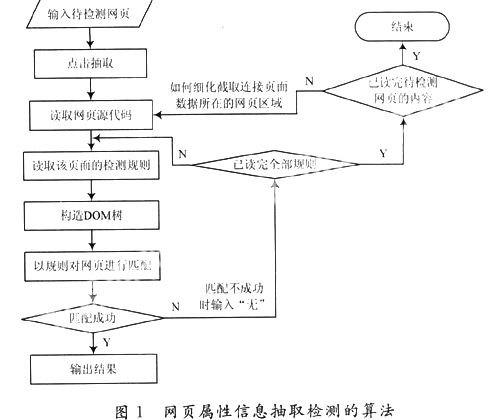
2.3 源代码的过滤体系
为了使页面源代码形成的DOM树的结构更加清晰,首先应清理源代码中的空格信息、注释信息以及页面内容信息和多余的操作信息。
对于空格信息和Js信息可以利用正则表达式快速、精确的清除或者替换(部分空格要保留,用作结束标识位);对于注释信息可以利用字符串匹配的判断规则,清除<!-- --!>之间的内容;<style>的内容应利用正则表达式快速取出,同CSS文件相似,需要获取color,font以及页面框架涉及到的宽、高等信息;对于tag标签内的style属性值,可以在Dom树构造完成后,直接获取。
2.4 网页结构树的构造算法
在构造DOM树的过程中,可以利用HTML页面的Tag的Element特征,采用标记匹配和回溯相结合的方法构造Web文档结构树[7]。这是因为大多数HTML标记是成对出现的,在起始标记和结束标记之间,包括网页描述属性信息和网页内容信息,如<td width = "393"><fontcolor="# 666666"><img src="" width="393"></font></td>。在起始标记<td>和结束标记</td>之间的width ="393"><font color="#666666"><img src="" width="393"></font>是属性信息,<img src="" width="393">是内容信息。在构造文档结构树时,需要对Tag标记进行分析,并将属性作为节点信息。由于HTML的随意性,它的规范性差,所以在对代码进行清理后,还要对剩余代码进行规范化整理,比较实用的Tidy工具即可实现该功能。如果主要是对框架内容的抽取,则需要考虑HTML的标记主要有<STYLE>,<STYLE>,<BODY>,</BODY>,<TABLE>,</TABLE>,<DIV>,</DIV>,<TR>,</TR>,<TD>,</TD>,<A>,</A>,<IMG>。对于其他的HTML标记可视为无用HTML标记,在程序处理中将忽略对这些标记的处理。网页文档结构树的每个结点对应1个Tag标记,因此构建DOM树的前提条件是正确地读取标记,分析开始标记、结束标记和没有得到匹配的标记。结点对应的Tag开始与结束标记之间的内容存在Tag Node类中[8]。
2.5 网页代码检测的过程
根据检测需要,筛选tag标签信息,保留tag标记和element元素。在构造过程中,借鉴HtmlParser[9]的设计思想,过滤HTML中的tag标签,将<HTML></HTML>之间的部分tag标签构造成DOM树;这种构造DOM树的算法,在读取过程中可能产生部分重复,因此应该进一步优化。具体的算法设计为:
(1) 读入获取到的字符流源文件,设置状态机;
① 判断第1个字符是否是“<”,如果是,则可能是标签入口,需要取下1个字符确认;
② 如果不是,设置状态机开始解析一个Node,如果是“<”,继续读取下一字符;
③ 根据</HTML>判断是否到达页尾,如果是则产生一个Node返回;
④ 如果读取到“%”,则说明是JSP(Java Server Page) [10]标签,进入JSP状态机去解析;
⑤ 如果读取到“?”,则说明是XML标签,进入XML状态机去解析;
⑥ 如果读取到“/”或任何字符,说明是Tag标签,进入Tag标签状态机去解析;
⑦ 如果读取到“!”,则说明进入一个注释标签,需要再读取一个字符,如果到页尾,则产生一个Node返回,如果字符为”>”则生成一个Remark Node返回,否则,回溯一个字符,再判断字符如果是“-“则回溯一个字符,进入Remark状态机去解析,如果不是,则回退一个字符进入Tag状态机去解析。
(2) 当进入Tag标签状态机后,开始Tag标签的解析:
① 如何读取到“<body”,则将body插入队列,以body为父节点开始构造树;
② 如果遇到“<table”,则将table作为body的第一个孩子节点插入到树中;
③ 继续读取,如果遇到“<tr”,则将tr作为table的第一个孩子节点插入到树中;
④ 如果遇到“table”,则将table作为body的第二个孩子节点(前一个table的右兄弟节点插入树中);
⑤ 继续读取,如果遇到“td”,则将td作为tr的第一个孩子节点插入树中;
