探讨分布式内存数据库的设计与应用
2009-03-30张晓伟
张晓伟
[摘要]数据库系统本质上是一个用计算机存储记录的系统。作为数据库的一个分支,内存数据库能为实时性提供保障。针对内存数据库的二维表、索引数据、单,向资源进行详细的设计,并实现内存数据库在应用过程中的数据同步及并发性应用。
[关键词]内存数据库数据同步分布式系统
中图分类号:TP3文献标识码:A文章编号:1671—7597(2009)0210016--02
一、引言
内存数据库系统是基于电话交换系统的。与传统的外存数据库相比,内存数据库的最大特点是数据长期驻留于主存,作为主拷贝,而硬盘上的备份只用于转存与恢复。所有对数据关系的检索全部在内存完成,为实时性提供最大保障。同样,由于数据长期驻留在内存中,数据组织方式、索引方式和操作序列化方式也是按照内存的特点做优化。
作为数据库的一个分支,内存数据库系统也支持当前流行的大型数据库系统的一些流行设计思想,如数据字典(Data Dictionary)、光标操作(Cursor)、保持数据完整性、一致性的触发器(Trigger)、虚删除(softDelete)[1]。又由于内存数据库系统通常都是多模块系统,所以相应的要求内存数据库具有一定的分布式数据库的能力,完成分布式的资源管理。
二、内存数据库的设计
(一)二维表对象
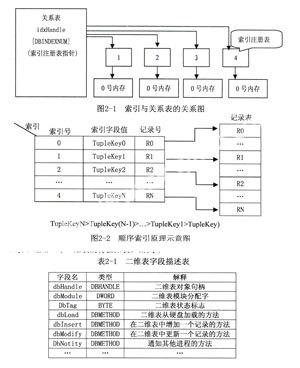
一个二维表是一个具体的二元关系。二维表的每一行称为表的元组(Tuple)或记录(Record),每一列称为表的域(Domain)或字段(Field)。二维表中能确定唯一一条记录的记录字段集构成二维表的关键字(Key),一个二维表的关键字可能有多个,其中的一个称为二维表的主关键字(Primarykey)。通常一个二维表的特征如表2-1所示:
表2-1中的描述内容包含两部分:对象属性和对象方法。对象的属性描述了对象的基本特征,所有该对象的实例均具有这些特征。对象的方法规定了操纵对象实例的几个基本方法,这些方法可能随着二维表对象实例的不同而不同,因此,在设计对象方法时需要能够在需要时重定义对象的方法,支持对象方法的重定义是内存数据库系统设计的一个重要方面。
而索引对象和队列对象都是建立在二维表对象基础上的。一个具体的二维表对象实例在运行之前必须在系统注册登记才能被系统识别。注册定义一个具体的二维表的方法步骤如下,其中[]为可选部分,对于有些二维表不需要索引或队列管理:注册一个空表;在所注册的空表中逐个增加字段;提供为所有二维表对象预定义的若干方法;为二维表建立存储区;[注册二维表的索引对象];[为索引建立存储区];[注册队列对象]:[为队列建立存储区]。
(二)索引数据在内存中的表示
索引定义有两类:顺序索引、HASH索引[2]。对于顺序索引,索引表的每个索引项由“索引关键字和索引记录号”两部分组成,索引表的索引项按“索引关键字”有序排列,如图2-1所示,采用二分法检索。在本系统中主要采用顺序索引。
索引是给这些需要经常查找的字段维护一张索引表,索引表中的记录有字段值(或者是字段值经过映射的信息)信息和相应记录的位置(记录号),字段值(或者是字段值经过映射的信息)作为索引记录表的关键字。于是查找记录可以通过先查找索引表获得记录号,然后就可以从表中获得记录。顺序索引原理如图2-2所示:
(三)表对象中单向资源队列的处理
单向资源队列在关系表中用于维护二维表数据区中空闲的内存块信息。为此,在二维表对象中称其为空闲队列。此外,它还作为同步对象中的失步队列用于记录失步记录。单向资源队列对象是供表对象和同步对象内部使用的对象。单向资源队列根据它在表对象和同步对象作用分别又称为单向资源队列对象和失步记录队列对象。表对象管理大量的记录,这些一记录是存放在一个记录数组中的,当其中某些记录删除之后,存放相应记录的内存就会空闲出来,当要向表插入记录时,就需要知道那块内存是空的,如果一个一个找显然降低处理速度,为此就需要维护一个单向资源队列,记录空闲内存的位置[3]。在表对象中与单向资源队列相关的操作的关键的有两个:
1、当向表实例中插入记录时,首先要删除单向资源队列队尾元素,然后获得空闲内存位置,再在该内存位置上写入记录内存。
2、当从表实例删除记录之后,要将给内存位置信息插入该单向资源队列,以使该队列记录空闲内存位置。
此外,在表创建一个空闲对象实例并初始化该队列和在表实例撤销时,同时撤销该队列也是不可缺少的。
三、内存数据库的应用
(一)数据同步的流程
当系统业务调用和后台数据配置变化时,主数据库中的内容发生变化,同时将变化写入对应表的映象区中,当实时同步进程启动时,在传输控制数据区的控制,读取映象区中的消息,将记录打包发往传输层。接受端数据库,接受到数据后解包,检查数据并更新记录,如果成功,返回成功消息,发送端传输下一包;如果不成功,返回失败消息,发送端继续传输此包。如果在指定时间内,未有消息返回,也认为是不成功。具体步骤如下:
1、初始化数据库的映象区,传输数据控制区;
2、主数据库发生变化时,将变化表的变化记录号写入相应表的队列,并在相应映象区描述对应的变化:
3、当定时周期到时,启动实时同步进程,将记录打包发送到接受端数据库,同时将映象区和队列中的相应记录删除:
4、接受端数据库接受数据,并更新相应表记录,返回应答消息;
5、收到同步确认后,继续同步其他数据,如收到同步失败或在指定时间内未收到响应消息,则可以重传一定次数;
6、若在指定次数内,重复3-5,直到同步结束,则等待下次时间周期,开始同步。
若未同步完成,因为持续同步而可能影响其他操作的执行也要停止同步,在下一次同步启动时从当前记录处开始同步。
(二)内存数据库的并发性
数据库将面对成百上千个用户,这样必然存在多个用户并发地存取同一个数据库的情况。在这种情况下,由于相互间的干扰,可能会产生错误的总体结果。本文采取的做法是在分布式的内存数据系统中采取一定的并发控制机制,使得一个事务的执行不受其它事务的干扰,从而避免并发事务造成实据的不一致。本文的调度策略是:基于优先级任务的抢占式调度和基于时间片轮转进程的顺序调度。并发性控制只要保证不同的事务串行执行;0s在同一个任务内的进程将被顺序调度;除非自动放弃CPU控制权(通过显式调用OS原语)[4]。只要保证对数据库的直接访问的进程全部在同一个任务中,那么就有效地解决了数据库访问的并发性问题。
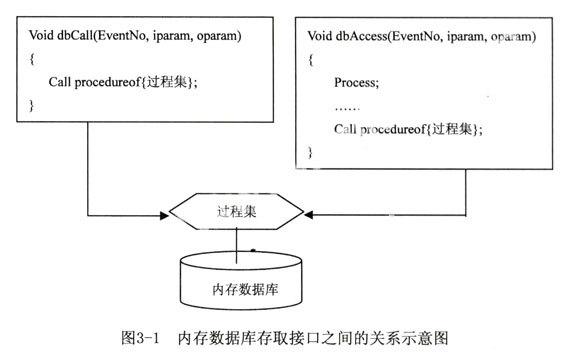
首先,所有数据的存取有一个过程集实现,过程集中的若干过程依序组合完成一个事务,由于任务之间存在优先级的任务抢占问题,即使优先级相同也存在按时间片轮转的问题。这些问题都直接要求任务的进程在存取数据时不能直接调用过程集中的过程,而只能将事务交给任务的进程来完成这个事务。采用这个方式既保证处理的实时性,又将事务串行化保证事务处理的完整性而没有增加额外的开销。对于处理任务的进程使用void dbCall(WORDl6EventNo,LPSTR iParam,LPSTR oParam)存取数据,对于其它任务的进程使用void dbAccess(WORDl6 EventNo,LPSTR iParam,LPSTR oParam)存取数据。前者是一个纯粹的过程调用,后者形式上是一个过程调用,其内部实现是采用了进程通信,保证事务的执行在任务中完成,如图3-1所示。
四、小结
本文所研究的内存数据库为每一种对象提供的方法都可以为其继承者所使用,且该继承者可以是另一种对象。由该对象说明的各个数据实例,都可以共用这些方法(如插入、删除、查询等方法),这大大地提高了代码的使用效率及减少了具体数据实例的创建工作量。每一种由对象声明的数据实例,可以通过重载修改其某些方法的执行特性,这种表现称为多态性。多态性为数据实例的方法更新与扩展打开了方便之门。
总之,内存数据库内各种数据的描述是采用关系型数据模式,采用面向对象的数据库设计方法将存储信息的表有效地封装起来,访问者只有通过对象提供的基本方法才能接触到数据的存储实体,这有效地保证了数据存储实体的安全性。