⑥ 如果遇到“<tr”,则将其作为tr的兄弟节点,table的孩子节点插入树中;
⑦ 继续读取,如果是“td”,则将其作为td的兄弟节点(tr的孩子节点)插入树中。
以此递归,直到遇到“</”,表示每一节点的结束,“</body>”整棵DOM树建立完毕。DOM树结构可用图2表示。
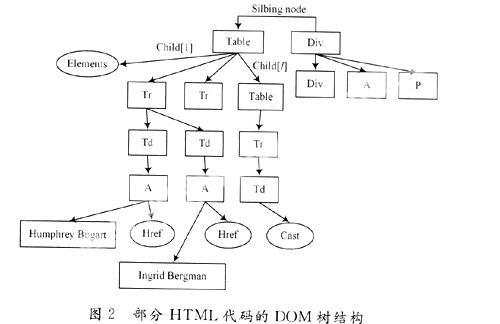
2.6 网页结构的检测
具体的匹配检测需要根据实际的标准页面结构,利用HTML中的兄弟节点和父子节点的关系,由兄弟节点确定页面的各个子框架结构,然后再根据子框架下的兄弟节点和父子节点的属性值(例如width,height等)判断该框架是否符合给定的标准。
例如在检测页面时,首先取定body的子节点的个数,如果等于1,则判断其子节点的孩子节点,从而判断出页面的布局。可以利用如下代码:其中parserCompare()函数为将获取到的值与标准值进行匹配的函数,利用递归操作,分析各个部分的框架。
if(node.Children!=null&&node.Children.Count;>0)
{
parserLogoCompare(node.FirstChild);
start.Add(tag.StartPosition);
}
INode siBlingNode = tag.NextSibling;
while (siBlingNode != null)
{
parserCompare(siBlingNode);
paserData(siBlingNode);
siBlingNode = siBlingNode.NextSibling;
}
将网页的各部分框架分析出来后,取得各部分对应的color和font等的值,对于<style>和<div>中的css信息,通过正则表达式获取style信息;然后分析字符串,得到相应的命名;再结合标准库中的color,font 等标准值,匹配并检测得到相关信息。
根据制定的标准以及DTD的规定,将不同的提示信息绑定到页面显示中,将不同的审核数据绑定不同的颜色。这样,用户在输入网址之后,就可以得到页面结构的相关信息,根据公
司内部标准规范设计。
3 结 语
参照W3C Markup Validation Service分析HTML的规范性检测方式,分析并检测网页结构是否符合开发者制定的标准,对于不同开发者在同一模板下开发的规范性做出检测。其中引入DOM树结构中的路径表达式来定位HTML文档中要分析的属性,在分析页面结构的同时,可以利用关键字提取页面的内容信息,以及获取链接页面的各种信息,同时实现信息提取和Web检测。
参考文献
[1]W3C.Markup Validation Service.http://validator.w3.org/,2007.
[2]Lauren W,Arnaud LH,Vidur A,et al.Document Object Model(DOM) Level 1 Specification[EB/OL].http://www.w3.org/TR/REC2DOM2Level21,1998,10(4).
[3]王建.Web建站标准.北京:人民邮电出版社,2007.
[4]侯彦娥,蒲宝明.基于.NET的Web应用系统通用平台中构件技术研究.沈阳:中国科学院沈阳计算技术研究所,2006.
[5]李效东.基于DOM 的Web信息提取.计算机学报,2002,25(5):526-533.
[6]Simon Robinson,K Scott Allen.C#高级编程.北京:清华大学出版社,2002.
[7]袁宇丽,左志宏.基于HTML的Web信息提取研究.成都:电子科技大学,2006.
[8]陈琼,苏文健.基于网页结构树的Web信息抽取方法.计算机工程,2005,31(20):54-55,140.
[9]王琳琳,刘知青.基于HtmlParser的Web信息提取技术.北京:北京邮电大学,2007.
[10]JavaServer Pages Technology.http://www.javasoft.com/products/jsp,SDN,2007.
作者简介
陈圣俭 男,1966年出生,博士后,教授,博士生导师。主要研究方向为计算机测控技术。
孙明涛 男,1983年出生,硕士研究生。主要研究方向为计算机测控技术。
